Flink版本: 1.8.0
Scala版本: 2.11
Github地址:https://github.com/shirukai/flink-examples-debug-state.git
在本地开发带状态的Flink任务时,经常会遇到这样的问题,需要验证状态是否生效?以及重启应用之后,状态里的数据能否从checkpoint的恢复?首先要明确的是,Flink重启时不会自动加载状态,需要我们手动指定checkpoint路径。笔者从Spark的Structured Streaming转到Flink的时候,就遇到这样的问题。在Spark中,我们使用的状态信息会随着程序再次启动时自动被加载出来。所以当时以为Flink状态也会被自动加载,在开发有状态算子时,测试重启应用之后,并没有继续上一次的状态。一开始以为是checkpoint的设置的问题,调试了好长时间,发现flink需要手动指定checkpoint路径。本篇文章,将从搭建项目到编写带状态的任务,介绍如何在IDEA中调试local模式下带状态的flink任务。
注意:后期git上的项目名称从debug-flink-state-example改为flink-examples-debug-state
1 基于官方模板快速创建Flink项目
Flink提供了Meven模板,能够帮助我们快速创建Maven项目。执行如下命令快速创建一个flink项目:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.8.0 -DgroupId=flink.examples -DartifactId=flink-examples-debug-state -Dversion=1.0 -Dpackage=flink.debug.state.example -DinteractiveMode=false
项目创建完成后,使用IDEA打开项目。
对pom.xml稍微做一下修改。
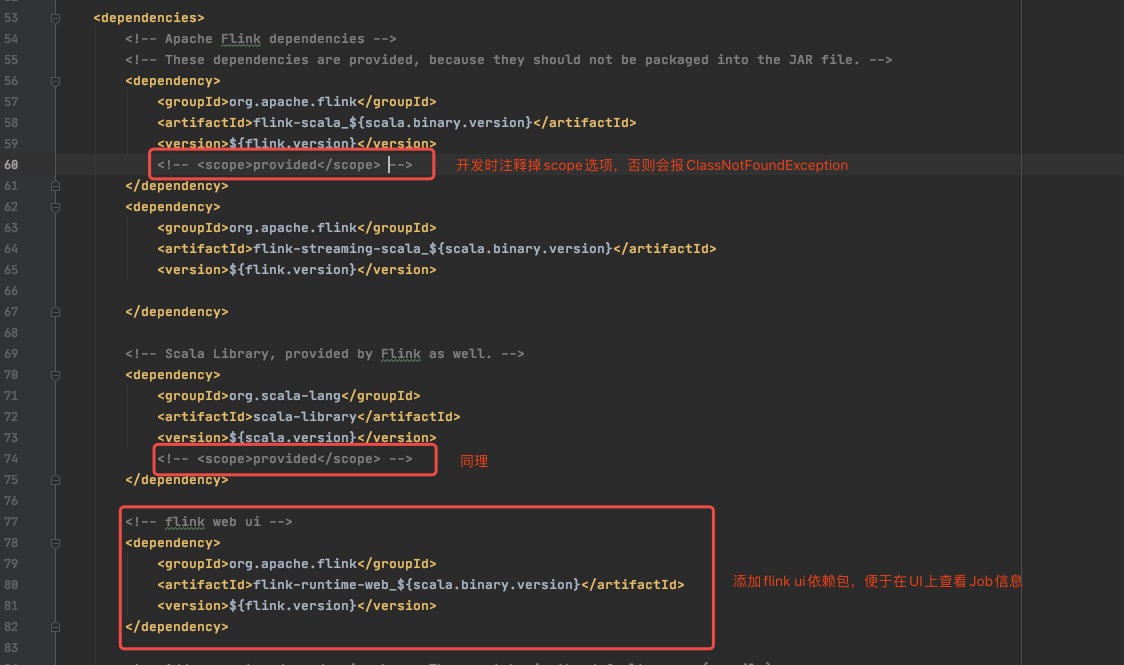
纠正一下上面这个问题,flink的两个包作用域都设置为了provided,在程序执行时汇报类不存在的异常。我们可以注释掉scope作用域,也可以在Maven里勾选带有flink依赖的Profiles。
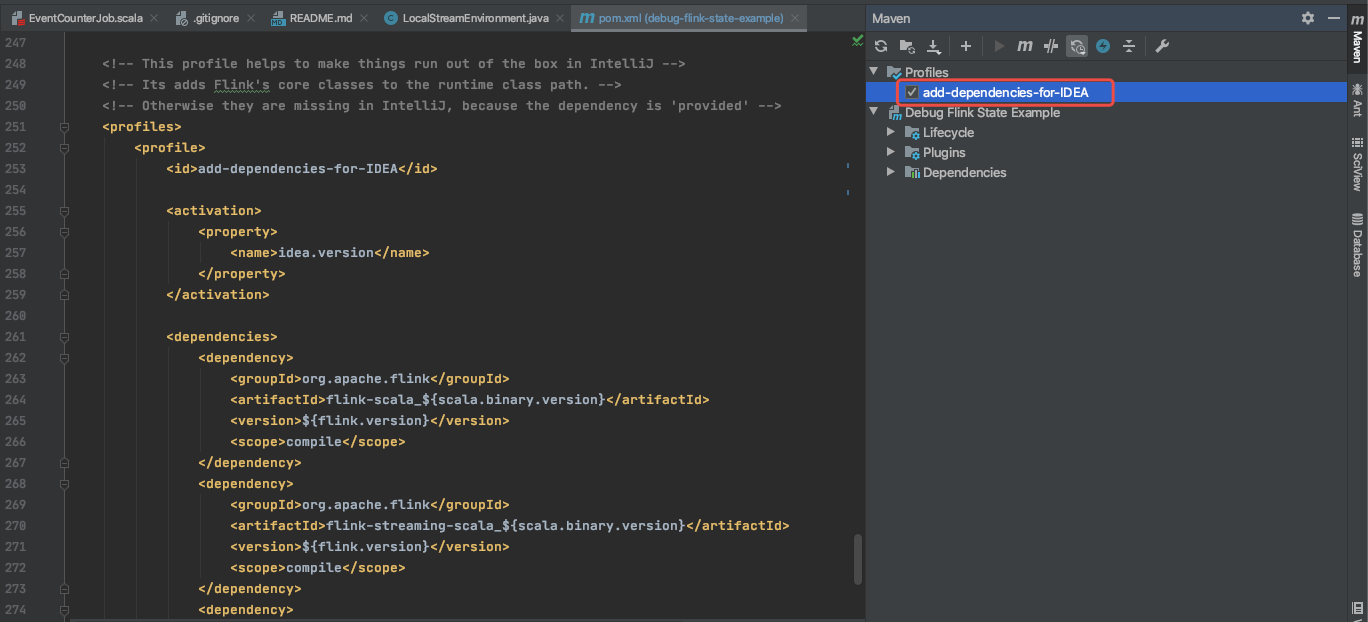
2 编写一个有状态简单任务
这里我们编写一个简单的Flink任务,实现功能如下
- 从SocketTextStream中实时接收文本内容
- 将接收到文本转换为事件样例类,事件样例类包含三个字段id、value、time
- 事件按照id进行KeyBy之后,使用process function统计每种事件的个数和value值的总和
- 控制台输出统计结果
逻辑比较简单,直接贴代码吧。
package debug.flink.state.example
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.util.Collector
/**
* 实时计算事件总个数,以及value总和
*
* @author shirukai
*/
object EventCounterJob {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 1. 从socket中接收文本数据
val streamText: DataStream[String] = env.socketTextStream("127.0.0.1", 9000)
// 2. 将文本内容按照空格分割转换为事件样例类
val events = streamText.map(s => {
val tokens = s.split(" ")
Event(tokens(0), tokens(1).toDouble, tokens(2).toLong)
})
// 3. 按照时间id分区,然后进行聚合统计
val counterResult = events.keyBy(_.id).process(new EventCounterProcessFunction)
// 4. 结果输出到控制台
counterResult.print()
env.execute("EventCounterJob")
}
}
/**
* 定义事件样例类
*
* @param id 事件类型id
* @param value 事件值
* @param time 事件时间
*/
case class Event(id: String, value: Double, time: Long)
/**
* 定义事件统计器样例类
*
* @param id 事件类型id
* @param sum 事件值总和
* @param count 事件个数
*/
case class EventCounter(id: String, var sum: Double, var count: Int)
/**
* 继承KeyedProcessFunction实现事件统计
*/
class EventCounterProcessFunction extends KeyedProcessFunction[String, Event, EventCounter] {
private var counterState: ValueState[EventCounter] = _
override def open(parameters: Configuration): Unit = {
super.open(parameters)
// 从flink上下文中获取状态
counterState = getRuntimeContext.getState(new ValueStateDescriptor[EventCounter]("event-counter", classOf[EventCounter]))
}
override def processElement(i: Event,
context: KeyedProcessFunction[String, Event, EventCounter]#Context,
collector: Collector[EventCounter]): Unit = {
// 从状态中获取统计器,如果统计器不存在给定一个初始值
val counter = Option(counterState.value()).getOrElse(EventCounter(i.id, 0.0, 0))
// 统计聚合
counter.count += 1
counter.sum += i.value
// 发送结果到下游
collector.collect(counter)
// 保存状态
counterState.update(counter)
}
}
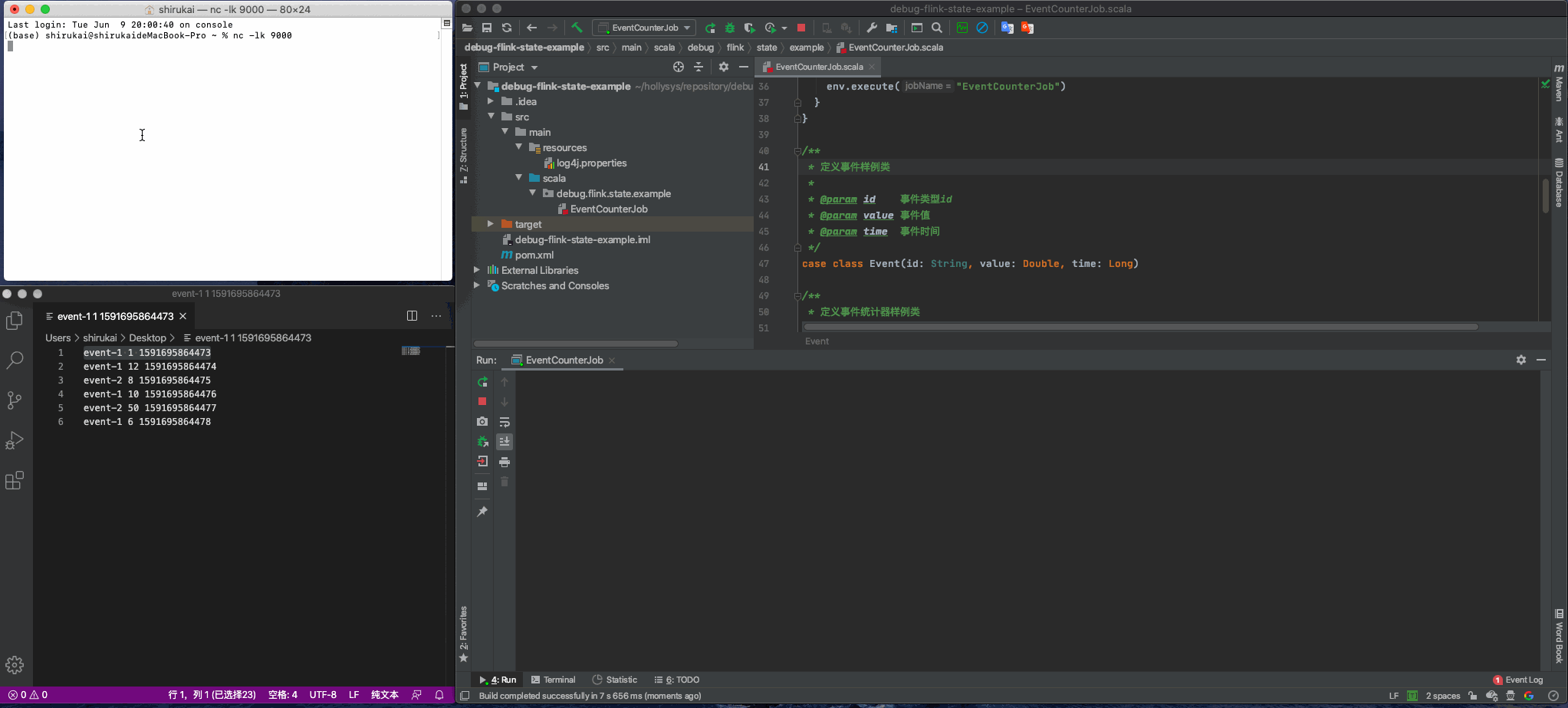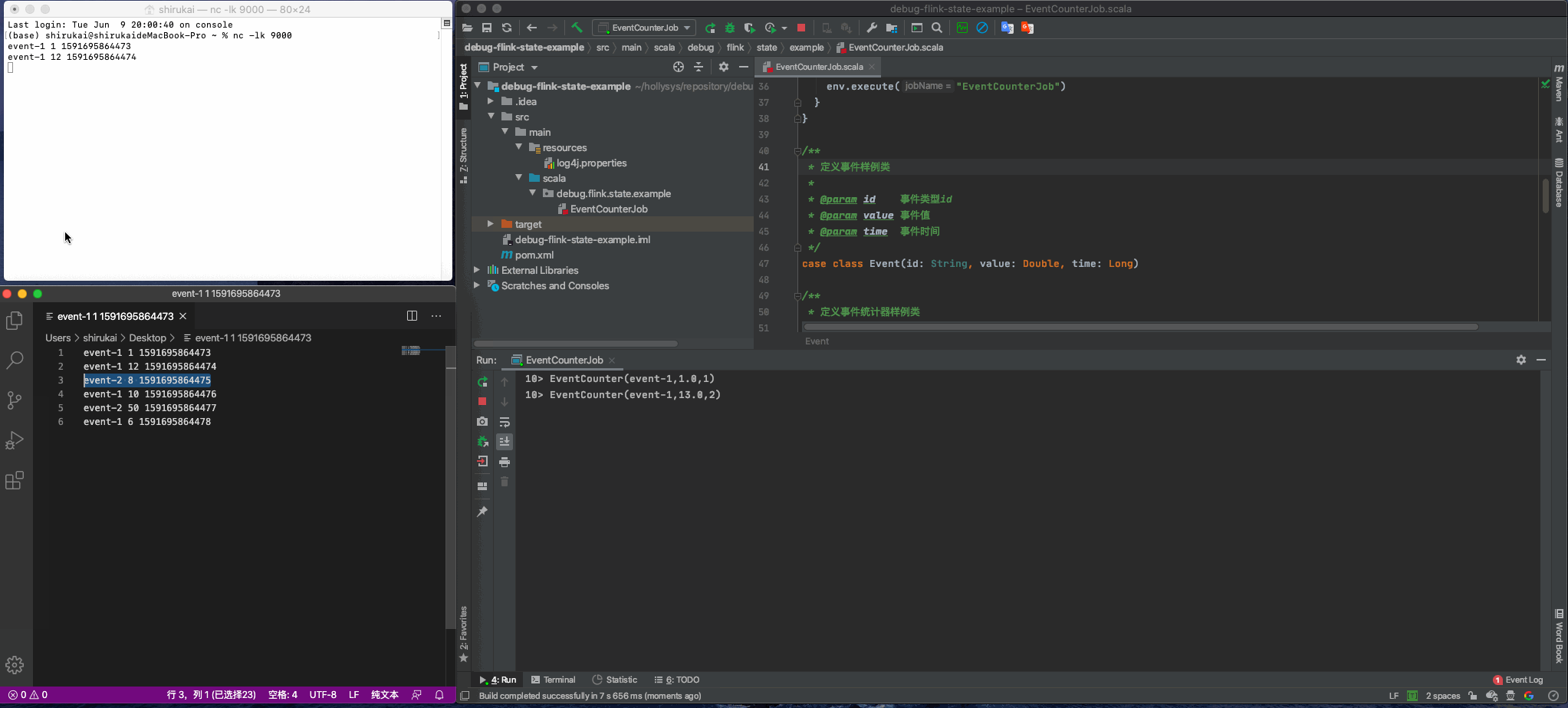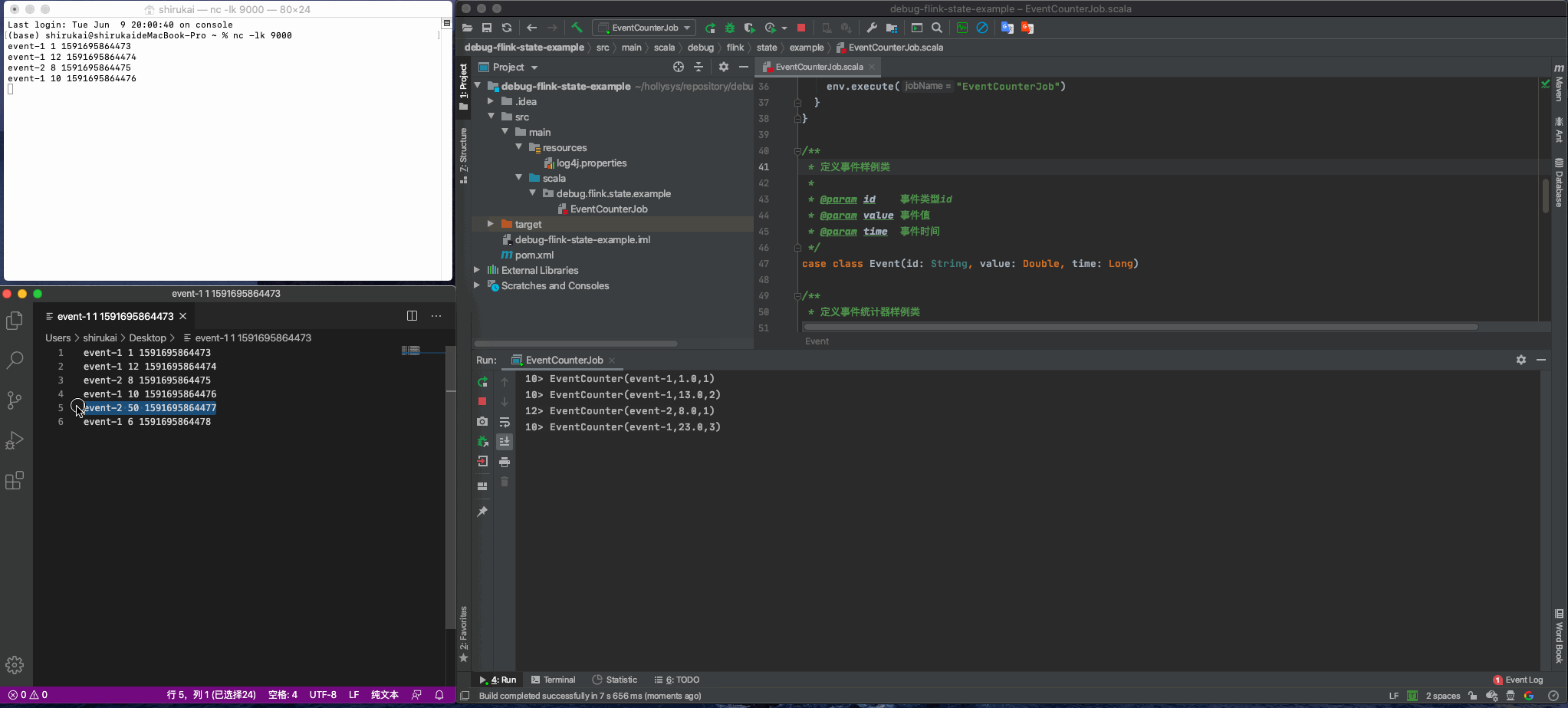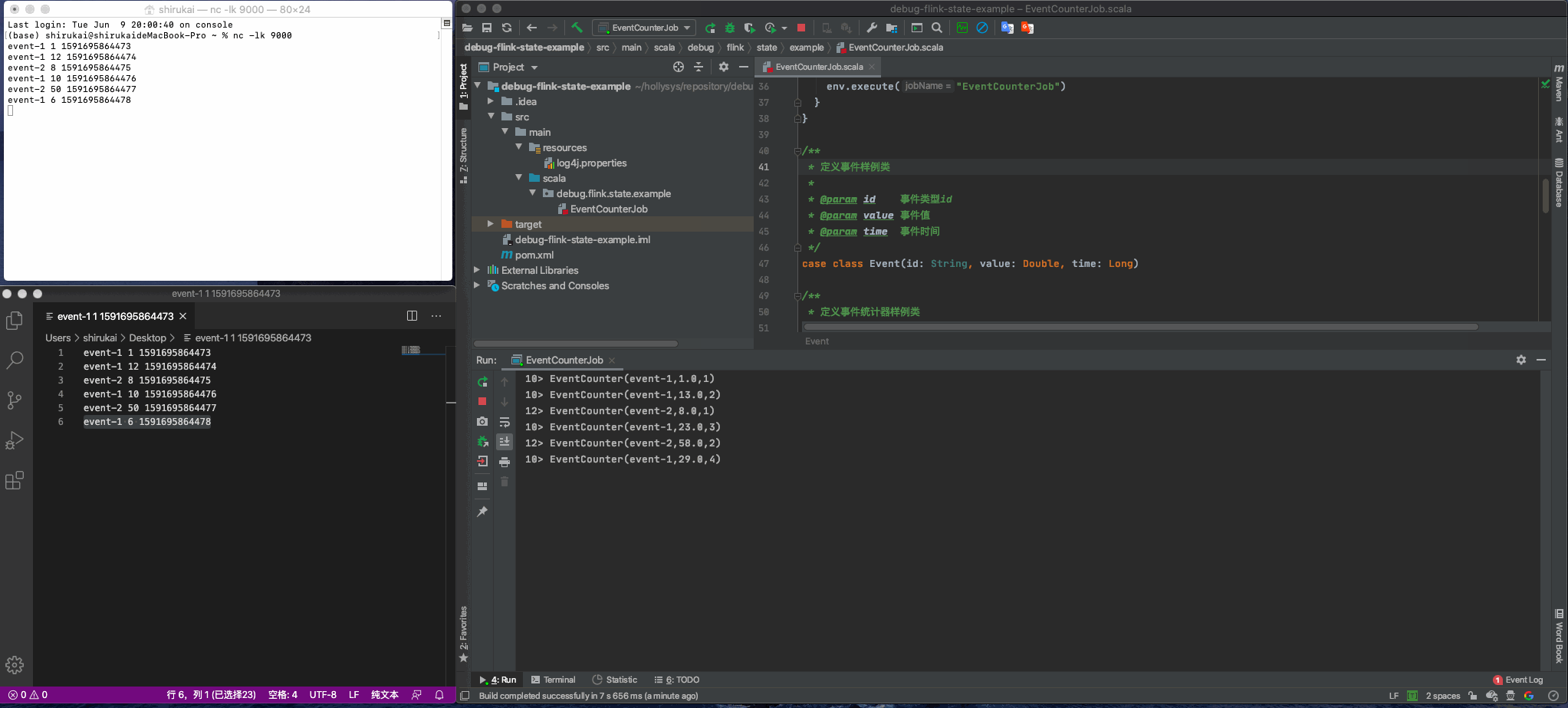
使用nc命令监听9000端口
nl -lk 9000
启动flink任务,并模拟如下数据发送
event-1 1 1591695864473
event-1 12 1591695864474
event-2 8 1591695864475
event-1 10 1591695864476
event-2 50 1591695864477
event-1 6 1591695864478
效果如下动图所示:
3 配置Checkpoint
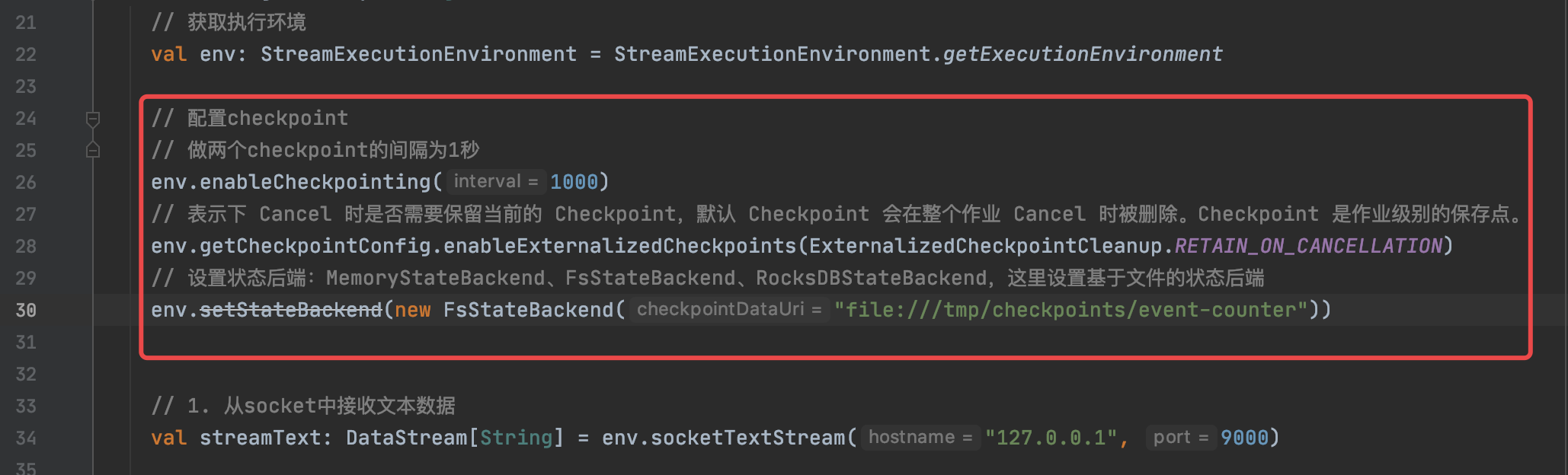
上一步我们已经编写了一个有状态的简单任务,但是状态并没有被持久化,程序重启之后状态会丢失。这时候我们需要给flink任务配置checkpoint。需要简单配置3个地方:
- 开启checkpoint,并设置做两个checkpoint的间隔
- 设置取消任务时自动保存checkpoint
- 设置基于文件的状态后端
// 配置checkpoint
// 做两个checkpoint的间隔为1秒
env.enableCheckpointing(1000)
// 表示下 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint 会在整个作业 Cancel 时被删除。Checkpoint 是作业级别的保存点。
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// 设置状态后端:MemoryStateBackend、FsStateBackend、RocksDBStateBackend,这里设置基于文件的状态后端
env.setStateBackend(new FsStateBackend("file:///tmp/checkpoints/event-counter"))
启动程序,同样模拟数据发送。
这次先发送前三条数据
event-1 1 1591695864473
event-1 12 1591695864474
event-2 8 1591695864475
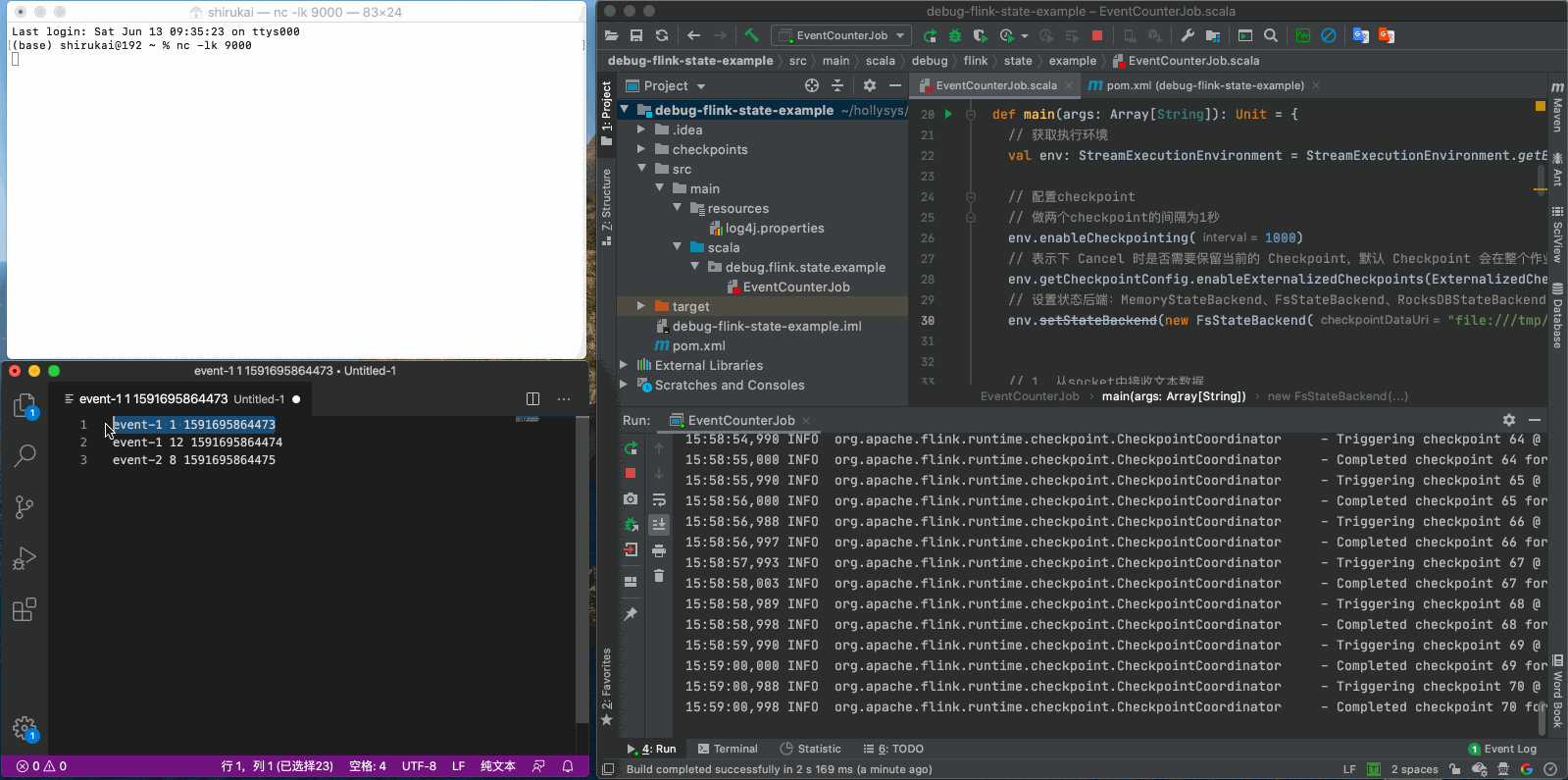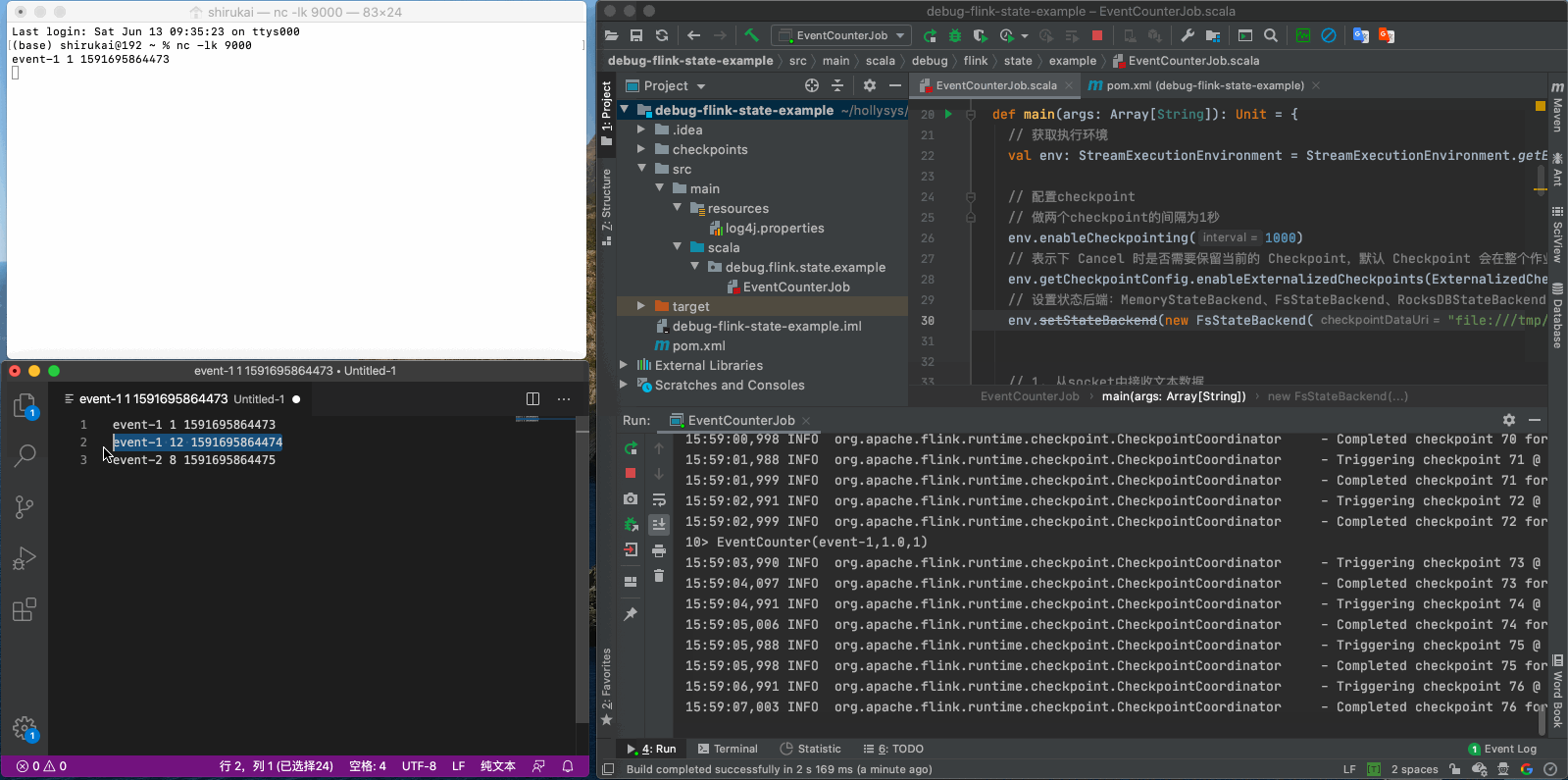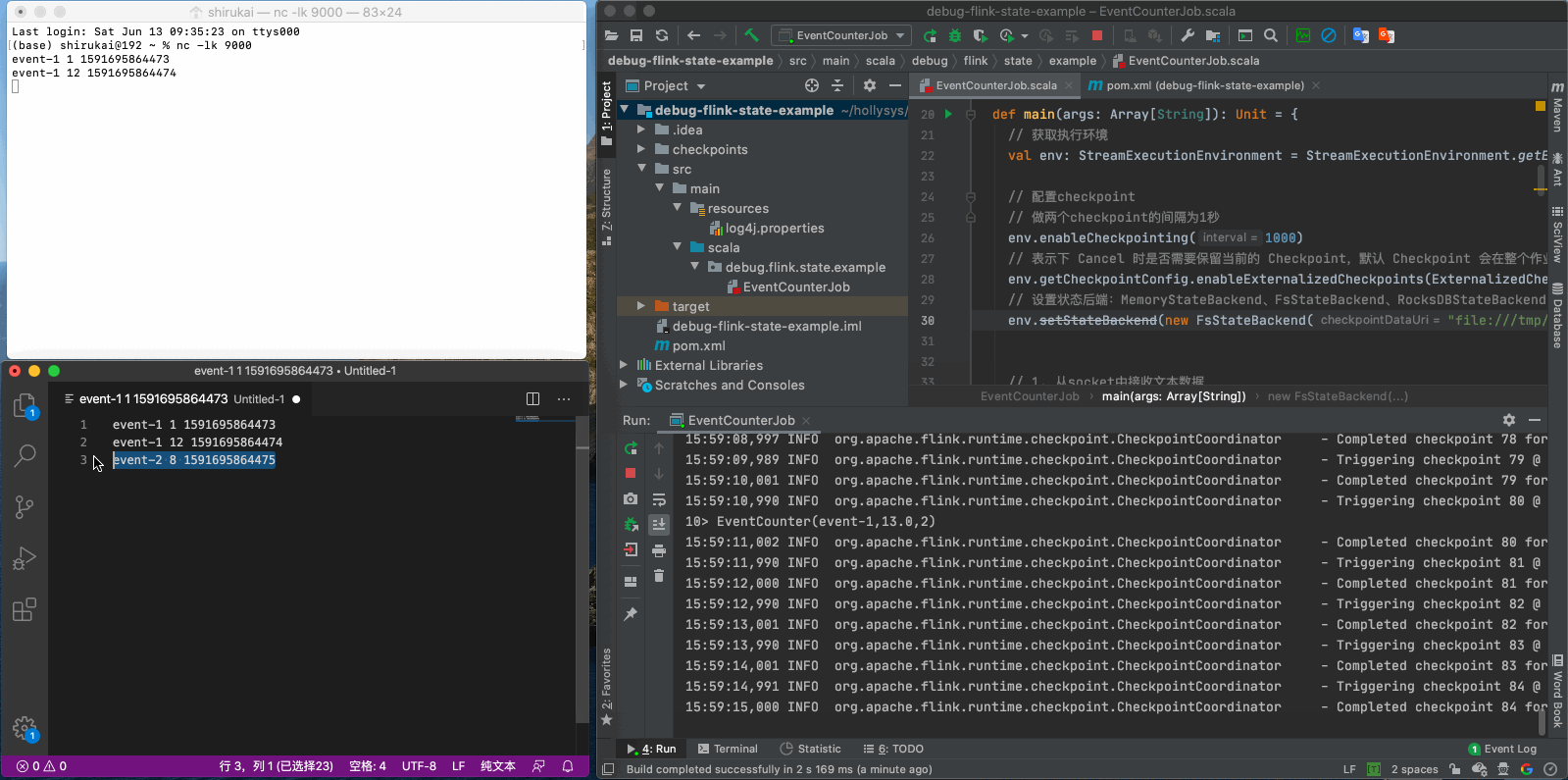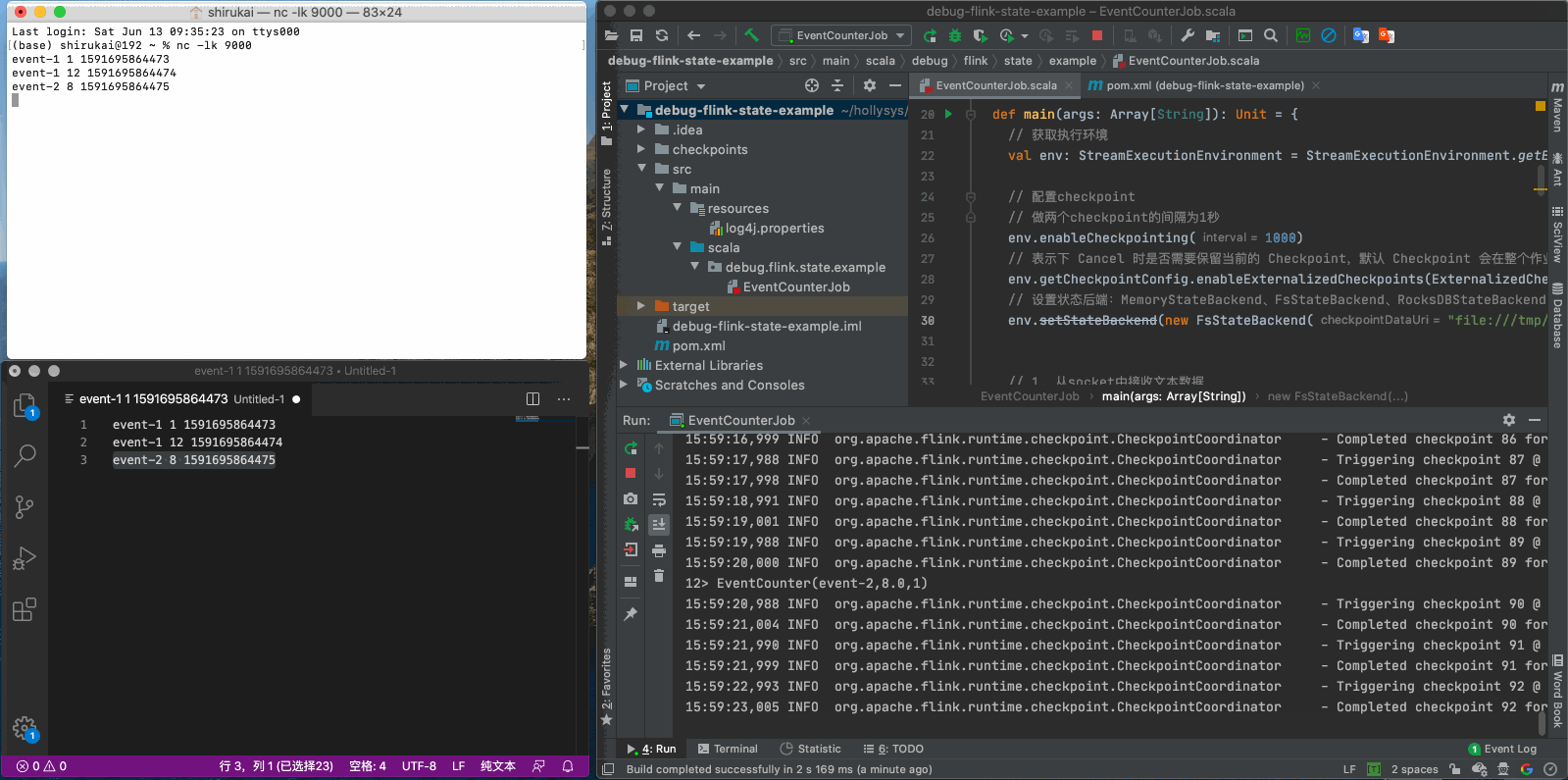
从以上动图中的日志可以看出,flink每隔一秒都会在做checkpoint。
15:59:32,989 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 102 @ 1592035172989 for job 0c3d201188fc9953cb65498adb4954f4.
15:59:32,997 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 102 for job 0c3d201188fc9953cb65498adb4954f4 (21340 bytes in 7 ms).
15:59:33,990 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 103 @ 1592035173989 for job 0c3d201188fc9953cb65498adb4954f4.
15:59:34,001 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 103 for job 0c3d201188fc9953cb65498adb4954f4 (21340 bytes in 11 ms).
15:59:34,989 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Triggering checkpoint 104 @ 1592035174989 for job 0c3d201188fc9953cb65498adb4954f4.
15:59:35,006 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Completed checkpoint 104 for job 0c3d201188fc9953cb65498adb4954f4 (21340 bytes in 15 ms).
查看checkpoint 的目录,发现有checkpoint生成。
ls /tmp/checkpoints/event-counter
这里简单说明一下checkpoint目录,程序每次启动都会在指定的目录下(如/tmp/checkpoints/event-counter)根据id生成一个目录,该目录会包含三个目录chk-*、shared、taskowned,每秒做的状态会报存在chk-*目录下,整体目录结构如下所示:
/tmp/checkpoints
└── event-counter
└── 0c3d201188fc9953cb65498adb4954f4
├── chk-104
│ ├── 01f2561f-ca48-4699-bbea-40fc849b2b0f
│ ├── 021a7b75-f034-4da3-ad0c-e9801a8f1141
│ ├── 17fcf354-c212-43ec-8e7c-99e37a7653c9
│ ├── 33af50a1-e2cb-4364-a723-4c182c5fdb47
│ ├── 3fa88dc7-ea81-4735-83ba-3d4630b7b8ac
│ ├── 792068d4-2f89-4d21-aa27-88ef61c7fa99
│ ├── 793d349b-8029-4cb6-b522-22445ec19bae
│ ├── _metadata
│ ├── acd28b9b-a0cb-4880-9564-9b9fe3c29200
│ ├── c7cbb990-917a-400d-9838-1ac28c92ea10
│ ├── e202ca66-5f9e-4858-bf15-02ca17a4e2b1
│ ├── e7370373-c4be-4c7c-b6df-d959127b31a3
│ └── eb619830-b102-4449-a29c-59d82b6bfbfe
├── shared
└── taskowned
重启程序之后再发送后三条数据
event-1 10 1591695864476
event-2 50 1591695864477
event-1 6 1591695864478
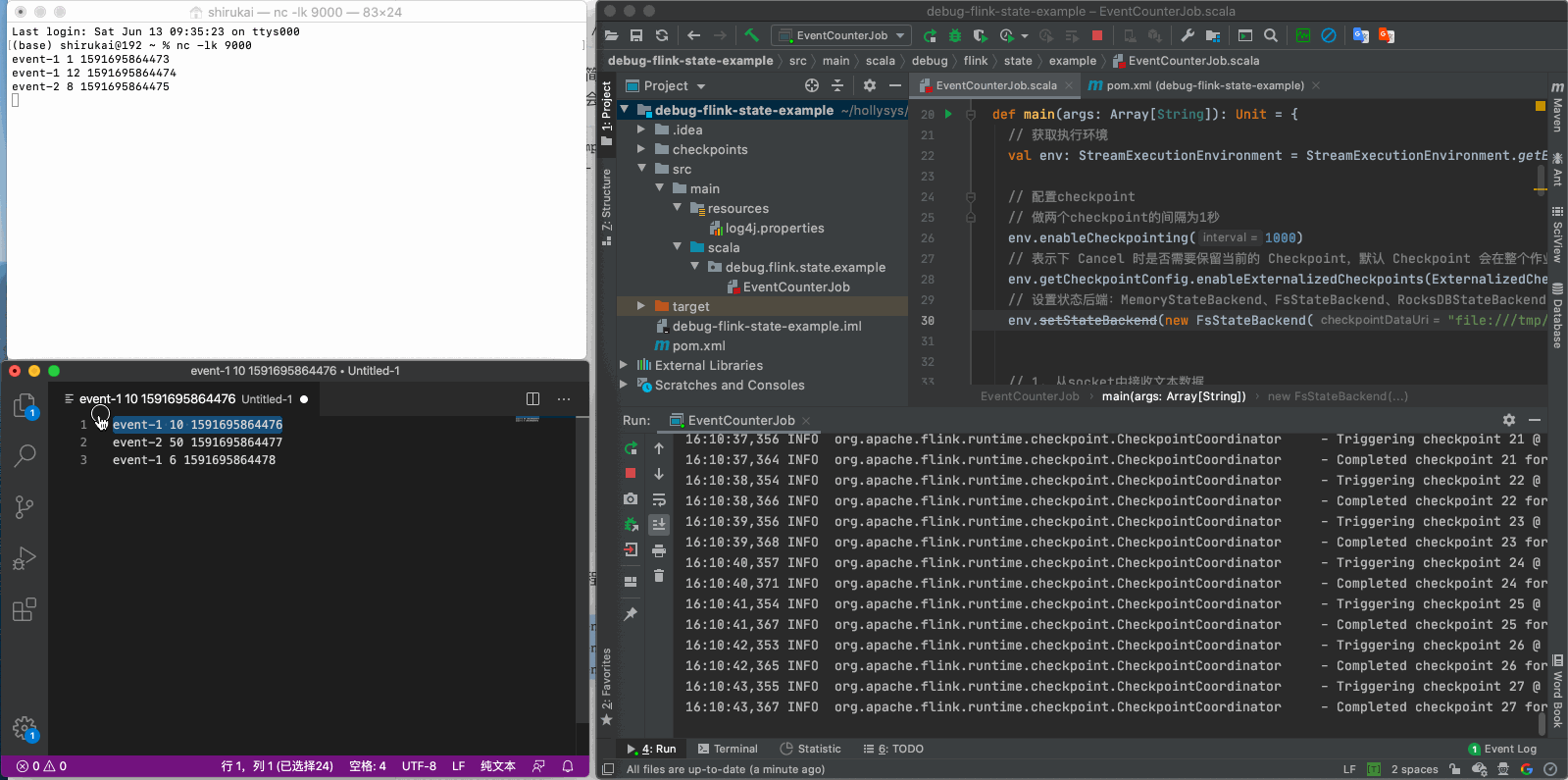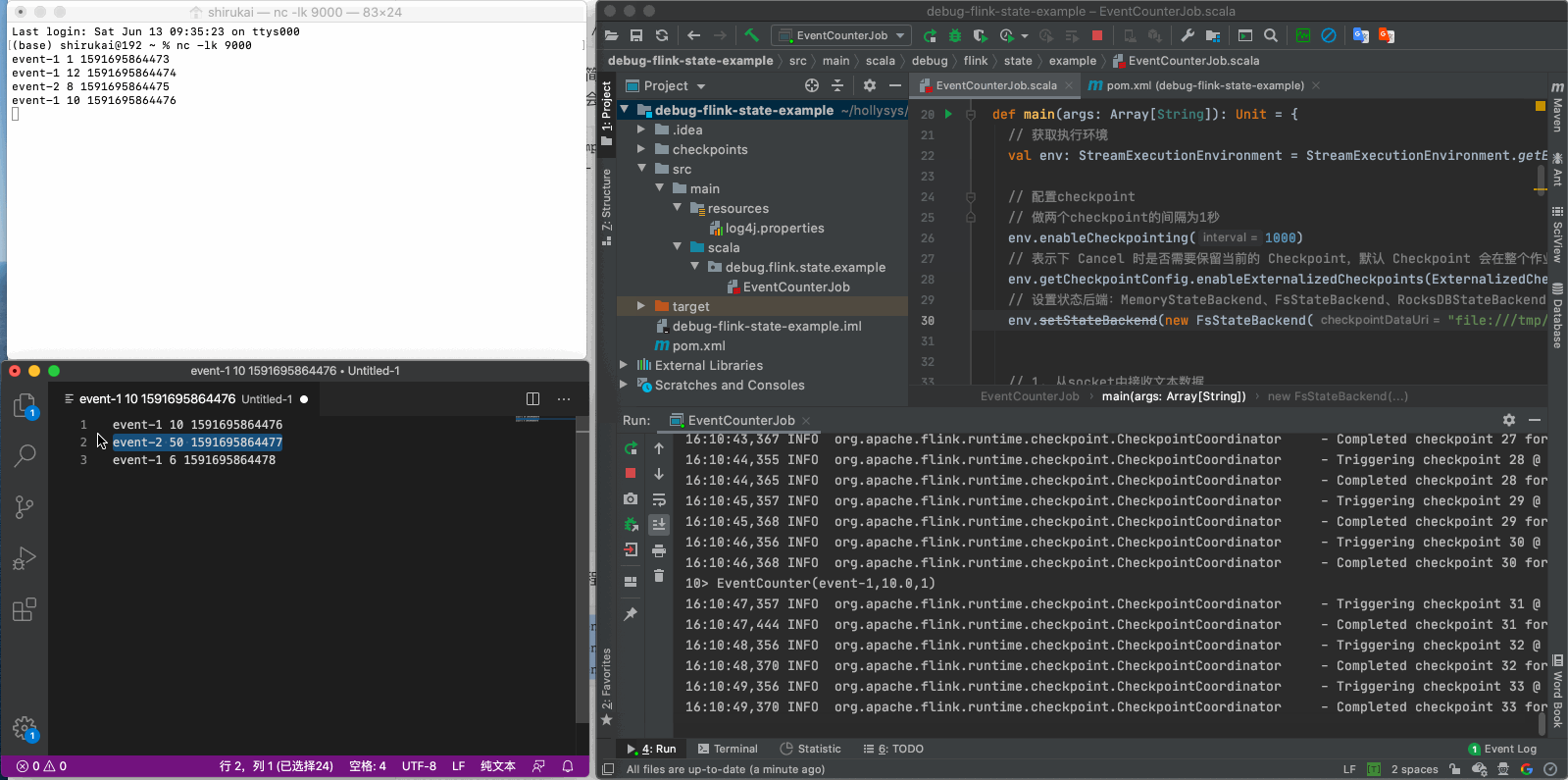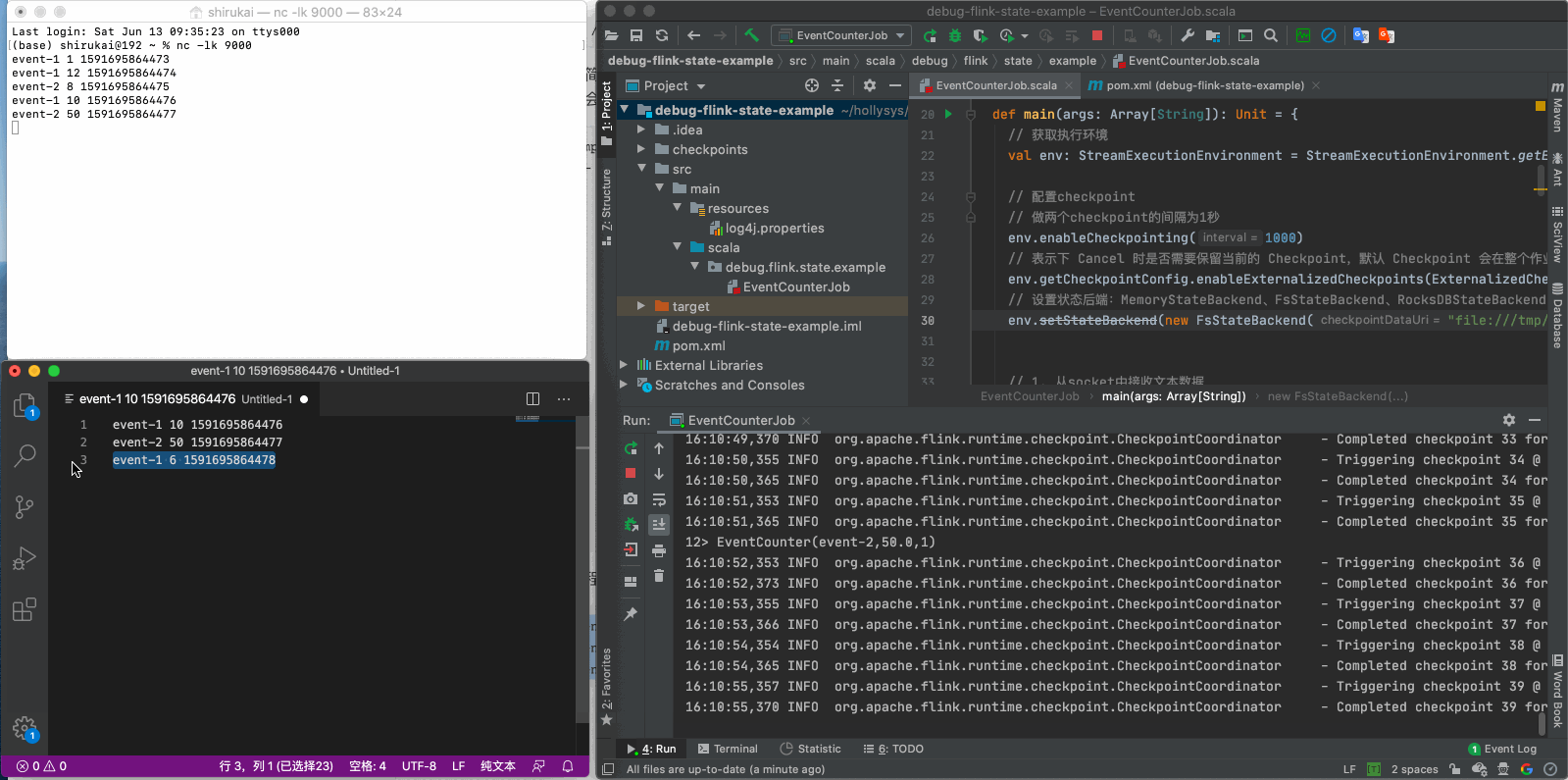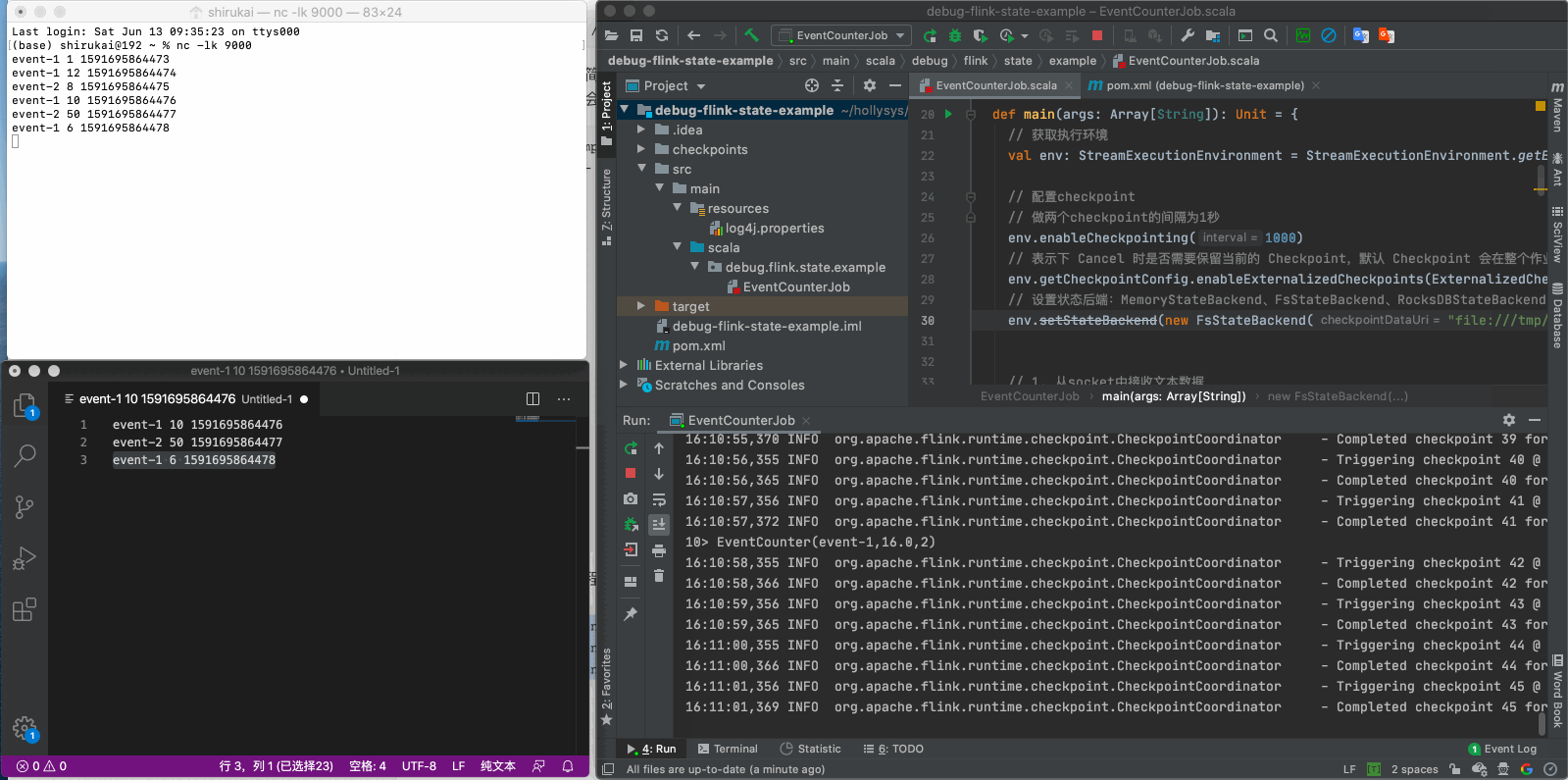
按照预期,当我们发送event-1 10 1591695864476这条数据时,我们得到的结果应该是EventCounter(event-1,11.5,3),但实际上得到的是EventCounter(event-1,10.0,1),很明显之前的状态丢失了,原因在文章开头已经说过,这是由于flink并不会自动加载之前的状态,需要我们手动指定checkpoint,如果使用命令行提交任务的话,可以使用-s参数指定savepoint的目录,那么如果在IDEA里开发测试时如何指定呢?下一章会介绍通过魔改源码的方式,实现checkpoint的加载。
4 魔改LocalStreamEnvironment
4.1 实现思路
首先讲一下思路,当执行env.execute(“EventCounterJob”)时,程序会根据不同的执行环境选择不同的StreamExecutionEnvironment,flink里有两种执行环境:LocalStreamEnvironment和RemoteStreamEnvironment,当我们在IDEA直接运行时,使用的是LocalStreamEnvironment。通过查看RemoteStreamEnvironment的源码可以发现,它最终在构造JobGraph的时候,会将SavepointRestoreSettings的配置通过JobGraph的setSavepointRestoreSettings方法传入到JobGraph中。而在LocalStreamEnvironment中构造的JobGraph没有传入SavepointRestoreSettings的配置,这里我们需要通过修改源码,给JobGraph添加SavepointRestoreSettings配置。
RemoteStreamEnvironment的源码位置:org.apache.flink.streaming.api.environment.RemoteStreamEnvironment。LocalStreamEnvironment的源码位置:org.apache.flink.streaming.api.environment.LocalStreamEnvironment,它的execute()实现源码如下:
public JobExecutionResult execute(String jobName) throws Exception {
// transform the streaming program into a JobGraph
StreamGraph streamGraph = getStreamGraph();
streamGraph.setJobName(jobName);
JobGraph jobGraph = streamGraph.getJobGraph();
jobGraph.setAllowQueuedScheduling(true);
Configuration configuration = new Configuration();
configuration.addAll(jobGraph.getJobConfiguration());
configuration.setString(TaskManagerOptions.MANAGED_MEMORY_SIZE, "0");
// add (and override) the settings with what the user defined
configuration.addAll(this.configuration);
if (!configuration.contains(RestOptions.BIND_PORT)) {
configuration.setString(RestOptions.BIND_PORT, "0");
}
int numSlotsPerTaskManager = configuration.getInteger(TaskManagerOptions.NUM_TASK_SLOTS, jobGraph.getMaximumParallelism());
MiniClusterConfiguration cfg = new MiniClusterConfiguration.Builder()
.setConfiguration(configuration)
.setNumSlotsPerTaskManager(numSlotsPerTaskManager)
.build();
if (LOG.isInfoEnabled()) {
LOG.info("Running job on local embedded Flink mini cluster");
}
MiniCluster miniCluster = new MiniCluster(cfg);
try {
miniCluster.start();
configuration.setInteger(RestOptions.PORT, miniCluster.getRestAddress().get().getPort());
return miniCluster.executeJobBlocking(jobGraph);
}
finally {
transformations.clear();
miniCluster.close();
}
}
这段代码的大体逻辑是这样的:
- 获取StreamGraph
- 从StreamGraph中获取JobGraph
- 构造配置
- 创建一个MiniCluster
- 将生成的JobGraph提交给MiniCluster
我们可以在提交JobGraph给MiniCluster之前,将SavepointRestoreSettings动态设置给JobGraph,从而实现加载指定savepoint的目的。
4.2 重写LocalStreamEnvironment
- 在java资源下创建一个名为org.apache.flink.streaming.api.environment包路径
- 在org.apache.flink.streaming.api.environment包下创建一个名为LocalStreamEnvironment的类
- LocalStreamEnvironment类内容如下所示:
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.streaming.api.environment;
import org.apache.flink.annotation.Public;
import org.apache.flink.api.common.InvalidProgramException;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.configuration.TaskManagerOptions;
import org.apache.flink.runtime.jobgraph.JobGraph;
import org.apache.flink.runtime.jobgraph.SavepointRestoreSettings;
import org.apache.flink.runtime.minicluster.MiniCluster;
import org.apache.flink.runtime.minicluster.MiniClusterConfiguration;
import org.apache.flink.streaming.api.graph.StreamGraph;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.annotation.Nonnull;
import java.util.Map;
/**
* The LocalStreamEnvironment is a StreamExecutionEnvironment that runs the program locally,
* multi-threaded, in the JVM where the environment is instantiated. It spawns an embedded
* Flink cluster in the background and executes the program on that cluster.
*
* <p>When this environment is instantiated, it uses a default parallelism of {@code 1}. The default
* parallelism can be set via {@link #setParallelism(int)}.
*/
@Public
public class LocalStreamEnvironment extends StreamExecutionEnvironment {
private static final Logger LOG = LoggerFactory.getLogger(LocalStreamEnvironment.class);
private final Configuration configuration;
private static final String LAST_CHECKPOINT = "last-checkpoint";
/**
* Creates a new mini cluster stream environment that uses the default configuration.
*/
public LocalStreamEnvironment() {
this(new Configuration());
}
/**
* Creates a new mini cluster stream environment that configures its local executor with the given configuration.
*
* @param configuration The configuration used to configure the local executor.
*/
public LocalStreamEnvironment(@Nonnull Configuration configuration) {
if (!ExecutionEnvironment.areExplicitEnvironmentsAllowed()) {
throw new InvalidProgramException(
"The LocalStreamEnvironment cannot be used when submitting a program through a client, " +
"or running in a TestEnvironment context.");
}
this.configuration = configuration;
setParallelism(1);
}
protected Configuration getConfiguration() {
return configuration;
}
/**
* Executes the JobGraph of the on a mini cluster of CLusterUtil with a user
* specified name.
*
* @param jobName name of the job
* @return The result of the job execution, containing elapsed time and accumulators.
*/
@Override
public JobExecutionResult execute(String jobName) throws Exception {
// transform the streaming program into a JobGraph
StreamGraph streamGraph = getStreamGraph();
streamGraph.setJobName(jobName);
JobGraph jobGraph = streamGraph.getJobGraph();
jobGraph.setAllowQueuedScheduling(true);
// ##############################################################################
// 获取全局Job参数
Map<String, String> parameters = this.getConfig().getGlobalJobParameters().toMap();
if (parameters.containsKey(LAST_CHECKPOINT)) {
// 加载checkpoint
String checkpointPath = parameters.get(LAST_CHECKPOINT);
jobGraph.setSavepointRestoreSettings(SavepointRestoreSettings.forPath(checkpointPath));
LOG.info("Load savepoint from {}.", checkpointPath);
}
// ##############################################################################
Configuration configuration = new Configuration();
configuration.addAll(jobGraph.getJobConfiguration());
configuration.setString(TaskManagerOptions.MANAGED_MEMORY_SIZE, "0");
// add (and override) the settings with what the user defined
configuration.addAll(this.configuration);
if (!configuration.contains(RestOptions.BIND_PORT)) {
configuration.setString(RestOptions.BIND_PORT, "0");
}
int numSlotsPerTaskManager = configuration.getInteger(TaskManagerOptions.NUM_TASK_SLOTS, jobGraph.getMaximumParallelism());
MiniClusterConfiguration cfg = new MiniClusterConfiguration.Builder()
.setConfiguration(configuration)
.setNumSlotsPerTaskManager(numSlotsPerTaskManager)
.build();
if (LOG.isInfoEnabled()) {
LOG.info("Running job on local embedded Flink mini cluster");
}
MiniCluster miniCluster = new MiniCluster(cfg);
try {
miniCluster.start();
configuration.setInteger(RestOptions.PORT, miniCluster.getRestAddress().get().getPort());
return miniCluster.executeJobBlocking(jobGraph);
} finally {
transformations.clear();
miniCluster.close();
}
}
}
上面魔改的代码部分思路是:从Job的全局参数中拿到最后一个checkpoint的路径,这个路径是我们传入进来的。然后通过jobGraph.setSavepointRestoreSettings(SavepointRestoreSettings.forPath(checkpointPath));设置到JobGraph中。
4.3 修改主程序
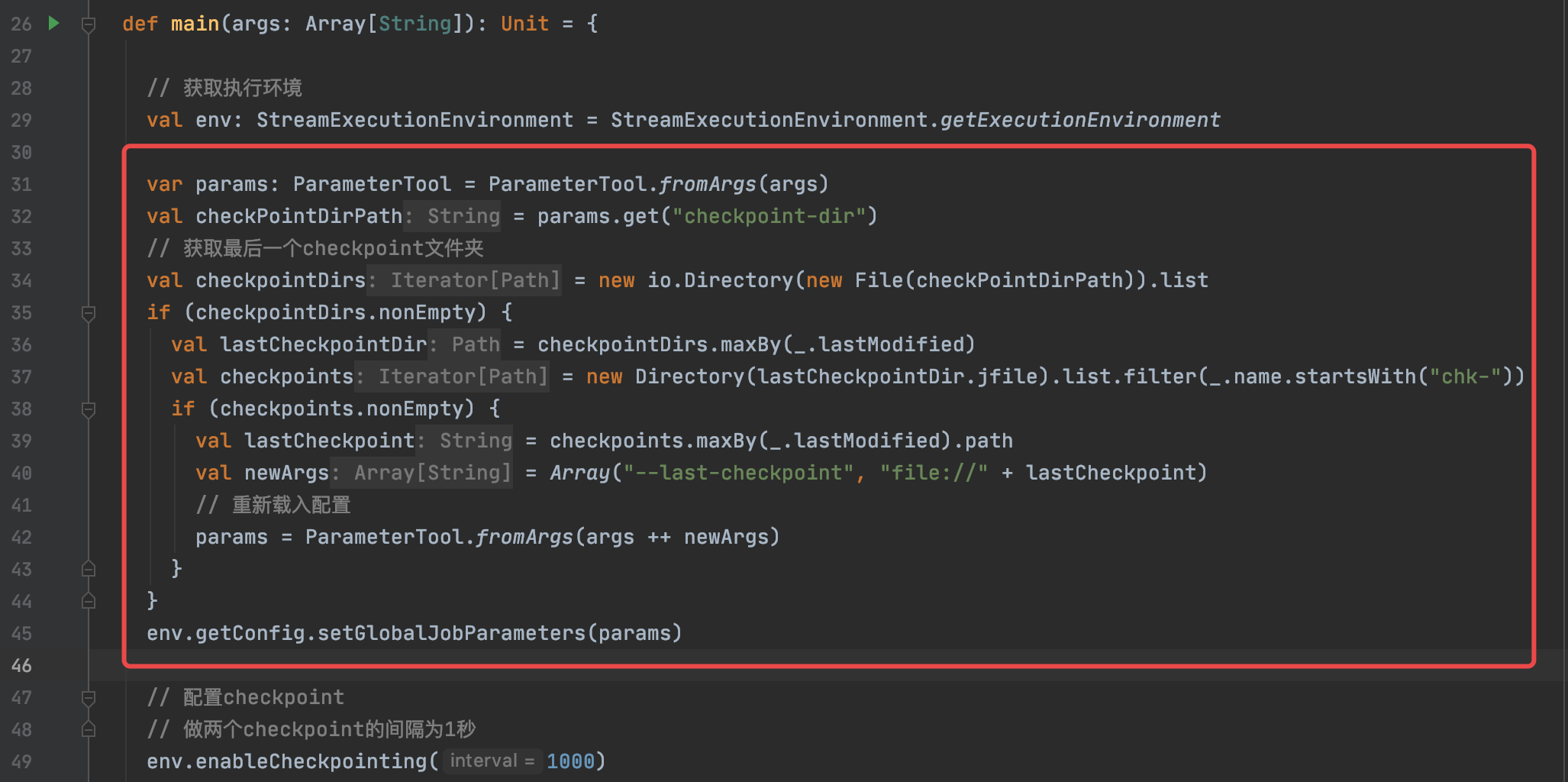
最后,需要修改主程序,让其自动获取最后一个checkpoint路径,然后传入给Job全局参数,添加代码如下:
var params: ParameterTool = ParameterTool.fromArgs(args)
val checkPointDirPath = params.get("checkpoint-dir")
// 获取最后一个checkpoint文件夹
val checkpointDirs = new io.Directory(new File(checkPointDirPath)).list
if (checkpointDirs.nonEmpty) {
val lastCheckpointDir = checkpointDirs.maxBy(_.lastModified)
val checkpoints = new Directory(lastCheckpointDir.jfile).list.filter(_.name.startsWith("chk-"))
if (checkpoints.nonEmpty) {
val lastCheckpoint = checkpoints.maxBy(_.lastModified).path
val newArgs = Array("--last-checkpoint", "file://" + lastCheckpoint)
// 重新载入配置
params = ParameterTool.fromArgs(args ++ newArgs)
}
}
env.getConfig.setGlobalJobParameters(params)
// ################################省略代码……
// 设置状态后端:MemoryStateBackend、FsStateBackend、RocksDBStateBackend,这里设置基于文件的状态后端
env.setStateBackend(new FsStateBackend("file://"+checkPointDirPath))
4.4 启动程序测试状态持久化
测试之前,先清除已有checkpoint
rm -rf /tmp/checkpoints/event-counter命令行执行nc -lk 9000
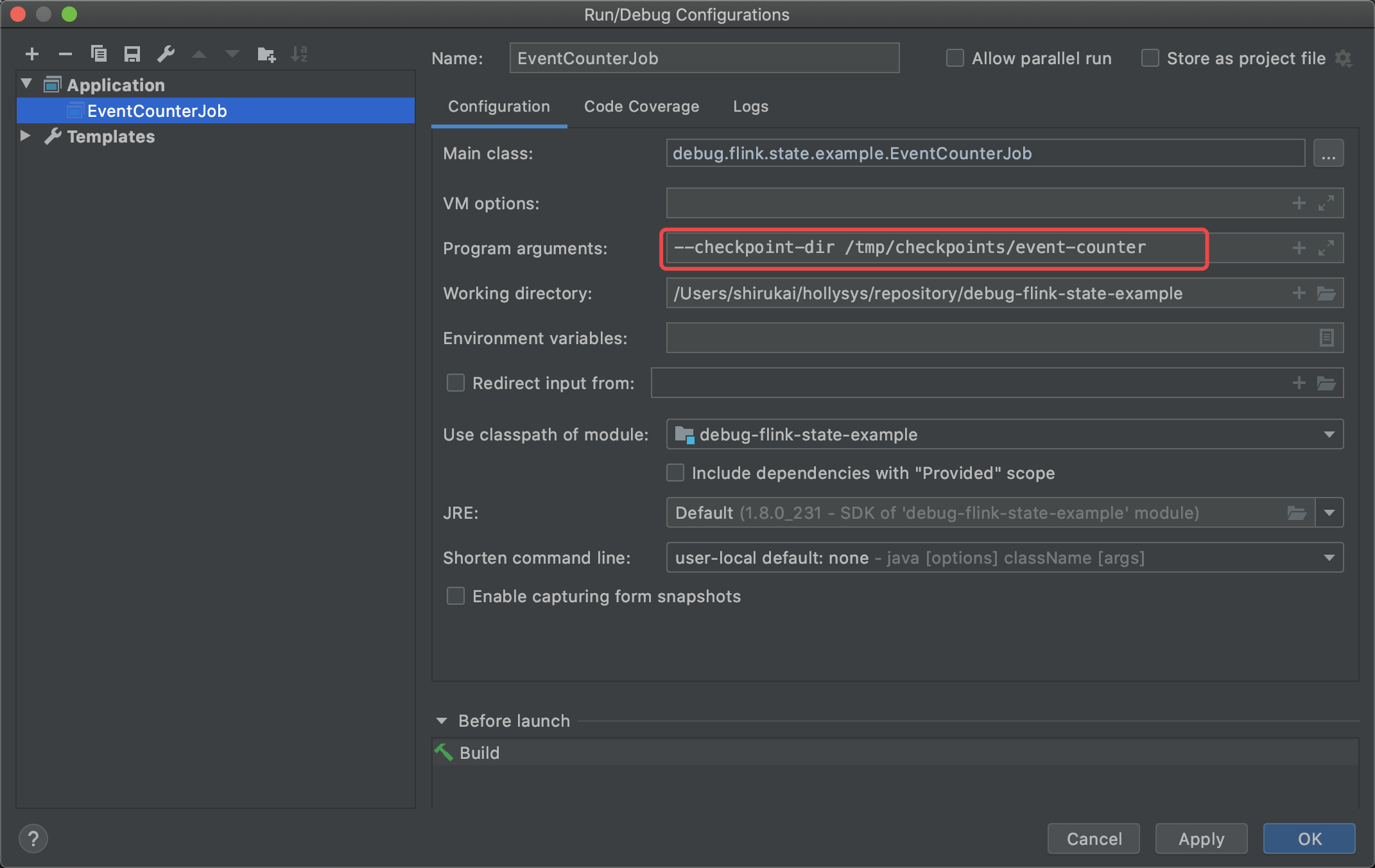
启动程序,指定参数–checkpoint-dir /tmp/checkpoints/event-counter
先发送三条数据
event-1 1 1591695864473 event-1 12 1591695864474 event-2 8 1591695864475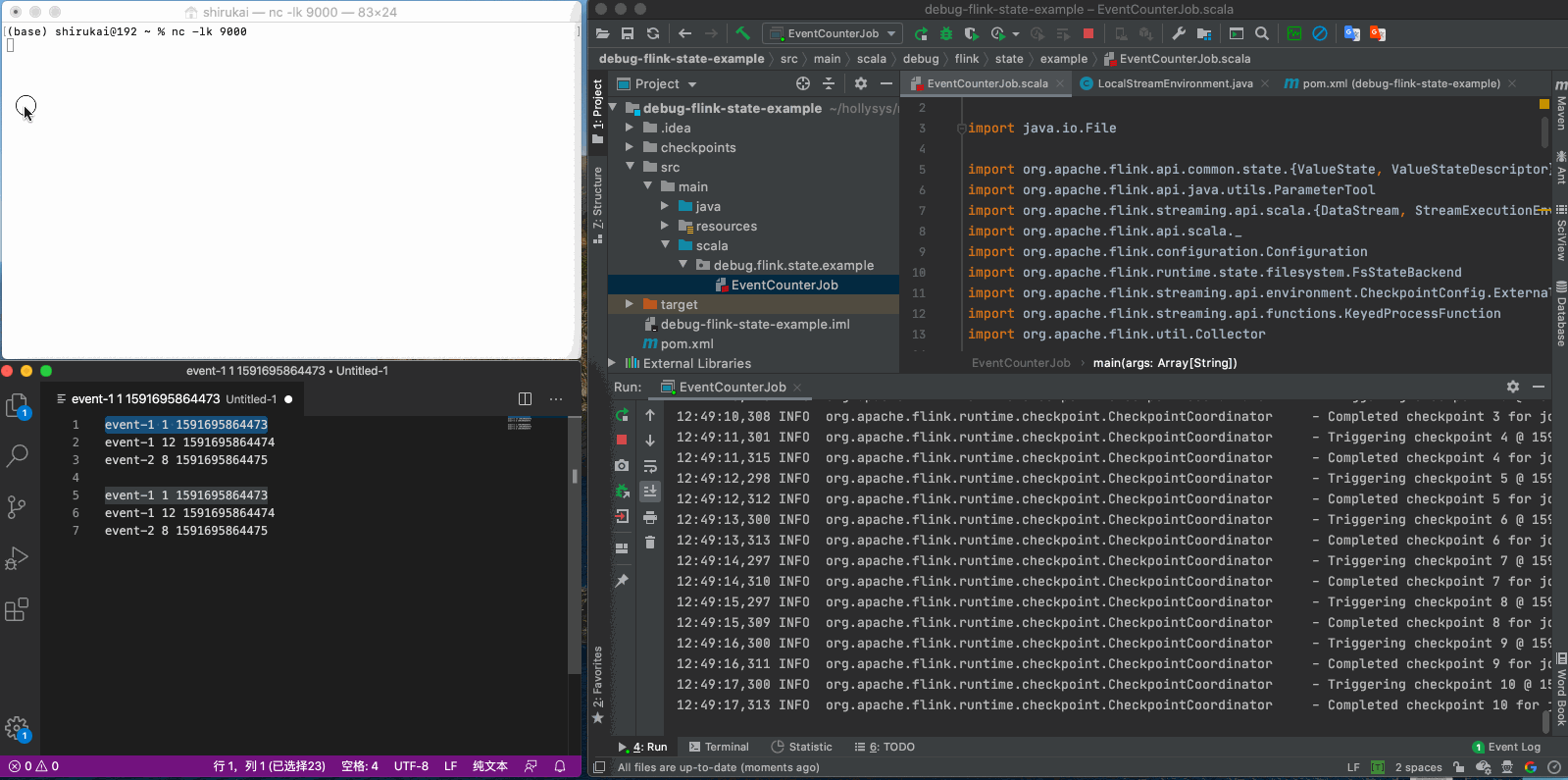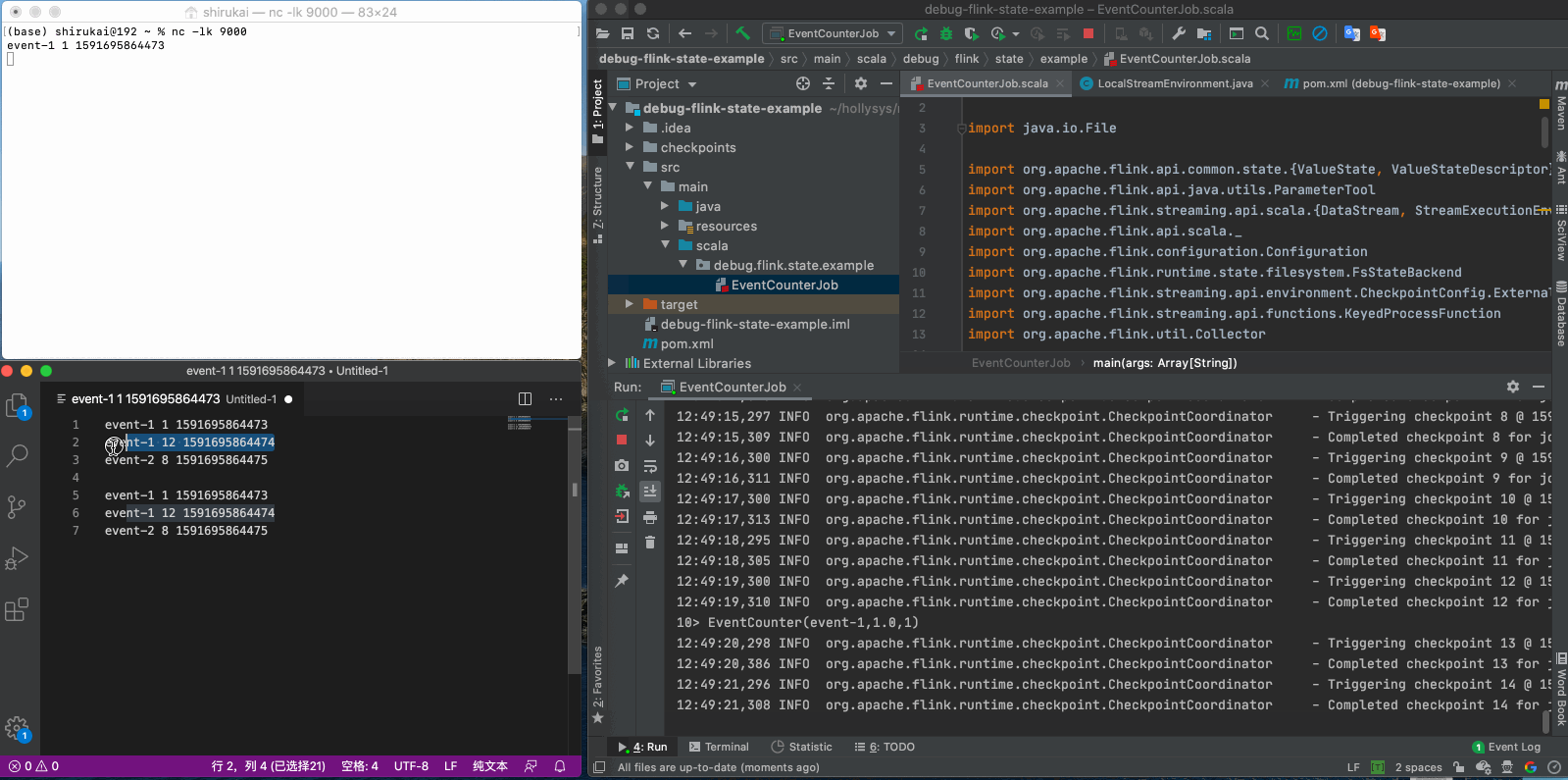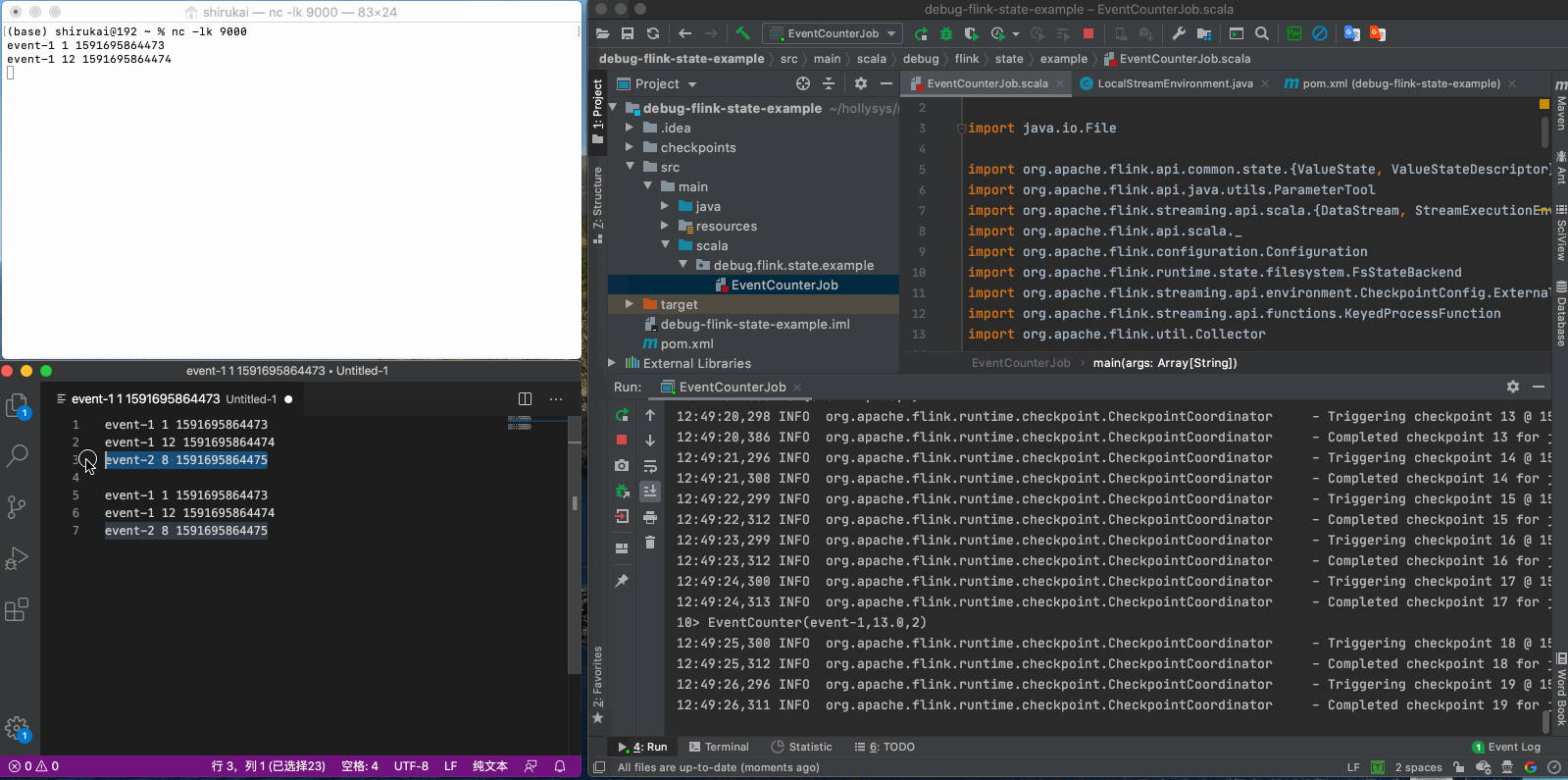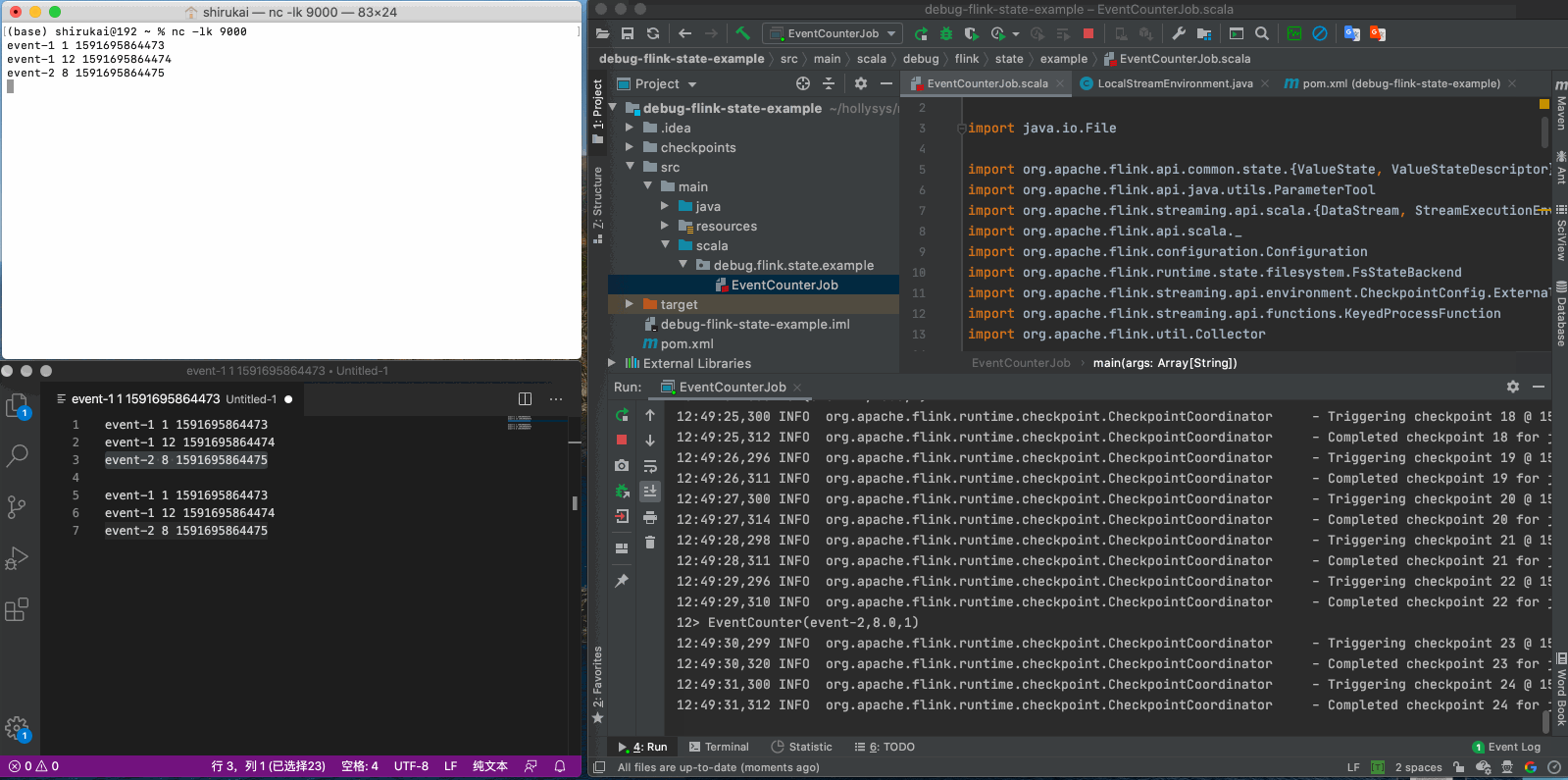
重启应用
再发送三条数据
event-1 1 1591695864473 event-1 12 1591695864474 event-2 8 1591695864475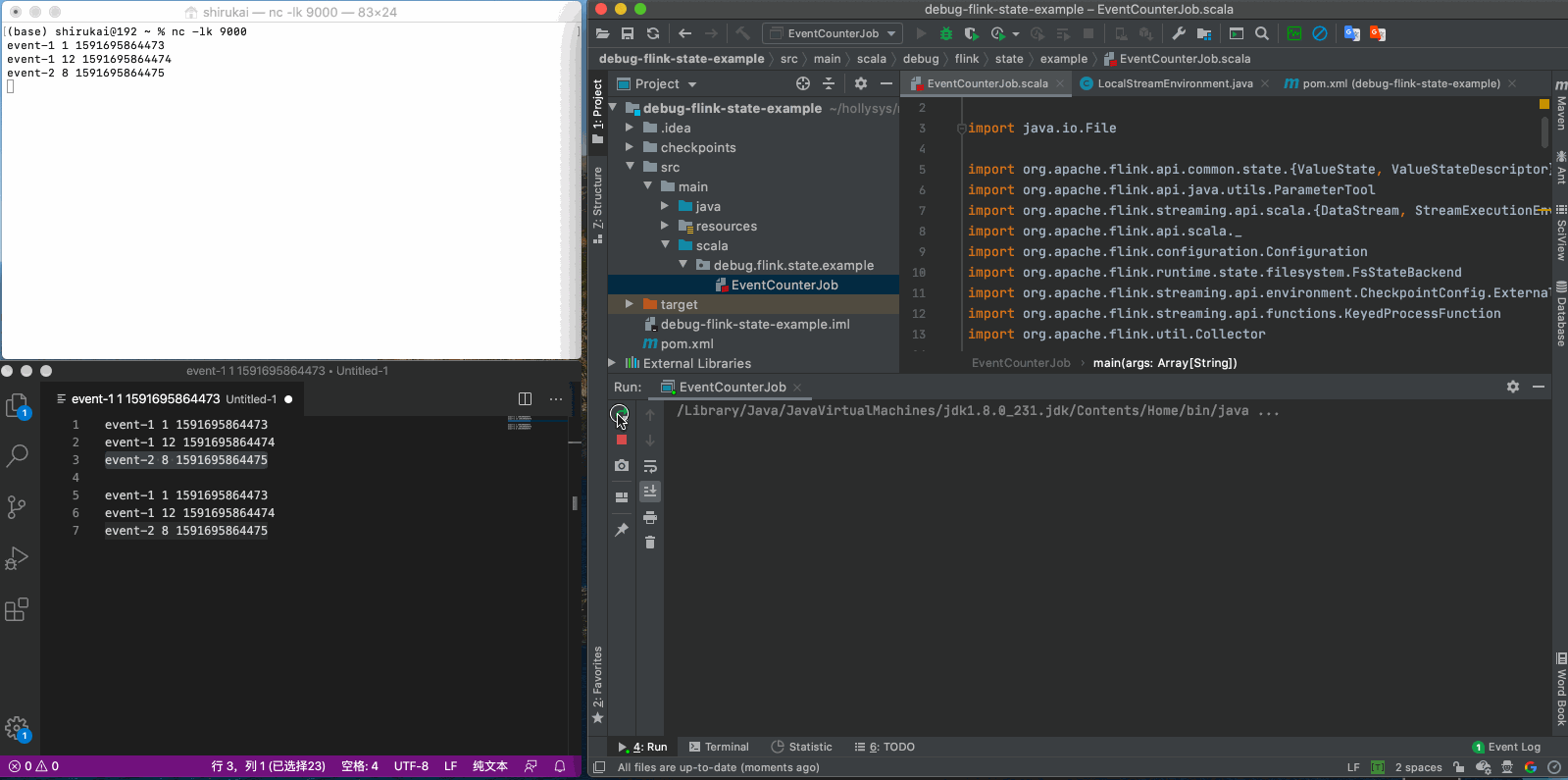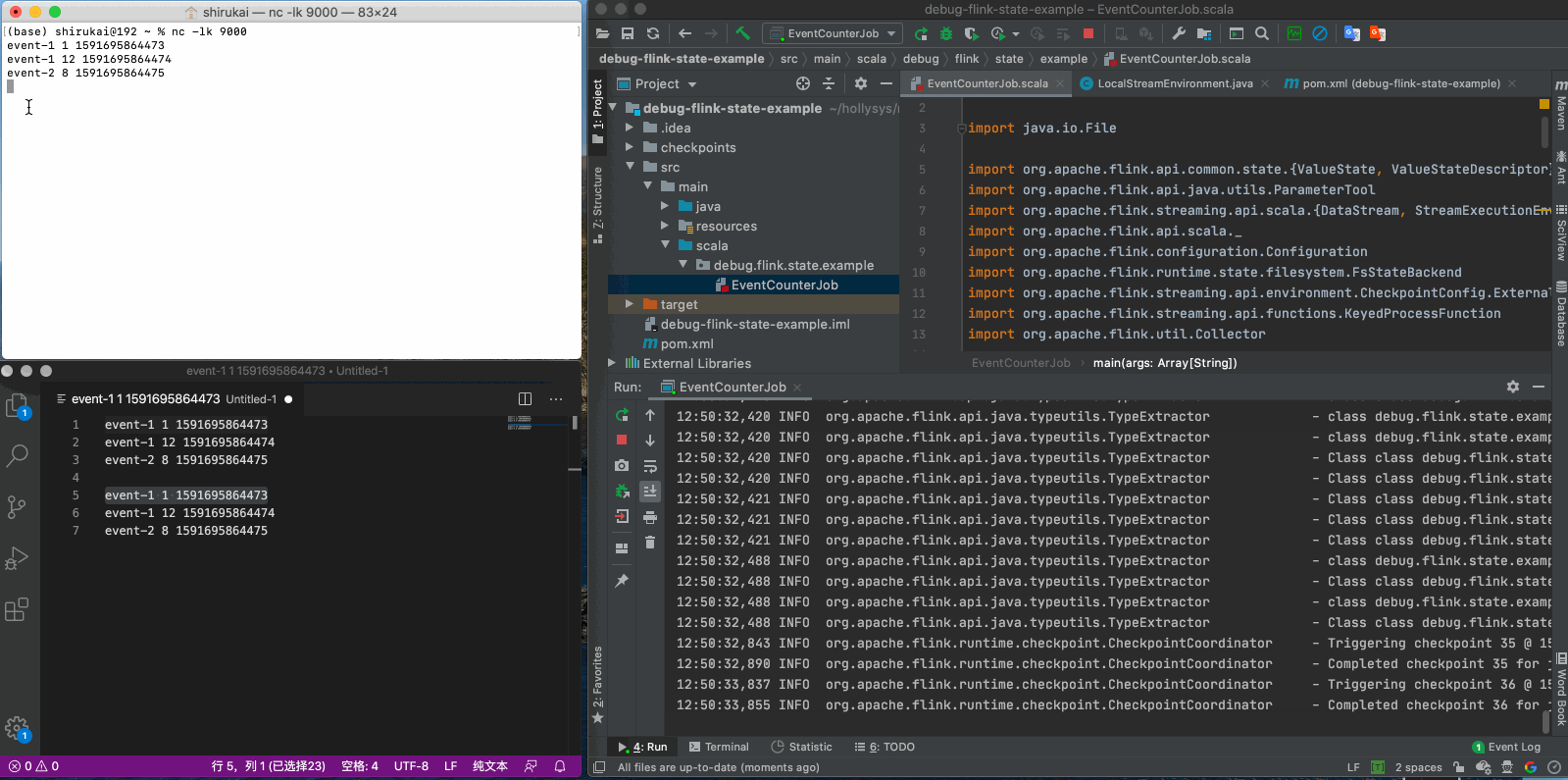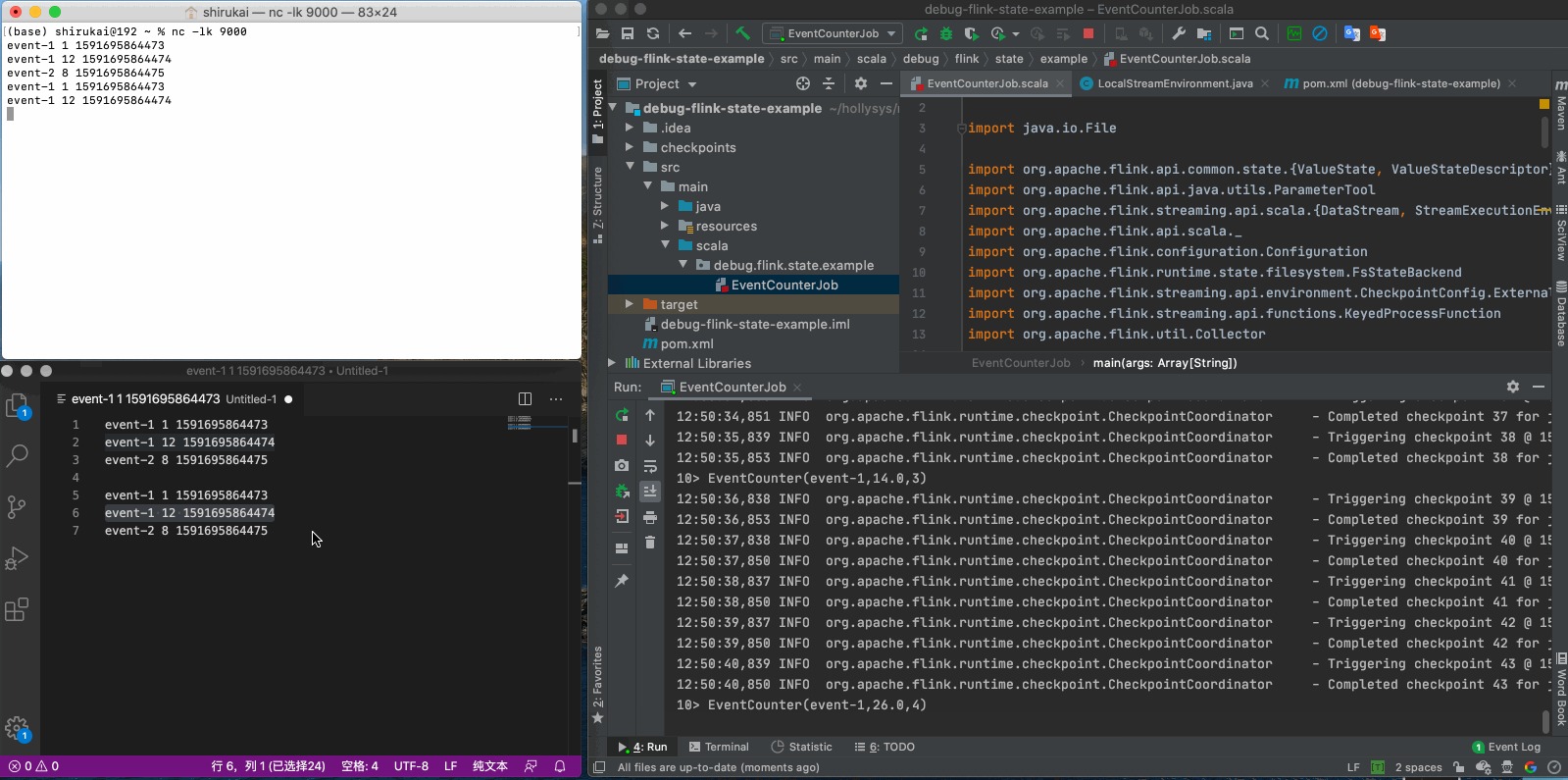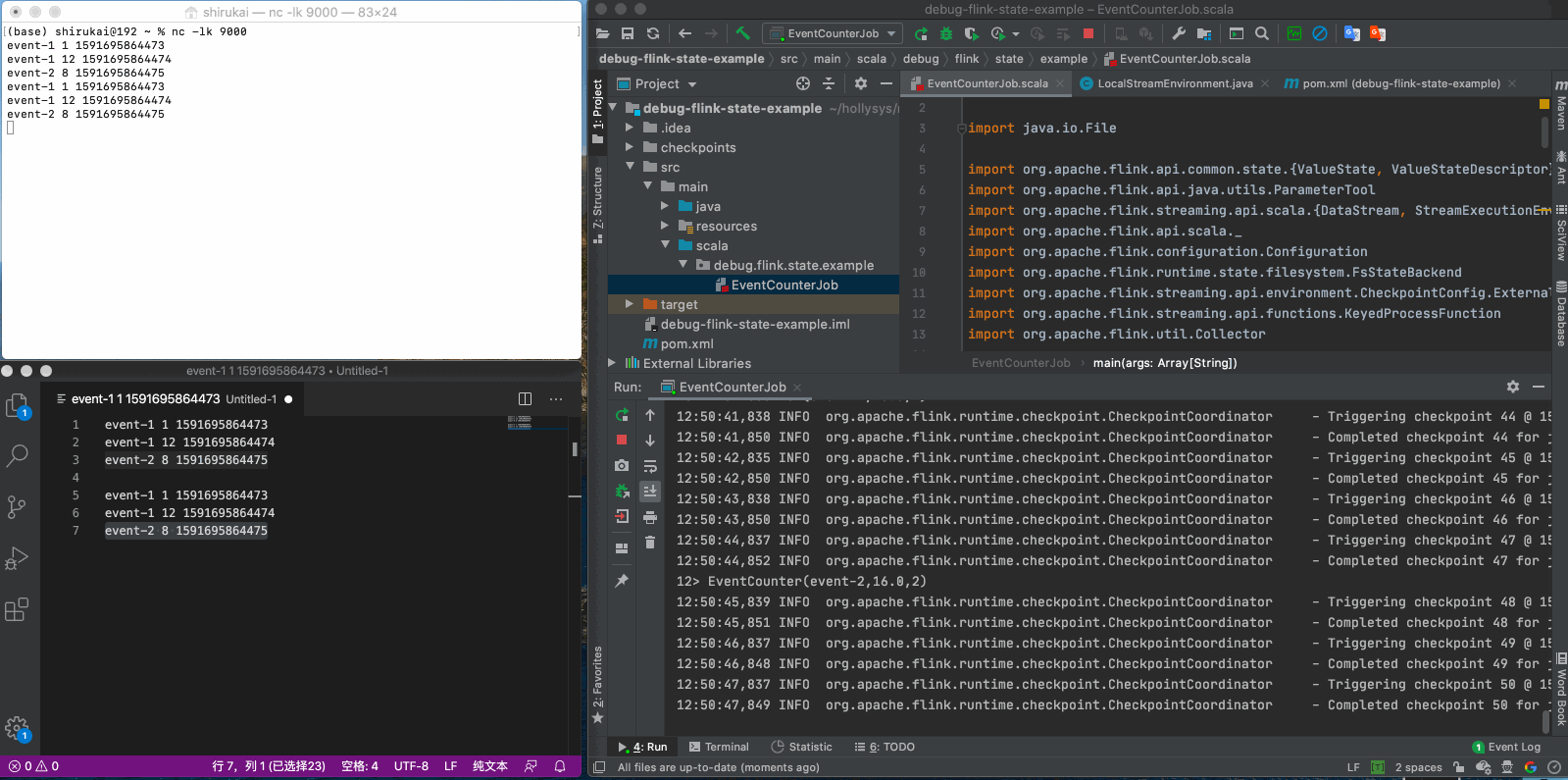
5 总结
经过魔改后的LocalStreamEnvironment,能够在程序启动时,自动的从指定的checkpoint目录获取最近一次的提交任务的最新的checkpoint,然后指定给JobGraph,使我们的程序能够加载到之前的状态。这种方式只是为了在本地验证状态的可用性,方便我们对状态进行调试,有这种需求的同学,不妨试一下,代码已经提交到github上了,另外有更好的方法,可以一起交流。
