Flink版本 1.8.0
ElasticSearch版本 5.1.2
Scala版本 2.11.12
Java版本 1.8
Github地址:https://github.com/shirukai/flink-examples-embedded-elasticsearch.git
1 前言
前些时间同学在群里问关于ElasticSearch的单元测试,如何mock。当时看到这个问题,我想的是mock一个写ElasticSearch的客户端的类?但是一直没想好怎么实现,这个问题一直困扰我。刚好最近接手的工作上,要求单元测试的覆盖率,恰好也有写ES的单元测试。先说一下我的工作需求,我是一个写es的flink任务,要求进行单元测试。通过查看flink 关于es connector的源码,豁然开朗,它的做法是启动了一个嵌入式的es节点。这篇文章将介绍一下三种方式启动嵌ElasticSearch服务用以单元测试:
- 从ElasticSearch官方包中启动单个Node节点
- 使用第三方依赖包启动ElasticSearch服务
- 使用Testcontainers启动ElasticSearch服务
并将我在Flink中使用嵌入式ES踩过的坑统一记录下来,避免让更多的同学踩坑,话说今天是周三,掉坑里两天了终于爬出来了。
2 快速创建Flink项目
按照惯例,我给每一个需要验证的技术点都搭建一个新环境,确保做的验证没有污染。废话不多说,执行如下命令基于flink官方模板创建一个Maven项目:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.8.0 -DgroupId=flink.examples -DartifactId=flink-examples-embedded-elasticsearch -Dversion=1.0 -Dpackage=flink.examples.embedded.elasticsearch -DinteractiveMode=false
pom.xml文件中加入如下依赖
<!-- elasticsearch -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch5_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- json4s -->
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_${scala.binary.version}</artifactId>
<version>3.6.7</version>
</dependency>
3 简单编写一个Flink写入ES的任务
在flink.embedded.elasticsearch.examples下创建一个名为WriteElasticSearchJob的Scala object,实现比较简单:
- 从集合中构建一个事件流
- 将事件流写入ES
代码如下所示:
package flink.embedded.elasticsearch.examples
import java.net.{InetAddress, InetSocketAddress}
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}
import org.apache.flink.streaming.connectors.elasticsearch5.ElasticsearchSink
import org.elasticsearch.client.Requests
import org.json4s.{Formats, NoTypeHints}
import org.json4s.jackson.Serialization
import scala.util.Random
/**
* 模拟数据写入Es
*
* @author shirukai
*/
object WriteElasticSearchJob {
case class Event(id: String, v: Double, t: Long)
def main(args: Array[String]): Unit = {
// 获取执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 解析参数
val params: ParameterTool = ParameterTool.fromArgs(args)
// 1. 从集合中创建一个DataStream
val events = env.fromCollection(1 to 20).map(i => {
val v = Random.nextDouble()
val t = System.currentTimeMillis()
Event("event-" + i, v, t)
})
// 2. 将事件写入Es
val (userConfig, transportAddresses) = parseEsConfigs(params)
import scala.collection.JavaConversions._
val esSink = new ElasticsearchSink(userConfig, transportAddresses, new EventSinkFunction)
events.addSink(esSink)
env.execute("WriteElasticSearchJob")
}
def parseEsConfigs(params: ParameterTool): (Map[String, String], List[InetSocketAddress]) = {
// 构建userConfig,主要设置Es集群名称
val userConfig = Map[String, String](
"cluster.name" -> params.get("es.cluster.name", "es-test")
)
// 构建transport地址
val esNodes = params.get("es.cluster.nodes", "127.0.0.1").split(",").toList
val esPort = params.getInt("es.cluster.port", 9300)
val transportAddresses = esNodes.map(node => new InetSocketAddress(InetAddress.getByName(node), esPort))
(userConfig, transportAddresses)
}
/**
* 继承ElasticsearchSinkFunction实现构建索引的方法
*/
class EventSinkFunction extends ElasticsearchSinkFunction[Event] {
override def process(t: Event, runtimeContext: RuntimeContext, requestIndexer: RequestIndexer): Unit = {
implicit val formats: AnyRef with Formats = Serialization.formats(NoTypeHints)
val source: String = Serialization.write(t)
requestIndexer.add(Requests.indexRequest()
.index("events")
.`type`("test")
.id(t.id)
.source(source)
)
}
}
}
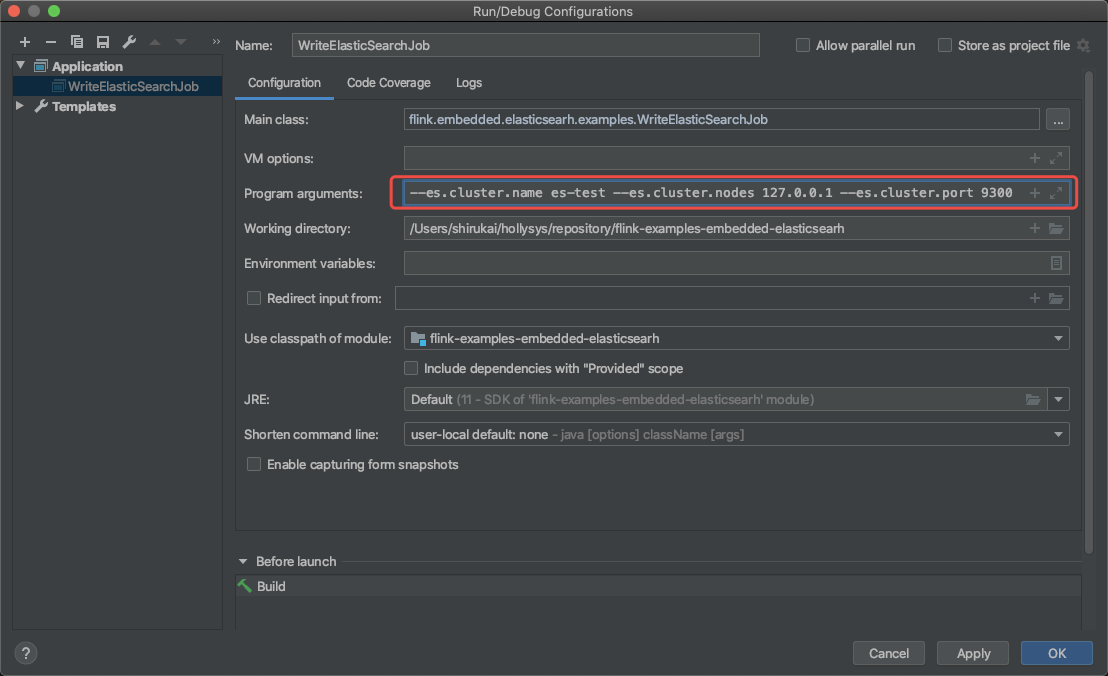
flink任务写好了,就可以执行main方法进行验证了,从上面代码中可以看出,程序接受如下参数:
- es.cluster.name 集群名称,默认值:es-test
- es.cluster.nodes 集群节点IP,多个IP以逗号分隔,默认值:127.0.0.1
- es.cluster.port 集群节点端口号,默认值:9300
可以在启动程序的时候指定上面的参数,如果不指定将使用默认值。
4 三种方式启动嵌入式ElasticSearch服务
4.1 从ElasticSearch官方包中启动单个Node节点
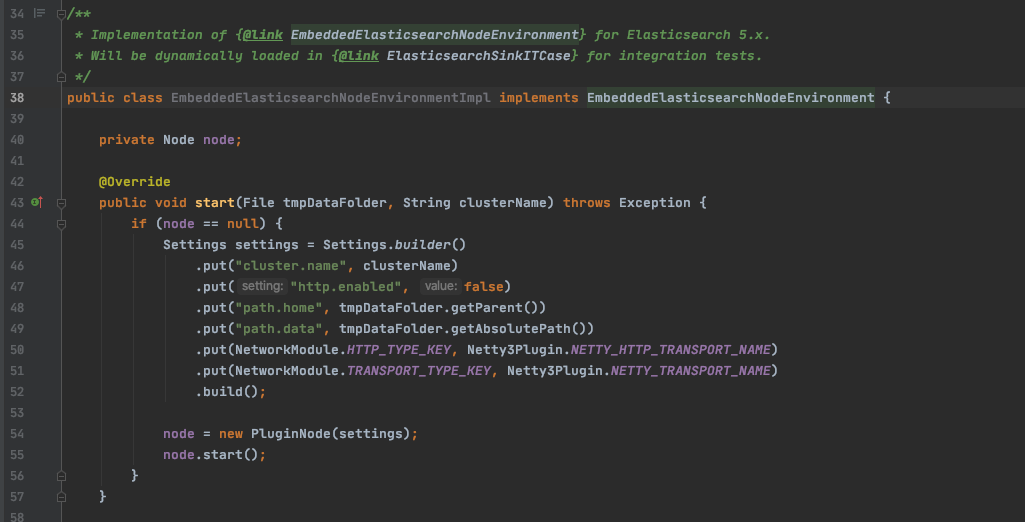
这种方式是Flink在他们的单元测试中使用的,可以下载flink的源码在flink-connectors/flink-connector-elasticsearch5模块下查看。
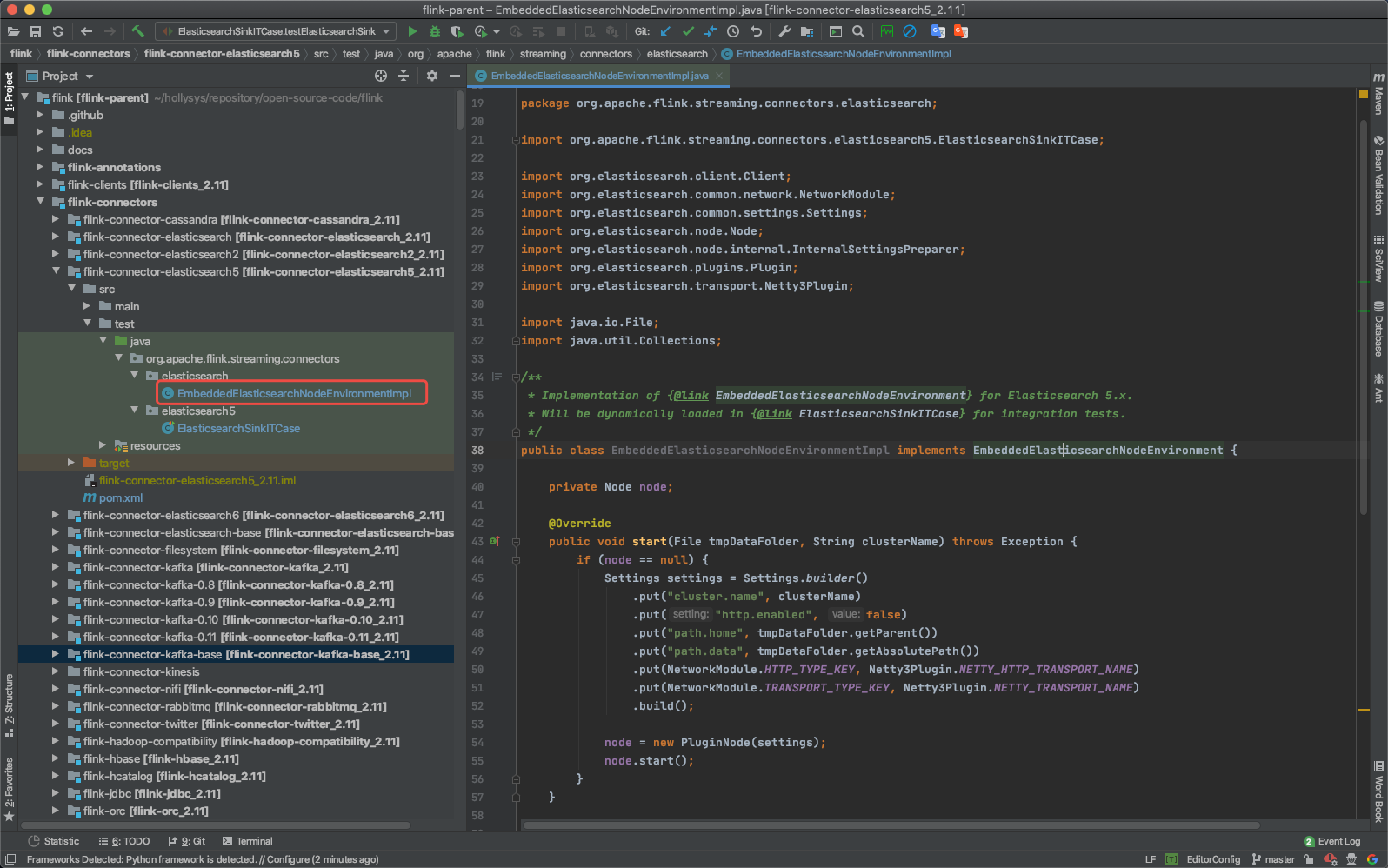
上述代码相对比较简单,通过Settings构建一个配置实例,然后创建一个Node实例即可。
4.1.1 快速入门示例
使用Java先实现一个快速入门的示例,创建flink.embedded.elasticsearch.examples.LocalNodeQuickStartExample类,实现内容如下:
package flink.embedded.elasticsearch.examples;
import org.elasticsearch.common.network.NetworkModule;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.node.Node;
import org.elasticsearch.node.NodeValidationException;
import org.elasticsearch.node.internal.InternalSettingsPreparer;
import org.elasticsearch.transport.Netty4Plugin;
import java.util.Collections;
/**
* Es本地节点快速入门示例
* @author shirukai
*/
public class LocalNodeQuickStartExample {
private static class PluginNode extends Node {
public PluginNode(Settings settings) {
super(InternalSettingsPreparer.prepareEnvironment(settings, null), Collections.singletonList(Netty4Plugin.class));
}
}
public static void main(String[] args) throws NodeValidationException {
String systemTempDir = System.getProperty("java.io.tmpdir");
String esTempDir = systemTempDir+"/es";
Settings settings = Settings.builder()
.put("cluster.name", "test")
.put("http.enabled", true)
.put("path.home", systemTempDir)
.put("path.data", esTempDir)
.put(NetworkModule.HTTP_TYPE_KEY, Netty4Plugin.NETTY_HTTP_TRANSPORT_NAME)
.put(NetworkModule.TRANSPORT_TYPE_KEY, Netty4Plugin.NETTY_TRANSPORT_NAME)
.build();
PluginNode node = new PluginNode(settings);
node.start();
// 让它一直阻塞吧
Thread.currentThread().join();
}
}
运行mian方法,应该会报出如下异常:
Exception in thread "main" java.lang.ExceptionInInitializerError
at org.elasticsearch.node.Node.<init>(Node.java:268)
at flink.embedded.elasticsearch.examples.LocalNodeQuickStartExample$PluginNode.<init>(LocalNodeQuickStartExample.java:19)
at flink.embedded.elasticsearch.examples.LocalNodeQuickStartExample.main(LocalNodeQuickStartExample.java:33)
Caused by: java.lang.IllegalStateException: Error finding the build shortHash. Stopping Elasticsearch now so it doesn't run in subtly broken ways. This is likely a build bug.
at org.elasticsearch.Build.<clinit>(Build.java:62)
... 3 more

出现这个异常,是由于依赖包的问题导致的,我们需要在pom文件中加入es的依赖:
<!-- Dependency for Elasticsearch 5.x Java Client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
注意这个依赖一定要放在flink-connector-elasticsearch5依赖之前,因为flink的es连接器里打包了es的依赖,没有办法排除,只能在它之前引入新的es依赖,并且版本要与connector里的版本一致,以elasticsearch5为例,它里面指定的es版本为5.1.2
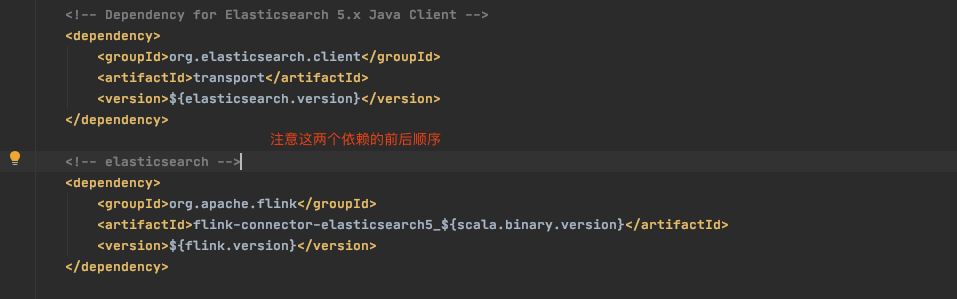
加入es依赖之后如果还报错,可以尝试清空maven仓库.m2下对应的缓存.m2/repository/org/apache/flink/flink-connector-elasticsearch5_2.11/*。
再次运行mian方法,应该还会报出如下异常:
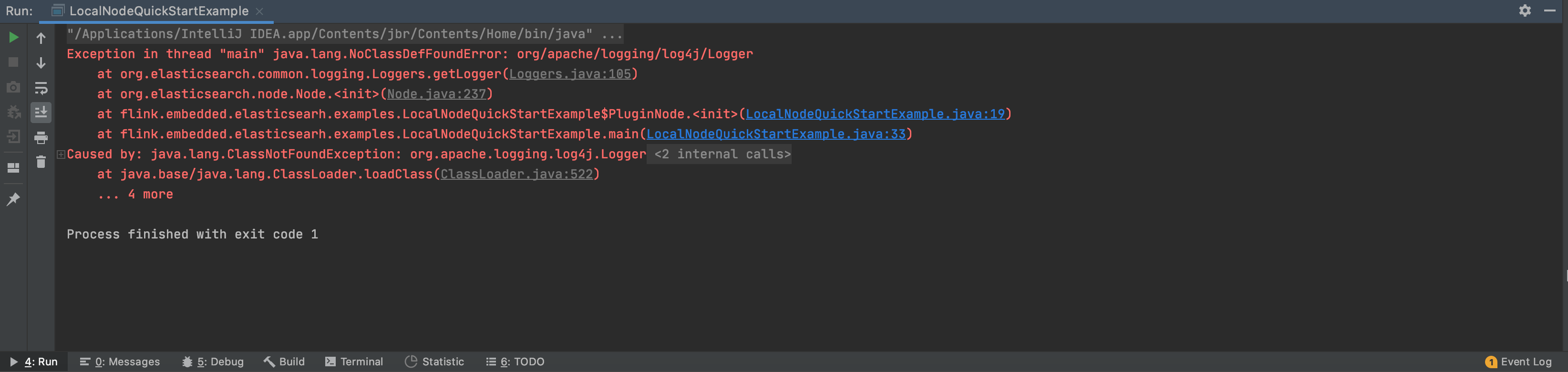
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/logging/log4j/Logger
at org.elasticsearch.common.logging.Loggers.getLogger(Loggers.java:105)
at org.elasticsearch.node.Node.<init>(Node.java:237)
at flink.embedded.elasticsearch.examples.LocalNodeQuickStartExample$PluginNode.<init>(LocalNodeQuickStartExample.java:19)
at flink.embedded.elasticsearch.examples.LocalNodeQuickStartExample.main(LocalNodeQuickStartExample.java:33)
Caused by: java.lang.ClassNotFoundException: org.apache.logging.log4j.Logger
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:522)
... 4 more
这是由于缺少log4j2相关的依赖,flink的做法是使用log4j-to-slf4j将其路由到slf4j,关于log4j-to-slf4j的介绍参考http://logging.apache.org/log4j/2.x/log4j-to-slf4j/。
所以这里需要在pom中添加如下依赖:
<!--
Elasticsearch 5.x uses Log4j2 and no longer detects logging implementations, making
Log4j2 a strict dependency. The following is added so that the Log4j2 API in
Elasticsearch 5.x is routed to SLF4J. This way, user projects can remain flexible
in the logging implementation preferred.
-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.7</version>
</dependency>
现在终于可以正常运行了。
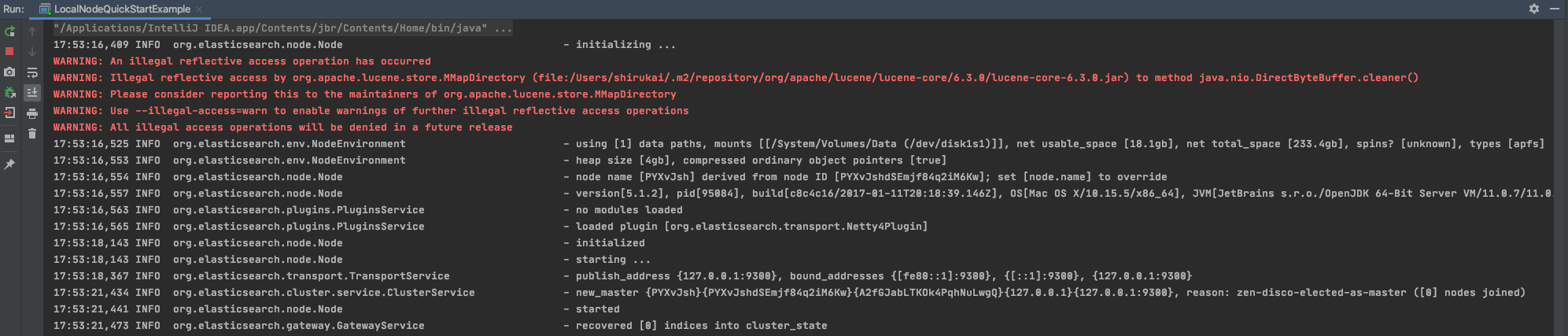
发送个接口查看一下集群状态http://127.0.0.1:9200/_cluster/health?pretty=true
{
"cluster_name": "test",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
4.1.2 使用Builder模式封装ElasticSearchLocalNode
在flink.embedded.elasticsearch.examples下创建一个名为ElasticSearchLocalNode的类,主要是使用builder模式,构建setting,然后通过setting构建一个Node实例。
实现内容如下:
package flink.embedded.elasticsearch.examples;
import org.elasticsearch.common.network.NetworkModule;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.node.Node;
import org.elasticsearch.node.internal.InternalSettingsPreparer;
import org.elasticsearch.transport.Netty4Plugin;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Collections;
import java.util.Comparator;
/**
* 继承org.elasticsearch.node.Node实现一个本地节点
*
* @author shirukai
*/
public class ElasticSearchLocalNode extends Node {
private static final Logger LOG = LoggerFactory.getLogger(ElasticSearchLocalNode.class);
private final String tempDir;
private ElasticSearchLocalNode(Settings preparedSettings, String tempDir) {
super(InternalSettingsPreparer.prepareEnvironment(preparedSettings, null), Collections.singletonList(Netty4Plugin.class));
this.tempDir = tempDir;
}
public static class Builder {
private final Settings.Builder builder;
private String tempDir;
public Builder() {
builder = Settings.builder();
builder.put("network.host", "0.0.0.0");
builder.put(NetworkModule.HTTP_TYPE_KEY, Netty4Plugin.NETTY_HTTP_TRANSPORT_NAME);
builder.put(NetworkModule.TRANSPORT_TYPE_KEY, Netty4Plugin.NETTY_TRANSPORT_NAME);
builder.put("http.enabled", true);
}
public ElasticSearchLocalNode.Builder put(String key, String value) {
this.builder.put(key, value);
return this;
}
public ElasticSearchLocalNode.Builder setClusterName(String name) {
this.builder.put("cluster.name", name);
return this;
}
public ElasticSearchLocalNode.Builder setTcpPort(int port) {
this.builder.put("transport.tcp.port", port);
return this;
}
public ElasticSearchLocalNode.Builder setTempDir(String tempDir) {
this.tempDir = tempDir;
this.builder.put("path.home", tempDir + "/home");
this.builder.put("path.data", tempDir + "/data");
return this;
}
public ElasticSearchLocalNode.Builder enableHttpCors(boolean enable) {
this.builder.put("http.cors.enabled", enable);
if (enable) {
this.builder.put("http.cors.allow-origin", "*");
}
return this;
}
public ElasticSearchLocalNode build() {
return new ElasticSearchLocalNode(this.builder.build(), tempDir);
}
}
public void stop() {
this.stop(false);
}
public void stop(boolean cleanDataDir) {
if (cleanDataDir && tempDir != null) {
try {
this.close();
Files.walk(new File(tempDir).toPath())
.sorted(Comparator.reverseOrder())
.map(Path::toFile)
.forEach(File::delete);
} catch (IOException e) {
LOG.error("Failed to stop elasticsearch local node.", e);
}
}
}
}
4.1.3 对ElasticSearchLocalNode进行单元测试
引入单元测试依赖
<!-- dependencies for test --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency>实现单元测试ElasticSearchLocalNodeTest
package flink.embedded.elasticsearch.examples; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.node.NodeValidationException; import org.junit.AfterClass; import org.junit.BeforeClass; import org.junit.Test; /** * 对ElasticSearchLocalNode进行单元测试 * * @author shirukai */ public class ElasticSearchLocalNodeTest { private static ElasticSearchLocalNode esNode; /** * 单元测试之前,创建es节点实例,绑定端口19300 */ @BeforeClass public static void prepare() throws NodeValidationException { esNode = new ElasticSearchLocalNode.Builder() .setClusterName("test-es") .setTcpPort(19300) .setTempDir("data/es") .build(); esNode.start(); } @Test public void addIndexTest() { People people = new People("xiaoming", 19, 15558800456L); esNode.client().prepareIndex() .setIndex("people") .setType("man") .setId("1") .setSource(people.toString()) .get(); } @Test public void getIndexTest() throws InterruptedException { Thread.sleep(1000); SearchResponse response = esNode.client().prepareSearch("people").execute().actionGet(); System.out.println(response.toString()); } /** * 单元测试之后,停止es节点 */ @AfterClass public static void shutdown() { if (null != esNode) { esNode.stop(true); } } public static class People { private String name; private int age; private long phone; public People(String name, int age, long phone) { this.name = name; this.age = age; this.phone = phone; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public long getPhone() { return phone; } public void setPhone(long phone) { this.phone = phone; } @Override public String toString() { return "{" + "\"name\":\"" + name + "\"" + ", \"age\":\"" + age + "\"" + ", \"phone\":\"" + phone + "\"" + "}"; } } }运行单元测试,这时会被如下错误
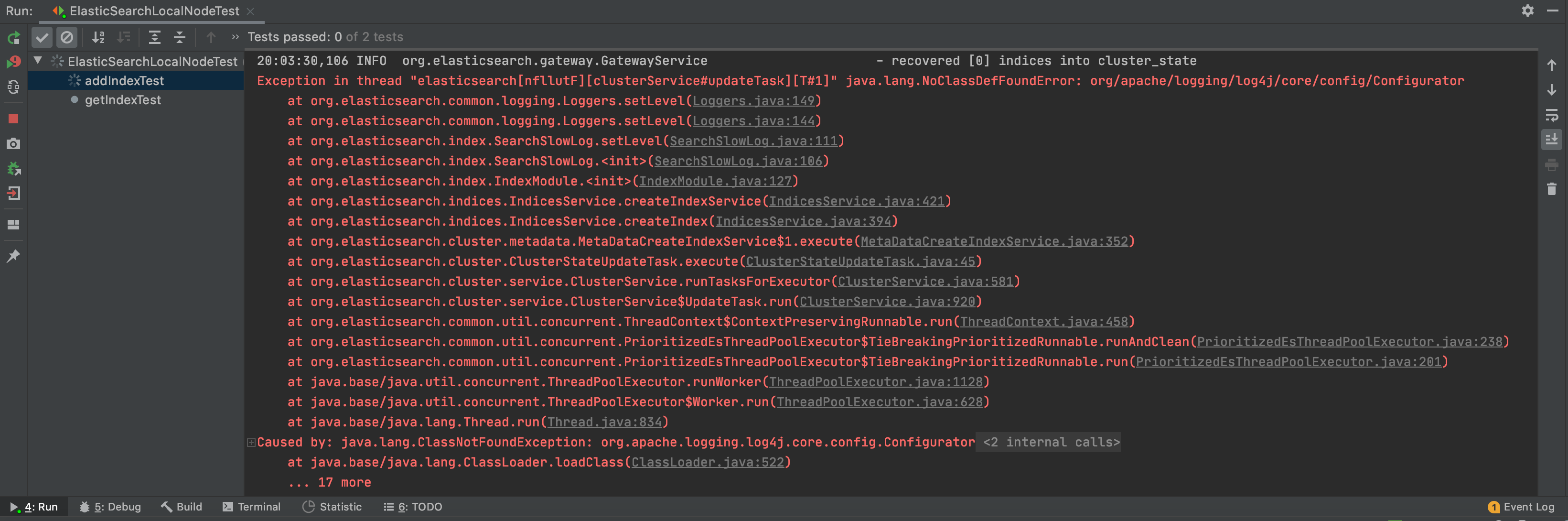
Exception in thread "elasticsearch[nfllutF][clusterService#updateTask][T#1]" java.lang.NoClassDefFoundError: org/apache/logging/log4j/core/config/Configurator at org.elasticsearch.common.logging.Loggers.setLevel(Loggers.java:149) at org.elasticsearch.common.logging.Loggers.setLevel(Loggers.java:144) at org.elasticsearch.index.SearchSlowLog.setLevel(SearchSlowLog.java:111) at org.elasticsearch.index.SearchSlowLog.<init>(SearchSlowLog.java:106) at org.elasticsearch.index.IndexModule.<init>(IndexModule.java:127) at org.elasticsearch.indices.IndicesService.createIndexService(IndicesService.java:421) at org.elasticsearch.indices.IndicesService.createIndex(IndicesService.java:394) at org.elasticsearch.cluster.metadata.MetaDataCreateIndexService$1.execute(MetaDataCreateIndexService.java:352) at org.elasticsearch.cluster.ClusterStateUpdateTask.execute(ClusterStateUpdateTask.java:45) at org.elasticsearch.cluster.service.ClusterService.runTasksForExecutor(ClusterService.java:581) at org.elasticsearch.cluster.service.ClusterService$UpdateTask.run(ClusterService.java:920) at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:458) at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:238) at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:201) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:834) Caused by: java.lang.ClassNotFoundException: org.apache.logging.log4j.core.config.Configurator at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581) at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178) at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:522) ... 17 more看错误日志,是由于lo4j相关的类找不到导致的,这类flink的源码里也有提到,需要我们在pom里引进相关的依赖:
<!-- Including Log4j2 dependencies for tests is required for the embedded Elasticsearch nodes used in tests to run correctly. --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-api</artifactId> <version>2.7</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.7</version> <scope>test</scope> </dependency>引进log4j相关依赖之后,再次运行,仍然会报错:
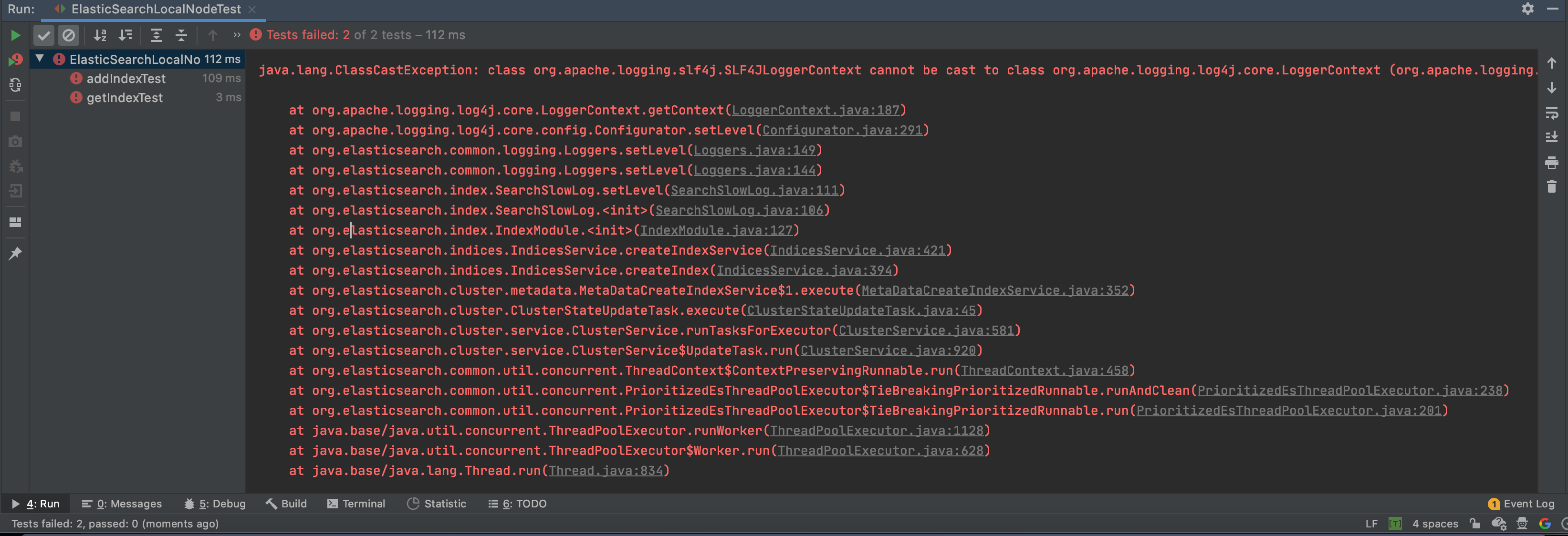
java.lang.ClassCastException: class org.apache.logging.slf4j.SLF4JLoggerContext cannot be cast to class org.apache.logging.log4j.core.LoggerContext (org.apache.logging.slf4j.SLF4JLoggerContext and org.apache.logging.log4j.core.LoggerContext are in unnamed module of loader 'app') at org.apache.logging.log4j.core.LoggerContext.getContext(LoggerContext.java:187) at org.apache.logging.log4j.core.config.Configurator.setLevel(Configurator.java:291) at org.elasticsearch.common.logging.Loggers.setLevel(Loggers.java:149) at org.elasticsearch.common.logging.Loggers.setLevel(Loggers.java:144) at org.elasticsearch.index.SearchSlowLog.setLevel(SearchSlowLog.java:111) at org.elasticsearch.index.SearchSlowLog.<init>(SearchSlowLog.java:106) at org.elasticsearch.index.IndexModule.<init>(IndexModule.java:127) at org.elasticsearch.indices.IndicesService.createIndexService(IndicesService.java:421) at org.elasticsearch.indices.IndicesService.createIndex(IndicesService.java:394) at org.elasticsearch.cluster.metadata.MetaDataCreateIndexService$1.execute(MetaDataCreateIndexService.java:352) at org.elasticsearch.cluster.ClusterStateUpdateTask.execute(ClusterStateUpdateTask.java:45) at org.elasticsearch.cluster.service.ClusterService.runTasksForExecutor(ClusterService.java:581) at org.elasticsearch.cluster.service.ClusterService$UpdateTask.run(ClusterService.java:920) at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:458) at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:238) at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:201) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) at java.base/java.lang.Thread.run(Thread.java:834)这个问题比较有趣,也是当时坑的时间比较长的一个问题。之前有提到提过一个错误java.lang.NoClassDefFoundError: org/apache/logging/log4j/Logger,当发生这个错误时,我们是引入了一个叫log4j-to-slf4j的依赖来解决问题的,它会将log4j的应用路由到slf4j上,但是对于ElasticSearch来说,它内部是使用log4j2,如果我们继续使用log4j-to-slf4j就会导致上述的异常产生,flink的做法是在测试时,将log4j-to-slf4j排除掉,使用maven的maven-surefire-plugin插件将相关依赖排除掉,如下在pom中添加如下插件:
<!-- For the tests, we need to exclude the Log4j2 to slf4j adapter dependency and let Elasticsearch directly use Log4j2, otherwise the embedded Elasticsearch node used in tests will fail to work. In other words, the connector jar is routing Elasticsearch 5.x's Log4j2 API's to SLF4J, but for the test builds, we still stick to directly using Log4j2. --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <configuration> <classpathDependencyExcludes> <classpathDependencyExclude>org.apache.logging.log4j:log4j-to-slf4j</classpathDependencyExclude> </classpathDependencyExcludes> </configuration> </plugin>再次启动单元测试:
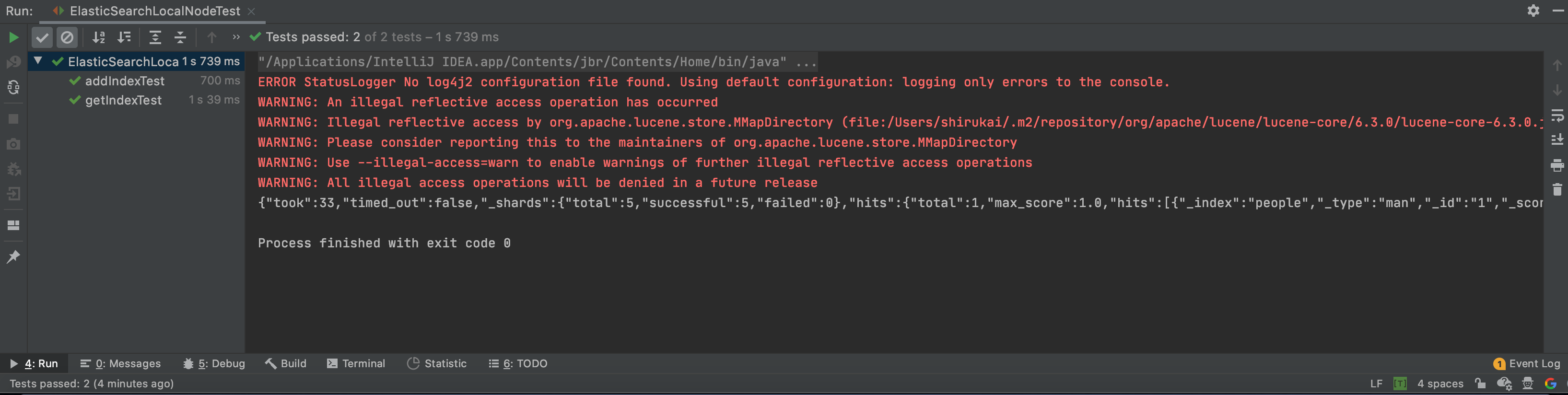
如上图所示,这时我们的测试用例已经跑过,插入的索引已经能够查出来。但是可以只能看到一条ERROR的日志,其它日志显示不出来,看日志内容是说没有找到log4j2相关的配置文件,只会打印ERROR级别的日志:
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.有些同学回说,我的resources下有log4j.properties这个配置文件呀,怎么还报错,这里要注意了,日志是说没有log4j2,2啊,log4j2的配置文件一般为log4j2.xxx,具体配置可以查看官网https://logging.apache.org/log4j/2.x/manual/configuration.html,这里简单配置一下,在resources下添加一个名为log4j2.xml,内容如下:
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss,SSS} %-5p %-60c - %m%n"/> </Console> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="Console"/> </Root> </Loggers> </Configuration>配置日志文件后,再次启动,日志就可以正常输出了。
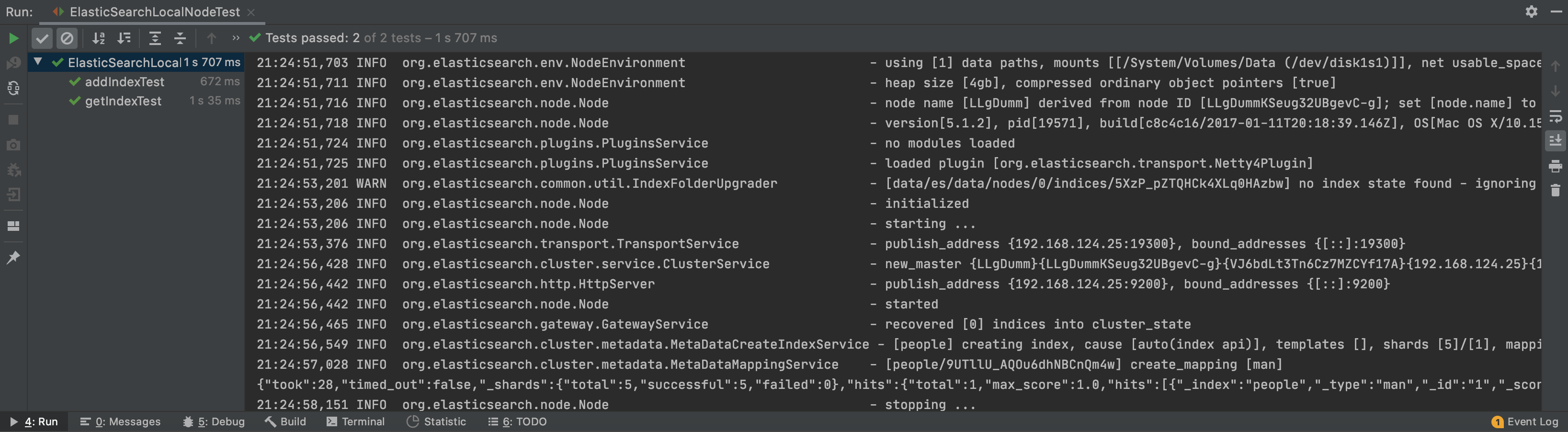
4.2 使用安装包启动ElasticSearch服务
4.2.1 快速入门示例
首先在pom中引入依赖
<!-- Embedded es following Github repository,https://github.com/allegro/embedded-elasticsearch --> <dependency> <groupId>pl.allegro.tech</groupId> <artifactId>embedded-elasticsearch</artifactId> <version>2.10.0</version> </dependency>创建flink.embedded.elasticsearch.examples.EmbeddedEsQuickStartExample类,实现内容如下:
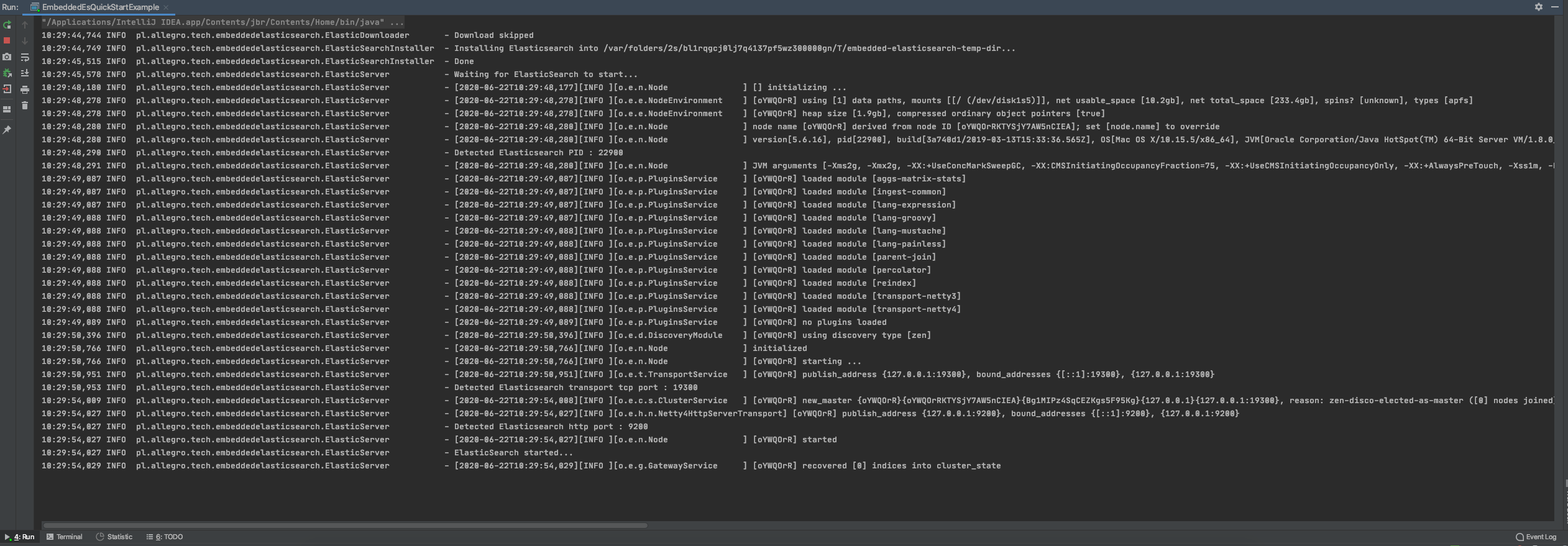
package flink.embedded.elasticsearch.examples; import pl.allegro.tech.embeddedelasticsearch.EmbeddedElastic; import pl.allegro.tech.embeddedelasticsearch.PopularProperties; import java.io.File; import java.io.IOException; /** * 使用第三方依赖实现内置ES集群 * <p>Following Github repository</p> * <a href="https://github.com/allegro/embedded-elasticsearch"> * https://github.com/allegro/embedded-elasticsearch</a> * * @author shirukai */ public class EmbeddedEsQuickStartExample { public static void main(String[] args) throws IOException, InterruptedException { EmbeddedElastic esCluster = EmbeddedElastic.builder() .withElasticVersion("5.6.16") .withSetting(PopularProperties.TRANSPORT_TCP_PORT, 19300) .withSetting(PopularProperties.CLUSTER_NAME, "test-es") .withSetting("http.cors.enabled", true) .withSetting("http.cors.allow-origin", "*") // 安装包下载路径 .withDownloadDirectory(new File("data")) .build(); esCluster.start(); Thread.currentThread().join(); } }执行mian方法,这时会看到如下日志,程序启动后会先根据指定的es版本号,从官网下载对应的安装包。
21:50:35,087 INFO pl.allegro.tech.embeddedelasticsearch.ElasticDownloader - Downloading https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.16.zip to data/elasticsearch-5.6.16.zip ...
这里下载安装包的时候可能会比较慢,如果我们本地有.zip后缀的安装包,可以取消执行,然后直接将本地的安装包拷到我们指定的目录下,比如上面代码指定的项目中的data目录,另外要注意的是,我们拷贝安装包到指定目录之后,一定要再创建一个空文件名为elasticsearch-{版本号}.zip-downloaded,如:
data
├── elasticsearch-5.6.16.zip
└── elasticsearch-5.6.16.zip-downloaded
安装包下载或者拷贝完成之后,再次执行。
4.3 使用Testcontainers启动ElasticSearch服务
Testcontiners是一个Java单元测试库,它能够基于Docker容器启动一个服务实例。详情可以查看官网https://www.testcontainers.org/。这里介绍使用Testcontainers启动ElasticSearch服务,注意前提是机器上要有Docker环境。
4.3.1 快速入门示例
创建flink.embedded.elasticsearch.examples.ContainersEsQuickStartExample类,实现内容如下:
package flink.embedded.elasticsearch.examples; import org.testcontainers.elasticsearch.ElasticsearchContainer; import java.util.Collections; /** * TestContainer启动es快速入门示例 * <a href="https://www.testcontainers.org/modules/elasticsearch/"> * https://www.testcontainers.org/modules/elasticsearch/</a> * * @author shirukai */ public class ContainersEsQuickStartExample { public static void main(String[] args) throws InterruptedException { // Create the elasticsearch container. try (ElasticsearchContainer container = new ElasticsearchContainer("docker.elastic.co/elasticsearch/elasticsearch:5.6.16")) { // Disable x-pack container.setEnv(Collections.singletonList("xpack.security.enabled=false")); // Start the container. This step might take some time... container.start(); // Add shutdown hook Runtime.getRuntime().addShutdownHook(new Thread(container::close)); // 让它阻塞一会吧 Thread.currentThread().join(); } } }确保docker环境可用,然后运行mian方法
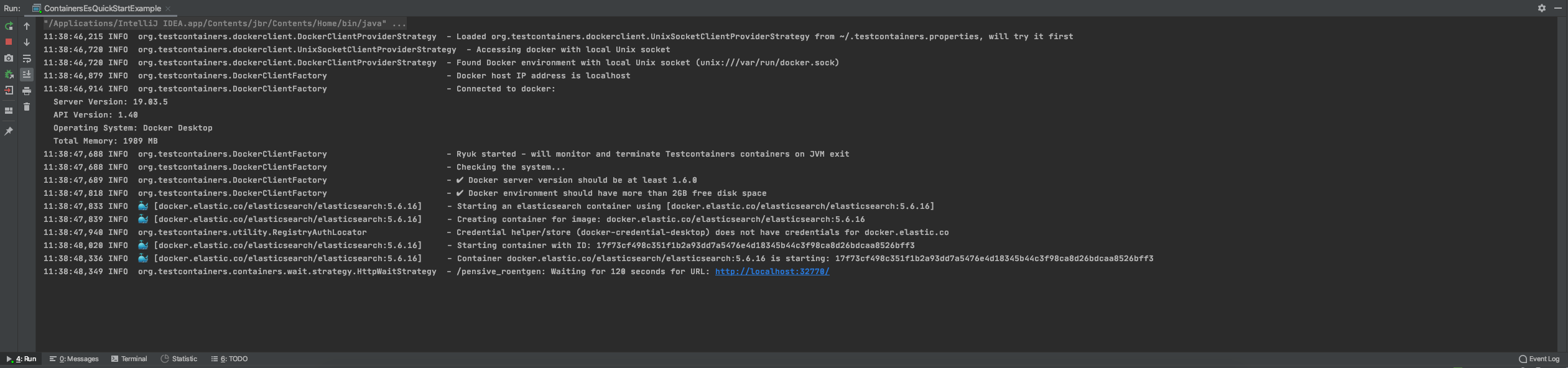
如果报如下错误,这是由于进docker拉取镜像的时候网络抖动导致的,可以尝试先手动将镜像拉取下来:
docker pull docker.elastic.co/elasticsearch/elasticsearch:5.6.16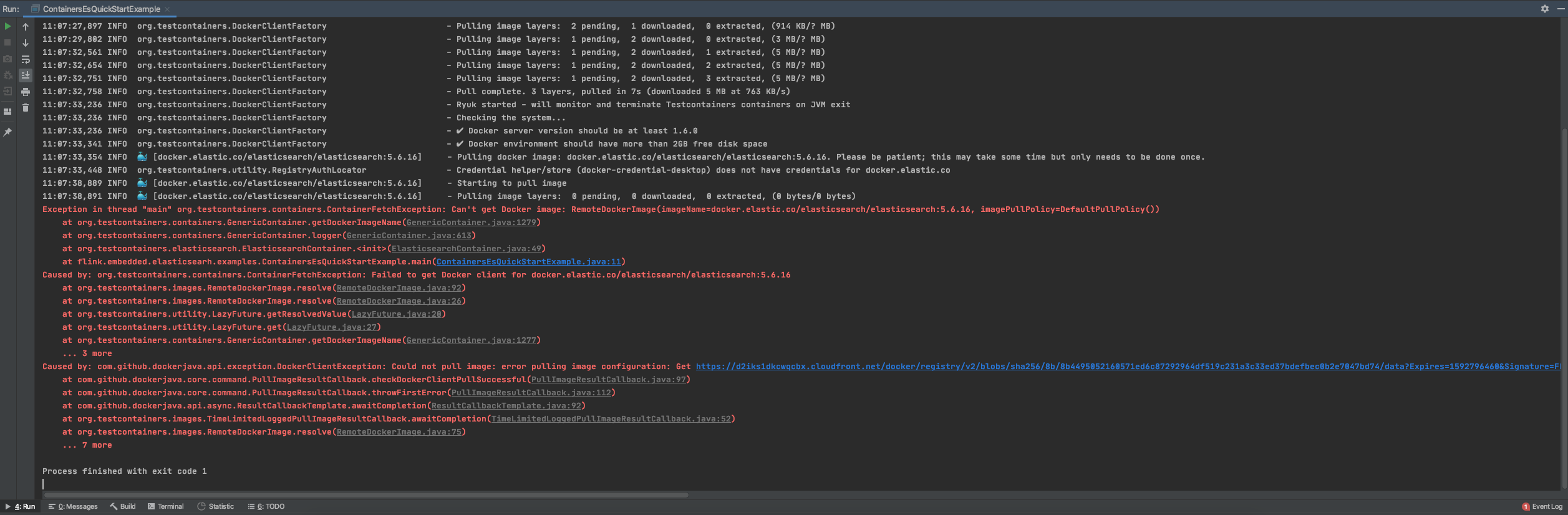
5 Flink任务单元测试
在第4章已经介绍了三种方式启动嵌入式ElasticSearch服务,这章我们进入主题,利用嵌入式的ES对Flink任务进行单元测试。
有了上面4个章节的铺垫,本章节实现起来相对简单多了,这里我们使用内置Node的方式启动一个ES节点实例,来完成我们的单元测试。
创建测试类flink.embedded.elasticsearch.examples.WriteElasticSearchJobTest
package flink.embedded.elasticsearch.examples; import org.apache.flink.configuration.Configuration; import org.apache.flink.runtime.testutils.MiniClusterResourceConfiguration; import org.apache.flink.test.util.MiniClusterWithClientResource; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.Client; import org.elasticsearch.node.NodeValidationException; import org.junit.AfterClass; import org.junit.BeforeClass; import org.junit.ClassRule; import org.junit.Test; /** * 写es单元测试 * * @author shirukai */ public class WriteElasticSearchJobTest { /** * 设置绑定端口 */ private static final Integer ES_BIND_PORT = 19300; /** * 设置集群名称 */ private static final String ES_CLUSTER_NAME = "test-es"; /** * 内置es节点实例 */ private static ElasticSearchLocalNode esNode; /** * 创建Flink mini cluster,当涉及多个flink任务时,可以避免创建多次集群。 * 同时可以通过mini cluster 自定义task数量以及slot的数量。 */ @ClassRule public static MiniClusterWithClientResource flinkMiniCluster = new MiniClusterWithClientResource(new MiniClusterResourceConfiguration .Builder() .setConfiguration(new Configuration()) .setNumberTaskManagers(1) .setNumberSlotsPerTaskManager(1) .build()); @Test public void writeElasticSearchJobTest() throws InterruptedException { String[] args = new String[]{ "--es.cluster.nodes", "127.0.0.1", "-es.cluster.port", ES_BIND_PORT.toString(), "-es.cluster.name", ES_CLUSTER_NAME }; // 提交flink任务 WriteElasticSearchJob.main(args); Client esClient = esNode.client(); Thread.sleep(1000); SearchResponse response = esClient.prepareSearch("events").execute().actionGet(); System.out.println(response.toString()); } /** * 测试类执行前,创建es节点实例 * * @throws NodeValidationException e */ @BeforeClass public static void prepare() throws NodeValidationException { esNode = new ElasticSearchLocalNode.Builder() .setClusterName(ES_CLUSTER_NAME) .setTcpPort(ES_BIND_PORT) .setTempDir("data/es") .build(); esNode.start(); } /** * 测试类执行后,关闭es节点实例 */ @AfterClass public static void shutdown() { if (esNode != null) { esNode.stop(true); } } }运行单元测试
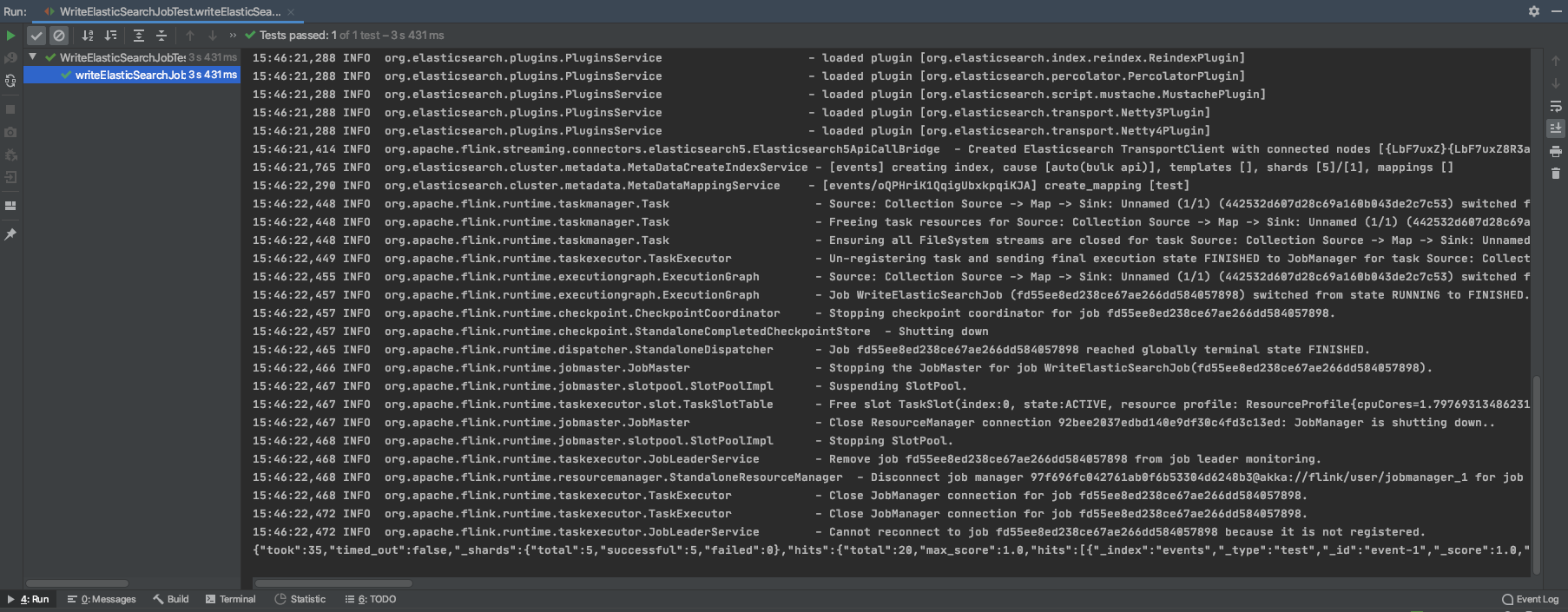
5 总结
使用嵌入式ElasticSearch集群进行单元测试确实能够很好的解决目前的问题,同时也给了我一个新的思路,原来类似这种单元的测试可以使用内置服务的方式进行,让我从想尽办法mock类的坑中爬了出来。简单总结一下文章中提到的三种方式:
- 第一种启动单个Node,优点:无需额外的依赖,内置client可以直接使用 缺点:使用时坑比较多,比如日志的问题,同时官方是不建议我们使用这种方式的查看https://github.com/elastic/elasticsearch/issues/19930
- 第二种使用安装包启动ElasticSearch服务,优点:入门简单,版本可以指定,缺点:需要引入第三方依赖,需要Es的安装包
- 第三种Testcontainers启动ElasticSearch服务,优点:入门简单,版本可指定,缺点:需要Docker环境
其实我个人还是比较倾向于第一种方式的,虽然坑多,但是踩过了就不怕了。最后感慨一下吧,遇到问题一定要多想多看,不要一条路走到黑。
项目代码已经更新到Github上了,欢迎大家有问题一起交流。
