版本说明:
Python:3.7
Flask:1.0.2
前言
Flask是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 ,具体详情查看官网:http://flask.pocoo.org/。
接触Flask有一段时间了,在工作中使用Flask开发了几个轻量级的后台服务,相比较Django框架,Flask更加的轻量,为渐进式框架,适合快速开发。这里不做深入的源码研究,只是记录一下在工作中使用Flask的经验技巧,从0到1快速进行后台开发。
1 环境准备
1.1 Conda创建Python开发环境
这里为方便演示,使用conda创建一个名字为flask,版本为3.5的新环境。如果没有安装conda,可以从官网下载安装即可,conda官网地址:https://www.anaconda.com/。
conda create --name flask python=3.7
1.2 创建Flask项目
使用PyCharm创建一个名为flask-demo的项目,并选择我们刚才创建的python环境。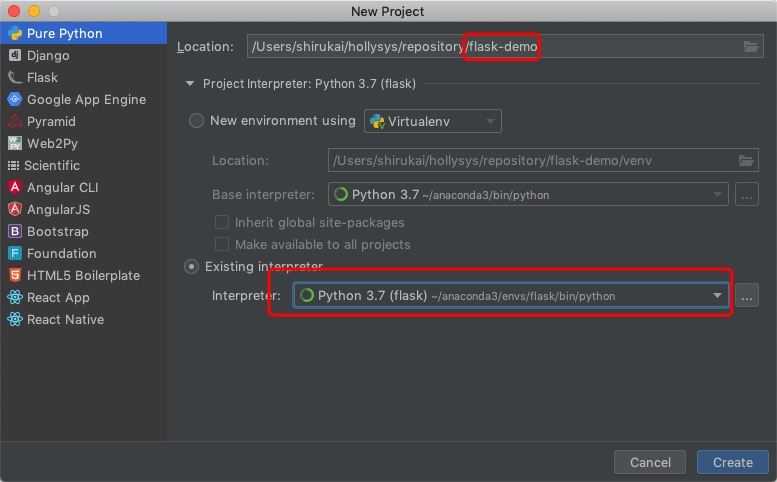 。
。
1.3 安装Flask
flask可以使用python的pip直接安装,新版PyCharm选择Interpreter之后,点击Terminal可以直接切换到该环境。
pip install flask==1.0.2
2 快速创建一个Web服务
使用Flask创建一个web服务很简单,只需要通过Flask()创建一个Flask实例app,然后通过app.route()装饰器设置路由方法,最后通过app.run()启动内置的开发服务器即可。下面创建一个名为simple_app.py的python的文件,内容如下:
from flask import Flask
# create a flask app
app = Flask(__name__)
@app.route("/")
def index():
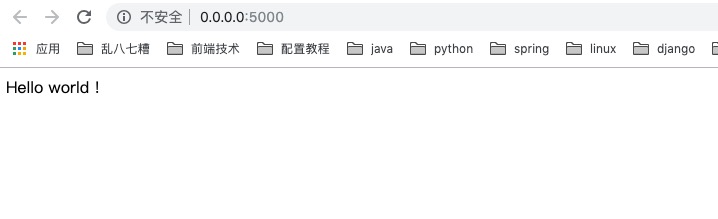
return "Hello world !"
if __name__ == '__main__':
# run server
app.run(host="0.0.0.0", port=5000)
右击运行main方法即可启动服务,访问http://0.0.0.0:5000/
3 Flask请求处理
上面我们已经启动了一个简单的服务,在web服务里有个关键的地方就是对请求的处理,如:获取请求信息,返回请求结果等。
3.1 指定路由请求类型
常见的请求类型:GET、POST、PUT、DELETE、PATCH等等,Flask允许我们指定某个请求可以通过哪些类型进行访问。可以在路由装饰器中传入methods需要的参数,该参数是一个列表,如只允许GET请求,可以设置methods=[‘GET’],如允许GET和POST,可以设置methods=[‘GET’,’POST’]。如设置下面/methods这个路由只允GET请求类型的访问。
@app.route("/methods", methods=["GET"])
def methods():
return "Only allow GET request types"
3.2 获取请求参数
请求传参有很多方法,可以通过URL直接传参、通过body传参、Header、Cookie、Session等。Flask中关于请求相关的上下文信息,保存在两个对象里,一个是request里,另一个是session里。我们可以从这两个对象里获取所有我们想要获取的参数。如下源码所示:
# context locals
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, 'request'))
session = LocalProxy(partial(_lookup_req_object, 'session'))
g = LocalProxy(partial(_lookup_app_object, 'g'))
引入对象:
from flask import request
from flask import session
这里做点补充,上面提到Flask的上下文信息,从源码中我们可以看出,除了request对象和session对象之外,flask还提供了current_app和g两个对象。
| 变量名称 | 上下文 | 说明 |
|---|---|---|
| current_app | 应用上下文 | 当前Flask应用的应用实例 |
| g | 应用上下文 | 处理请求时用作临时存储的对象,每次请求都会重设这个变量 |
| requset | 请求上下文 | 请求对象,分装了客户端发出的HTTP请求中的内容 |
| session | 请求上下文 | 用户会话,值作为一个字典,存储请求之前需要”记住”的值 |
request请求对象
| 属性或方法 | 说明 |
|---|---|
| form | 字典,存储请求提交的所有表单数据 |
| args | 字典,存储通过URL传递的所有参数 |
| values | 字典,form和args的合集 |
| cookies | 字典,存储请求的所有cookie |
| headers | 字典,存储请请的所有HTTP首部 |
| files | 字典,存储请求上传的所有文件 |
| get_data() | 返回请求主题缓冲的数据 |
| get_json() | 返回一个Python字典,包含解析请求body后得到的JSON |
| blueprint | 蓝图名称 |
| endpoint | 处理请求的Flask端点名称,Flask把视图函数的名称称作路由端点的名称 |
| method | HTTP请求方法,例如GET\POST |
| scheme | URL方案(http活https) |
| is_secure() | 通过安全的连接(HTTPS)发送请求时返回True |
| host | 请求主机的主机名,如客户端定义了端口号,还包括端口号 |
| path | URL的路径部分 |
| query_string | URL的查询参数部分,如:?name=joke&age=18 |
| full_path | URL的路径和查询参数部分 |
| url | 客户端请求的完整URL |
| base_url | 同url,但没有查询字符串部分 |
| remote_addr | 客户端的IP地址 |
| environ | 请求的原始WSGI环境字典 |
3.2.1 获取URL上的参数
对于url上参数,例如/params/url?name=joke,我们要想获取参数,可以使用request.args方法获取一个ImmutableMultiDict类型的参数列表,也可以通过get方法直接获取该参数的值,如下所示:
@app.route("/params/url")
def params_url():
print(request.args)
print(request.args.get("name"))
return ""
url上的参数除了?和&传参之外,也支持RESTFul风格的动态传参,如/params/rest/<id>,类似<id>这样的动态参数,默认解析为string类型,当然我们可以指定其它类型,如指定id为int类型,只是匹配整型的url,如/rest/1。Flask支持的类型:string、int、flot和path类型,path类型是一种特殊的字符串,与string类型不同的是,它可以包含正斜线。
@app.route("/params/rest/", defaults={'id': '1'})
@app.route("/params/rest/<id>")
def params_rest(id):
return jsonify({"id": id})
如上代码,我们可以通过defaults设置默认值,设置id默认值为1。当我们访问http:xxxx:5000/params/rest时会返回如下结果:
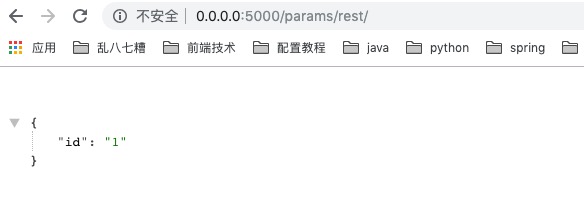
同样可以传入参数,如我们访问http:xxxx:5000/params/rest/2时会返回如下结果:

3.2.2 获取body里的参数
对于body里的数据,我们可以使用request.data直接获取bytes(在python2中返回的是str类型,类python3中返回的是bytes,并且要注意在python3.5之前,json.loads(str)里支持传入str类型,不支持bytes)类型数据,让后根据content_type进行相应的类型转换。如下所示,判断content_type是否为application/json,然后将其转为json格式
@app.route("/params/body", methods=['POST'])
def params_body():
print(request.content_type)
if request.content_type == 'application/json':
print(json.loads(request.data))
return ""
另外,如果我们直道请求参数的类型是json,可以直接使用request.json直接获取json类型的数据
print(request.json)
注意:通过request.json或者request.get_json()得到的json数据可能会乱序。建议使用request.data,然后通过json.loads()获取json,如下所示:
conf = json.loads(data, encoding='UTF-8', object_pairs_hook=OrderedDict)
3.2.3 获取表单数据
对于form表单数据,我们可以使用request.form获取一个ImmutableMultiDict类型的参数列表,然后根据参数名获取参数值
@app.route("/params/form", methods=['POST'])
def params_form():
print(request.form)
print(request.form['name'])
return ""
3.2.4 获取文件格式
对于文件格式的参数,我们可以是用request.files获取一个参数列表,然后根据文件参数名获取某个文件,如request.files[‘flie’]。
@app.route("/params/file", methods=['POST'])
def params_file():
file = request.files['file']
# get file type
print(file.content_type)
# get file name
print(file.filename)
# save file by bytes
with open(file.filename, 'wb') as f:
f.write(file.stream.read())
return ""
如上代码,我们可以使用file.stream.read()读取字节类型的数据,然后将其写出到文件。同样也可以使用file.save(路径)方法写出文件
# save file by method
file.save(file.filename)
3.3 返回请求响应
通常我们的请求响应不过几种,返回一个页面,返回一个json字符串,返回一个文件。对于Flask的响应,我们可以直接返回1个参数作为内容,如
return "hello world!"
也可以返回2个参数,第二个参数为响应的状态码,如
return "hello world!",400
也可以返回3个参数,第三个参数为响应的头信息,参数以字典的形式指定,如
return "hello world!",400,{"Server":"Werkzeug/0.15.2 Python/2.7.16"}
也可以通过make_reponse()方法自定义响应对象,后面会提到。
Flask响应对象
| 属性和方法 | 说明 |
|---|---|
| status_code | HTTP 数字状态码 |
| headers | 一个类似字典的对象,包含响应发送的所有首部 |
| set_cookie() | 为响应添加一个cookie |
| delete_cookie() | 删除一个cookie |
| content_length | 响应主体的长度 |
| content_type | 响应主体的媒体类型 |
| set_data() | 使用字符串或字节值设定响应 |
| get_data() | 获取响应主体 |
3.3.1 返回一个页面
要想要flask返回一个页面,只需要return render_template(“模板名”,**参数)即可,比如我在templates目录下有一个名为index.html的模板文件,模板引擎是Jinja2,相关语法可以百度。内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Index</title>
</head>
<body>
<h1>Hello {{ name }} !</h1>
</body>
</html>
我可以通过render_template方法进行渲染并返回。
@app.route("/")
def index():
return render_template("index.html", **{"name": "joke"})
3.3.2 返回json格式
要想flask返回json格式数据,可以使用flask提供的jsonify方法格式化之后返回。
@app.route("/params/json", methods=['GET'])
def params_json():
return jsonify({"name": "joke"})
注意使用jsonify返回的json是会自动排序的,如果不想排序,可以使用
Response(json.dumps({"name": "joke"}), mimetype='application/json')
3.3.3 返回文件
要想flask返回文件,即文件下载,可以使用flask提供的send_file()方法
@app.route("/download", methods=['GET'])
def download():
return send_file("test.gif", as_attachment=True)
3.3.4 自定义响应
Flask给我提供了一个Response类,可以方便我们自由设置响应,如设置状态码、设置返回内容、设置header等等。我们可以通过两种方式创建response对象,实例化Response()类,或者通过make_response(body,status,headers)方法。
Response(response=None,
status=None,
headers=None,
mimetype=None,
content_type=None,
direct_passthrough=False,)
make_response(body=None,
status=None
,headers=None)
使用make_response()方法
@app.route("/response", methods=['GET'])
def response_test():
data = {
"test": "123"
}
# res = Response(data)
res = make_response(json.dumps(data), 500, {'Content-Type': 'application/json'})
return res
使用Response()
@app.route("/response", methods=['GET'])
def response_test():
data = {
"test": "123"
}
res = Response(data,status=500,headers={'Content-Type': 'application/json'})
#res = make_response(json.dumps(data), 500, {'Content-Type': 'application/json'})
return res
3.5 cookie的获取与设置
上面讲过,Flask关于请求的信息大多封装到了request里,同样cookie信息也是保存到了request里。
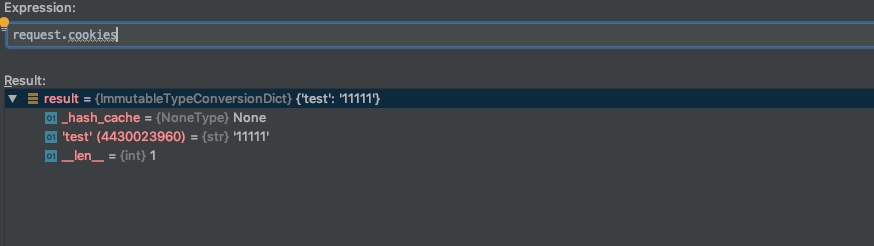
3.5.1 获取cookie
cookie获取如上图所示,通过request.cookies就可以获取一个字典对象,里面包含了cookie信息。
requset.cookies['test']
3.5.2 设置cookie
在上文中的response对象的属性和方法表格中,提到有set_cookie()方法,这个方法就是用来设置cookie的,那么该方法如何使用,需要如何传参呢?先看一下源码。
def set_cookie(
self,
key,
value="",
max_age=None,
expires=None,
path="/",
domain=None,
secure=False,
httponly=False,
samesite=None,
):
pass
参数说明:
| 参数名称 | 说明 |
|---|---|
| key | 设置cookie的key |
| value | 设置cookie的value |
| max_age | 设置最大过期时长,单位秒,多少秒之后过期,默认为None |
| expires | 设置过期时间,什么时间点过期,可以设置datatime对象或者时间戳 |
| path | 将cookie限制为给定路径,默认情况下它将跨越整个域 |
| domain | 设置cookie的域范围,如果想设置跨域cookie,如设置domain=’.example.com’,允许’www.example.com'和'foo.example.com'等类似的域访问。否则,cookie只能由设置的域访问。 |
| secure | 如果设为“True”,则cookie只能通过HTTPS获得 |
| httponly | 禁止JavaScript访问cookie。这是cookie标准的扩展,可能并非所有浏览器都支持 |
| samesite | 限制cookie的范围,使其仅在请求是“同一站点”时附加到请求 |
使用:
@app.route("/response", methods=['GET'])
def response_test():
data = {
"test": "123"
}
res = Response(data, status=500, headers={'Content-Type': 'application/json'})
res.set_cookie("test_key", "test_value", max_age=20)
return res;
3.5.3 删除cookie
删除cookie使用delete_cookie(key)即可。
3.6 session的获取与设置
session在flask中是一个神奇的存在,它的本质其实就是经过加密的cookie。所以要想使用session,我们需要给flask设置盐值秘钥SECRET_KEY,flask使用它来进行加密解密。设置SECRET_KEY可以直接在app配置中添加config,如:
app.config['SECRET_KEY']='xxxxx'
上文中也有提及,flask提供了几种上下文对象,其中session也被作为单独的上下文对象在flask应用中提供,通过下面方式,拿到该对象。
from flask import session
对于session的操作,类似于操作字典,可以使用如下方法和属性
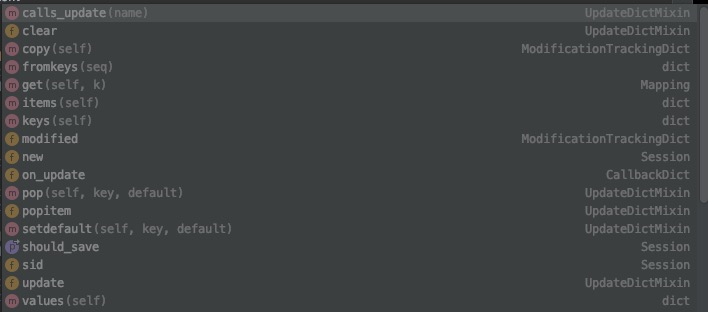
3.6.1 获取session
获取session有两种方式,直接获取
session['session_key']
这种方式,有种弊端,当session_key对应的session不存在时,会报异常。可以使用get()方法获取
session.get('session_key')
这种方式,不会抛出异常,如果不存在会返回None。
3.6.2 设置session
设置session我们可以像给字典赋值一样,给session赋值。
session['session_key']='session_value'
3.6.3 删除session
删除session我们可以使用pop()方法
session.pop('session_key')
3.6.4 清空所有session
要想清空session,可以使用clear()方法
session.clear()
3.6.5 设置session过期时间
在Flask中session的过期机制是这样的,如果没有设置sesion过期时间,那么默认浏览器关闭时销毁session。我们可以通过设置permanent参数为True,来延长过期时间,默认为31天,当然我们也可以通过给app.config设置PERMANENT_SESSION_LIFETIME来更改过期时间,这个值的数据类型是datetime.timedelay类型。
设置session为31天
session['session_key']='session_value'
session.permanent=True
自定义时长
app.config['PERMANENT_SESSION_LIFETIME'] = timedelta(days=7)
3.7 请求钩子
讲完了请求和响应,这里补充一下flask中的几种请求钩子,钩子的作用很常见,比如我们需要在执行某个请求之前,或者之后进行一些逻辑处理。Flask提供的钩子是通过装饰器实现,提供如下四种钩子。
- before_request:注册一个函数,在每次请求之前执行。
- before_first_request:注册一个函数,只在处理第一个请求之前运行。可以通过这个钩子添加服务器初始化任务。
- after_request:注册一个函数,如果没有未处理的异常抛出,在每次请求之后运行。
- teardow_request:注册一个函数,即使有未处理的异常抛出,也在每次请求之后运行。
4 Flask蓝图
蓝图官网介绍:https://dormousehole.readthedocs.io/en/latest/blueprints.html
关于Flask蓝图的描述,这里就不做介绍,简单来书,蓝图可以方便我们将一个项目进行模块化,详细介绍可以参考官网。在项目中,主要是使用蓝图进行版本区分,比如v1版、v2版。
4.1 创建蓝图
下面我们创建一个名为v1的蓝图,并添加应用前缀:/api/v1
from flask import Blueprint, jsonify
v1_blueprint = Blueprint("v1", __name__, url_prefix="/api/v1")
@v1_blueprint.route("/", defaults={'id': '1'})
@v1_blueprint.route("/<id>")
def show_id(id):
return jsonify({'id': id})
4.2 注册蓝图
将蓝图注册到Flask应用
from v1 import v1_blueprint
# create a flask app
app = Flask(__name__)
# register blueprint
app.register_blueprint(blueprint=v1_blueprint)
访问:http://0.0.0.0:5000/api/v1/
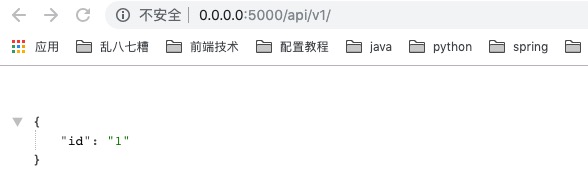
5 自定义Flask红图
如果说蓝图是将一个项目按照应用来模块化,那么我们可以使用红图将每个应用按照功能进行模块化。蓝图是Flask原生就提供的,但是红图需要我们自己来实现,红图是在蓝图的基础做的进一步细分。红图的概念,是参考网上资料实现的。那么红图有什么应用场景呢,比如上述我们定义的v1蓝图下面,我们要按照功能再次进行模块细分,分为普通用户模块和管理员模块,这时候我们就可以使用红图了。
5.1定义红图插件
创建一个lib目录,然后创建redprint.py文件,最后创建如下类
class Redprint:
def __init__(self, name):
self.name = name
self.mound = []
def route(self, rule, **options):
def decorator(f):
self.mound.append((f, rule, options))
return f
return decorator
def register(self, bp, url_prefix=None):
if url_prefix is None:
url_prefix = "/" + self.name
for f, rule, options in self.mound:
endpoint = options.pop("endpoint", f.__name__)
bp.add_url_rule(url_prefix + rule, endpoint, f, **options)
5.2 创建红图
创建api/v1/admin包,并创建endpoint.py文件,内容如下:
from flask import jsonify
from lib.redprint import Redprint
# create redprint
admin_redprint = Redprint("admin")
@admin_redprint.route("/")
def admin():
return jsonify({"type": "admin"})
创建api/v1/user包,并创建endpoint.py文件,内容如下:
from flask import jsonify
from lib.redprint import Redprint
# create redprint
user_redprint = Redprint("user")
@user_redprint.route("/")
def user():
return jsonify({"type": "user"})
目录结构如下图所示:
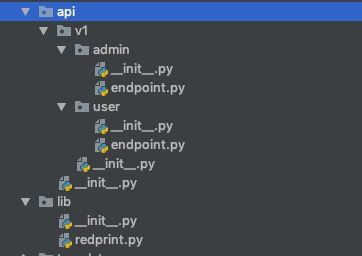
5.3 注册红图
在/api/v1/包下的_init_.py文件里注册红图,需要先创建blueprint然后注册到红图。
from flask import Blueprint
from api.v1.admin.endpoint import admin_redprint
from api.v1.user.endpoint import user_redprint
def create_blueprint_v1():
# create blueprint
v1_blueprint = Blueprint("v1", __name__, url_prefix="/api/v1")
# register redprint
admin_redprint.register(bp=v1_blueprint, url_prefix="/admin")
user_redprint.register(bp=v1_blueprint, url_prefix="/user")
return v1_blueprint
5.4 注册蓝图
蓝图的注册方式,与之前方式相同,只不过蓝图,需要通过create_blueprint_v1()方法创建。
# register blueprint by redprint
app.register_blueprint(blueprint=create_blueprint_v1())
5.5 测试红图
启动应用,访问http://localhost:5000/api/v1/user/
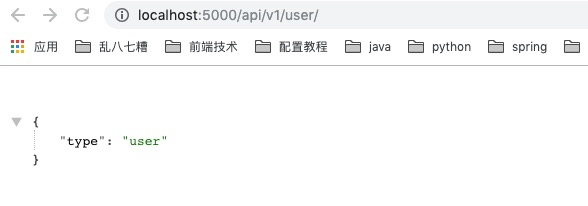
访问http://localhost:5000/api/v1/admin/
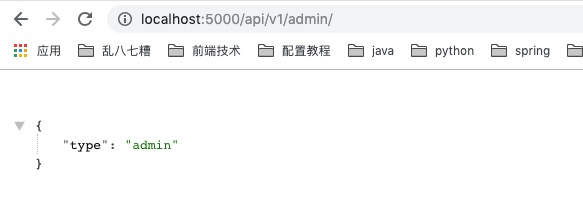
由上图可以看出,我们定义的红图可以生效。
6 ORM插件 Flask-SQLAlchemy
通过上面几个小节,我们已经可以快速的创建一个web服务,能够处理简单的请求并返回相应的内容。而且可以使用蓝图和红图,模块化项目,使项目结构更加清晰。接下来将进一步深入,Flask使用Flask-SQLAlchemy插件对数据库进行CRUD操作。这里不对Flask-SQLAlchemy进行深入研究,详细API可以参考官网https://flask-sqlalchemy.palletsprojects.com/en/2.x/。
6.1 安装Flask-SQLAlchemy
使用pip安装flask-sqlalchemy
pip install flask-sqlalchemy -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
6.2 Flask应用加载SQLAlchemy
6.2.1 配置数据库
为了方便演示,这里使用轻量级数据库sqlite作为演示数据库。假设数据库文件在当前目录,名为test.db。简单配置如下:
# config db
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///test.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
详细配置项可以参考:http://www.pythondoc.com/flask-sqlalchemy/config.html
6.2.2 创建DB实例
创建SQLAlchemy实例,首先创建database包,然后在_init_.py包里创建DB实例,如下代码所示:
# create db from app
db = SQLAlchemy()
6.2.3 创建表模型
因为是ORM框架,类似Spring JPA,框架可以根据实体类进行关系映射。在Python里也是通过类型进行映射,所以首先我们要创建模型类。关于模型创建以及模型关系,可以参考官网:http://docs.jinkan.org/docs/flask-sqlalchemy/models.html。如我们要创建一个User表,里面有id、name、age三个属性,在database包下创建一个models.py的文件,然后创建类如下:
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(80), unique=True, nullable=False)
age = db.Column(db.Integer)
def __init__(self, id, name, age):
self.id = id
self.name = name
self.age = age
def dict(self):
return {
"id": self.id,
"name": self.name,
"age": self.age
}
def __repr__(self):
return 'User %r' % self.name
6.2.4 初始化数据库
数据库初始化之前需要将SQLAlchemy实例与Flask进行整合
# init db
db.init_app(app)
Flask启动时如果表不存在自动创建
# crate db table
with app.app_context():
db.create_all()
如下所示,重启应用后表自动创建了。

6.2.5 基本的CURD操作
上面我们已经将SQLAlchemy整合到Flask里了,那么我们如果对数据库进行增删改查操作呢,相面将简单演示一下。详细内容可以查看:http://www.pythondoc.com/flask-sqlalchemy/queries.html
6.2.5.1 新增记录
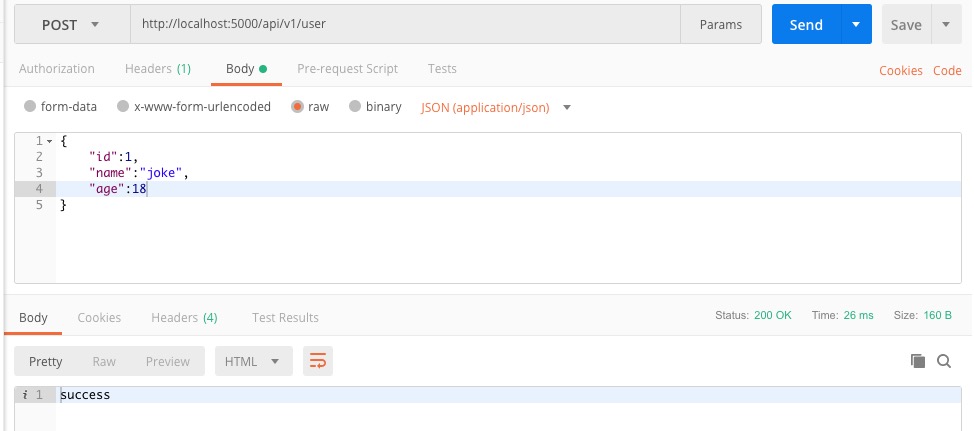
上面我们创建了一张User表,现在我们向这张表里插入一条记录,该如何操作?继续上面红图里的/api/v1/user/endpoint.py。接收一个POST请求,获取请求参数id、name、age的值然后插入数据库,如下代码所示:
@user_redprint.route("", methods=['POST'])
def add_user():
data = request.get_json()
u = User(data['id'], data['name'], data['age'])
db.session.add(u)
db.session.commit()
return "success"
PostMan测试请求:
6.2.5.2 查询记录
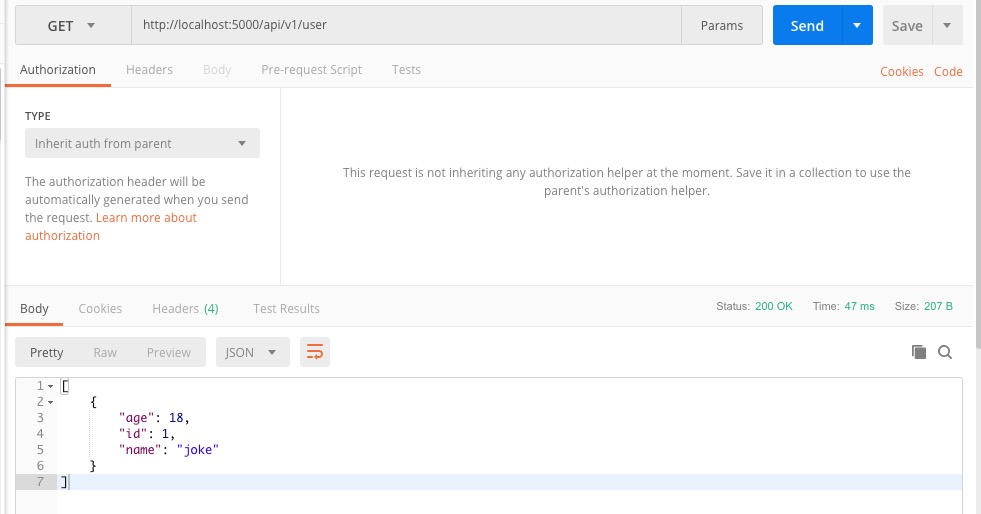
上面我们已经能够插入一条记录了,那么我们如何能查询到刚才查询的记录呢。如下代码为查询所有记录
@user_redprint.route("", methods=['GET'])
def get_users():
users = User.query.all()
return jsonify([user.dict() for user in users])
PostMan测试请求
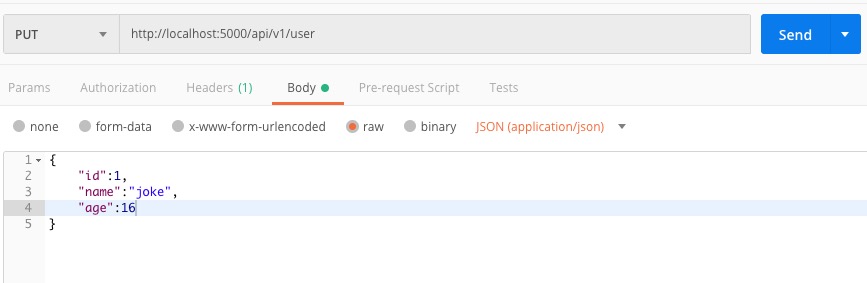
6.2.5.3 更新记录
上面提到新增一条记录用session.add(),其实更新一条记录也可以用add,如下代码所示:
@user_redprint.route("", methods=['PUT'])
def update_user():
data = request.get_json()
u = User.query.filter(User.id == data['id']).one_or_none()
u.name = data['name']
u.age = data['age']
db.session.add(u)
db.session.commit()
return "success"
PostMan请求
6.2.5.4 删除记录
添加记录用session.add,那么删除记录,我们可以用session.delete。如下代码所示,根据名字删除记录
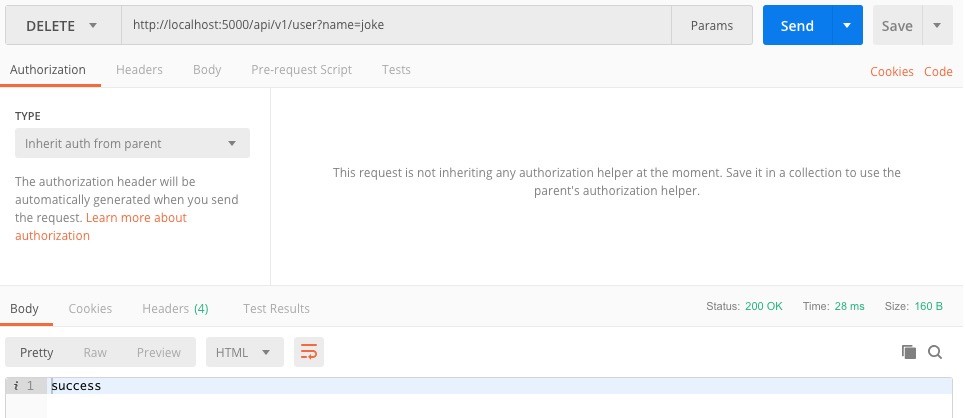
@user_redprint.route("", methods=['DELETE'])
def delete_user():
name = request.args.get("name")
u = User.query.filter(User.name == name).first()
db.session.delete(u)
db.session.commit()
return "success"
PostMan请求
7 定时调度插件Flask-APScheduler
前面记录了Flask对请求的处理以及数据库的CRUD操作,已经能完成一个简单的后台开发了。下面将进行一些扩展,定时任务。相信在平时的项目里经常会用到定时任务,在Java里我们我们可以使用Quartz,它能与Spring很好的整合。对于Python里可以使用APScheduler,官网文档:https://apscheduler.readthedocs.io/en/latest/。而Flask-APScheduler是对APScheduler的封装扩展,使其能与Flask更好的融合。提起这个插件,我有些许头疼,竟没找到详细的官方文档,只定位到了Git仓库的地址:https://github.com/viniciuschiele/flask-apscheduler,而且查某度和Google得到的文章几乎千篇一律,没有详细的介绍。其实Flask-APScheduler的使用与APScheduler类似,这里就花一点时间,整理汇总一下,我对于Flask-APScheduler插件的使用记录。本节将从以下几个方面进行整理:APScheduler特性、动态管理定时任务、定时的几种方式、执行器的配置、持久化定时任务。
7.1 Flask-APScheduler特性
从Git的README可以看出,APScheduler有一下几个特性:
- 从Flask的配置中加载scheduler配置
- 从Flask的配置中加载定义的的定时任务
- 允许指定调度程序将在其上运行的主机名
- 提供REST API 去管理调度任务
- 为REST API 提供权限认证
下面将详细的落地这些特性。
7.1.1 特性一:从Flask的配置中加载scheduler配置
意思就是说,关于scheduler的配置,是从Flask应用的上下文中获取的,也就是说,配置是统一在Flask应用中指定的,即通过app.config指定的。如我们在config/目录下创建一个scheduler.py文见用来存放关于Flask-APScheduler相关的配置。简单添加一个Executors的配置,关于Executors的详细配置,在后面后详细讲解。
class SchedulerConfig(object):
SCHEDULER_EXECUTORS = {
'default': {'type': 'threadpool', 'max_workers': 20}
}
将配置添加到Flask应用
app.config.from_object(SchedulerConfig)
创建调度器
# create scheduler
scheduler = APScheduler()
初始化调度器
# init scheduler
scheduler.init_app(app=app)
scheduler.start()
7.1.2 特性二:从Flask的配置中加载定义的的定时任务
该特性意思是可以从配置中加载事先定义好的定时任务,比如我有一个print_test(name)方法,每隔1秒打印一下name,代码如下:
def print_test(name):
print(name)
在SchedulerConfig类中添加如下配置:
JOBS = [
{
'id': 'job1',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': 'interval',
'seconds': 1
}
]
启动测试:
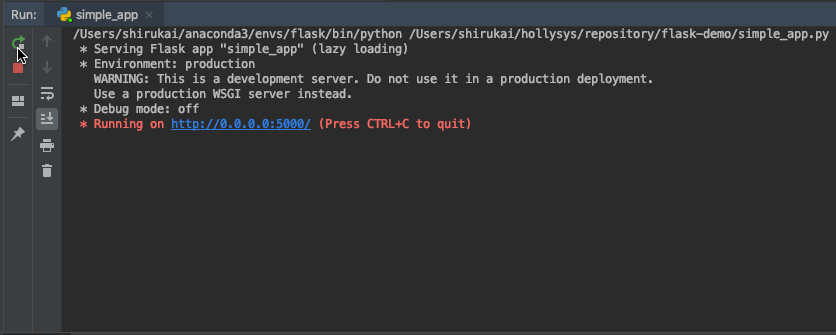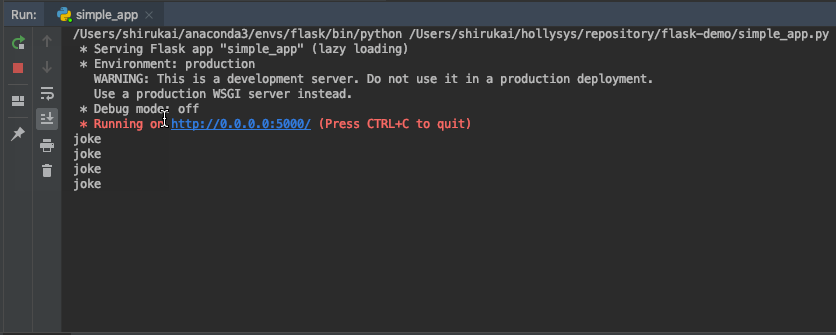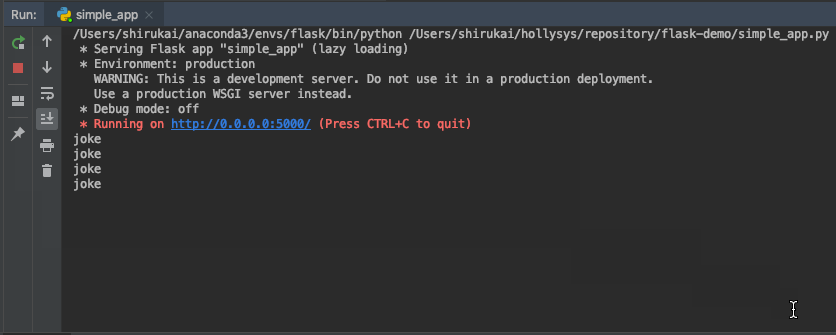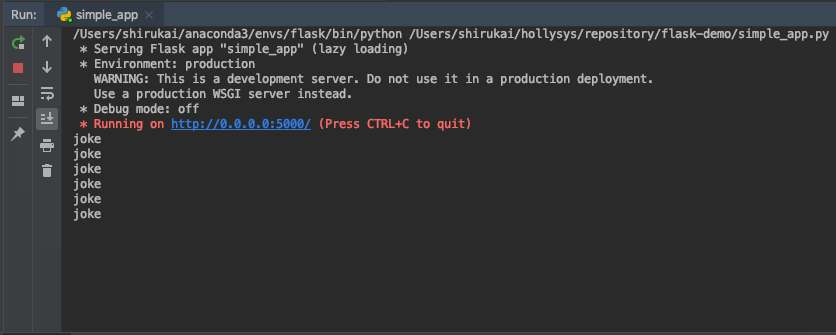
7.1.3 特性三:允许指定调度程序将在其上运行的主机名
默认Flask-APScheduler允许在所有的主机名上运行,即
SCHEDULER_ALLOWED_HOSTS = ['*']
我们可以通过修改该参数,限制允许执行的主机名,比如我当前的主机名为shirukaideimac.local,我设置SCHEDULER_ALLOWED_HOSTS=[‘localhost’],那么调度程序将不会执行。
7.1.4 特性四:提供REST API 去管理调度任务
Flask-APScheduler 提供REST API方便我们去管理调度任务。但是需要我们手动开启,在配置中添加如下配置
SCHEDULER_API_ENABLED=True
重启服务,访问http://localhost:5000/{api_prefix}即可得到scheduler的基本信息。这里api_prefix默认为scheduler,可以通过SCHEDULER_API_PREFIX参数进行自定义。
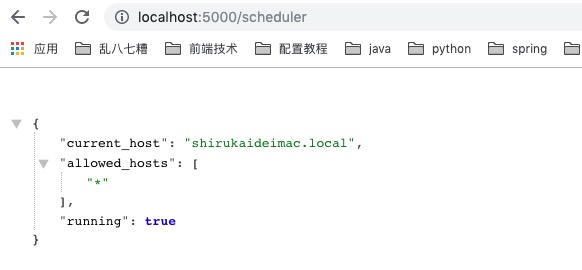
关于Flask-APScheduler提供了哪些REST API,可以在flask_apscheduler/scheduler.py里查看,代码如下:
def _load_api(self):
"""
Add the routes for the scheduler API.
"""
self._add_url_route('get_scheduler_info', '', api.get_scheduler_info, 'GET')
self._add_url_route('add_job', '/jobs', api.add_job, 'POST')
self._add_url_route('get_job', '/jobs/<job_id>', api.get_job, 'GET')
self._add_url_route('get_jobs', '/jobs', api.get_jobs, 'GET')
self._add_url_route('delete_job', '/jobs/<job_id>', api.delete_job, 'DELETE')
self._add_url_route('update_job', '/jobs/<job_id>', api.update_job, 'PATCH')
self._add_url_route('pause_job', '/jobs/<job_id>/pause', api.pause_job, 'POST')
self._add_url_route('resume_job', '/jobs/<job_id>/resume', api.resume_job, 'POST')
self._add_url_route('run_job', '/jobs/<job_id>/run', api.run_job, 'POST')
这里简单总结一下:
7.1.4.1 获取调度信息
API: /{api_prefix}
请求类型:GET
请求参数:无
描述:获取调度信息
结果:
{
"current_host": "shirukaideimac.local",
"allowed_hosts": [
"*"
],
"running": true
}
7.1.4.2 获取所有job列表
API: /{api_prefix}/jobs
请求类型:GET
请求参数:无
描述:获取所有的job
结果:
[
{
"id": "job1",
"name": "job1",
"func": "config.scheduler:print_test",
"args": [
"joke"
],
"kwargs": {},
"trigger": "interval",
"start_date": "2019-05-21T17:43:32.105979+08:00",
"seconds": 1,
"misfire_grace_time": 1,
"max_instances": 1,
"next_run_time": "2019-05-21T17:52:25.105979+08:00"
}
]
7.1.4.3 新增job
API: /{api_prefix}/jobs
请求类型:POST
请求参数:
{
"id":"job2",
"func":"config.scheduler:print_test",
"args":["linda"],
"trigger":"interval",
"seconds":5
}
描述:新增定时任务
结果:
{
"id": "job2",
"name": "job2",
"func": "config.scheduler:print_test",
"args": [
"linda"
],
"kwargs": {},
"trigger": "interval",
"start_date": "2019-05-21T17:46:27.750697+08:00",
"seconds": 5,
"misfire_grace_time": 1,
"max_instances": 1,
"next_run_time": "2019-05-21T17:46:27.750697+08:00"
}
7.1.4.4 获取某个job信息
API: /{api_prefix}/jobs/{job_id}
请求类型:GET
请求参数:job_id
描述:获取某个job的信息
结果:
{
"id": "job2",
"name": "job2",
"func": "config.scheduler:print_test",
"args": [
"linda"
],
"kwargs": {},
"trigger": "interval",
"start_date": "2019-05-21T17:46:27.750697+08:00",
"seconds": 5,
"misfire_grace_time": 1,
"max_instances": 1,
"next_run_time": "2019-05-21T17:49:37.750697+08:00"
}
7.1.4.5 更新指定job
API: /{api_prefix}/jobs/{job_id}
请求类型:PATCH
请求参数:job_id,注意请求参数里不能包含id。
{
"func":"config.scheduler:print_test",
"args":["simple"],
"trigger":"interval",
"seconds":5
}
描述:更新指定的job
结果:
{
"id": "job2",
"name": "job2",
"func": "config.scheduler:print_test",
"args": [
"simple"
],
"kwargs": {},
"trigger": "interval",
"start_date": "2019-05-21T17:56:59.183372+08:00",
"seconds": 5,
"misfire_grace_time": 1,
"max_instances": 1,
"next_run_time": "2019-05-21T17:56:59.183372+08:00"
}
7.1.4.6 暂停某个job
API: /{api_prefix}/jobs/{job_id}/pause
请求类型:POST
请求参数:job_id
描述:暂停某个job
结果:
{
"id": "job2",
"name": "job2",
"func": "config.scheduler:print_test",
"args": [
"simple"
],
"kwargs": {},
"trigger": "interval",
"start_date": "2019-05-21T17:56:59.183372+08:00",
"seconds": 5,
"misfire_grace_time": 1,
"max_instances": 1,
"next_run_time": null
}
7.1.4.7 恢复某个job
API: /{api_prefix}/jobs/{job_id}/pause
请求类型:POST
请求参数:job_id
描述:恢复某个job
结果:
{
"id": "job2",
"name": "job2",
"func": "config.scheduler:print_test",
"args": [
"simple"
],
"kwargs": {},
"trigger": "interval",
"start_date": "2019-05-21T17:56:59.183372+08:00",
"seconds": 5,
"misfire_grace_time": 1,
"max_instances": 1,
"next_run_time": "2019-05-21T18:02:59.183372+08:00"
}
7.1.4.8 删除某个job
API: /{api_prefix}/jobs/{job_id}
请求类型:DELETE
请求参数:job_id
描述:删除某个job
结果:无
7.1.2 特性五:为REST API 提供权限认证
flask默认提供了基于HTTP Basic Auth的权限认证。需要开启权限认证,我们需要添加如下配置:
SCHEDULER_AUTH = HTTPBasicAuth()
实现认证方法
@scheduler.authenticate
def authenticate(auth):
return auth['username'] == 'admin' and auth['password'] == 'admin'
如果不带auth发送请求,会出现如下错误。
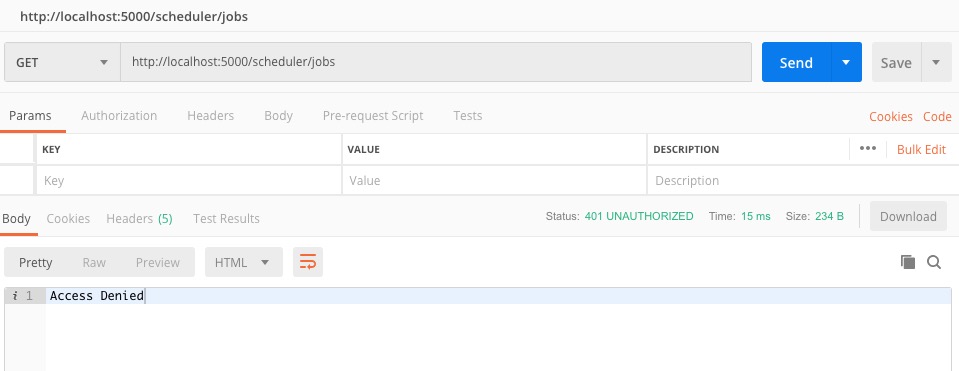
需要带入认证信息。
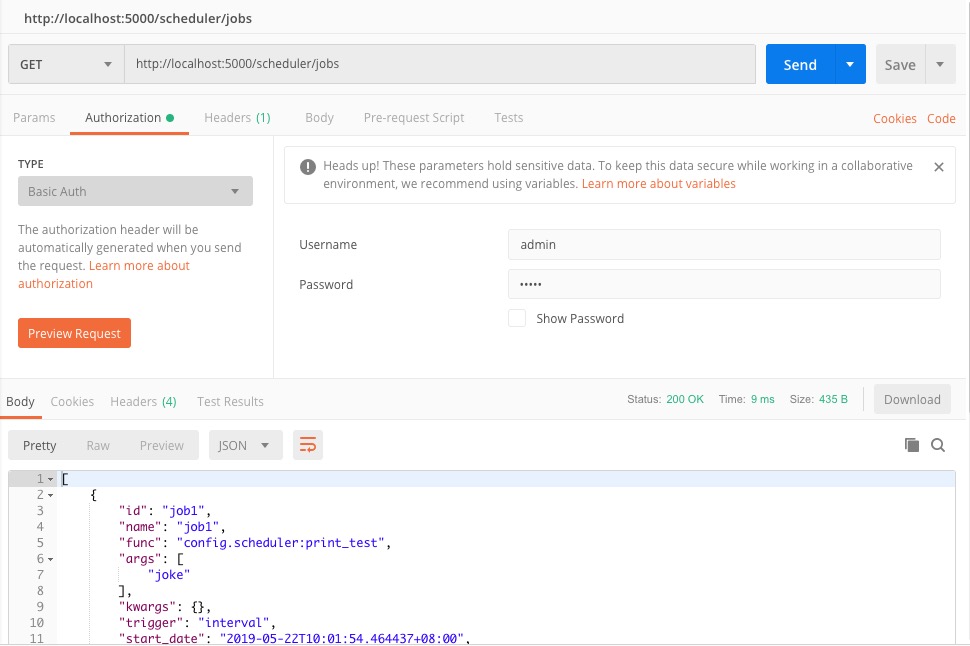
7.2 动态管理定时任务
在7.1小节讲特性的时候,讲到我们可以通过配置添加定时任务,在配置中的JOBS的列表中添加job信息即可,当然在Flask-APScheduler提供的REST API里我们也可以通过给定的API对定时任务进行添加、暂停、恢复、以及删除等管理操作。同样,Flask-APScheduler也提供代码层级的API让我们来实现定时任务的管理。
7.2.1 获取调度信息
# get scheduler info
scheduler_info = OrderedDict([
('current_host', scheduler.host_name),
('allowed_hosts', scheduler.allowed_hosts),
('running', scheduler.running)
])
print(scheduler_info)
7.2.2 获取所有job列表
方法:
get_jobs(self, jobstore=None)
参数说明:
jobstore:为存储器名称,不指定为获取所有存储器里的job
返回值:
job列表,里面包含job实例。
[<Job (id=job1 name=job1)>]
7.2.3 新增job
方法:
add_job(self, id, func, **kwargs)
参数说明:
id:为指定job的id
func:为需要执行的方法,可以是方法名,也可以是字符串,字符串的话需要写成”包路径:方法名”的格式。**kwargs:其他kv格式的参数,如args、trigger、seconds等。
返回值:
单个job实例
job2 (trigger: interval[0:00:05], next run at: 2019-05-22 10:39:27 CST)
demo:
# add job
scheduler.add_job(id='job2', func=print_test, args=('dear',), trigger='interval', seconds=5)
7.2.4 获取某个job信息
方法:
get_job(self, id, jobstore=None)
参数说明:
Id :为指定job的id
jobstore:想要从哪个存储器里获取,默认为None从所有的存储器获取。
返回值:
单个job实例
job2 (trigger: interval[0:00:05], next run at: 2019-05-22 10:49:26 CST)
demo:
# get job
print(scheduler.get_job("job2"))
7.2.5 更新指定job
方法:
modify_job(self, id, jobstore=None, **changes):
参数说明:
Id :为指定job的id
jobstore:想要从哪个存储器里修改,默认为None从所有的存储器。
**changes:更新的内容,如args等
返回值:
单个job实例
job2 (trigger: interval[0:00:05], next run at: 2019-05-22 10:49:26 CST)
demo:
# modify job
scheduler.modify_job("job2", args=("hello",))
7.2.6 暂停某个job
方法:
pause_job(self, id, jobstore=None):
参数说明:
Id :为指定job的id
jobstore:想要从哪个存储器里暂停,默认为None从所有的存储器。
返回值:
单个job实例
demo:
# pause job
scheduler.pause_job("job2")
7.2.7 恢复某个job
方法:
resume_job(self, id, jobstore=None):
参数说明:
Id :为指定job的id
jobstore:想要从哪个存储器里恢复,默认为None从所有的存储器。
返回值:
单个job实例
demo:
# resume job
scheduler.resume_job("job2")
7.2.8 删除某个job
方法:
remove_job(self, id, jobstore=None):
参数说明:
Id :为指定job的id
jobstore:想要从哪个存储器里移除,默认为None从所有的存储器。
返回值:
单个job实例
demo:
# remove job
scheduler.remove_job("job2")
7.3 定时的几种方式:触发器
上面我们在介绍特性以及API的过程中,使用了相同的定时触发器interval。Flask-APScheduler与APScheduler一样支持以下三种触发器:
| 触发器 | 描述 |
|---|---|
| date | 日期:触发任务运行的具体日期 |
| interval | 间隔:触发任务运行的时间间隔 |
| cron | 周期:触发任务运行的周期 |
下面将分别介绍三种触发器的使用,统一使用配置的方式,添加定时任务。
7.3.1 date触发器
date触发器,是指定任务在特定的日期执行。使用date触发器,需要指定两个参数,一个是trigger、另一个是run_date, trigger:’date’,run_date可以有三种值类型。
7.3.1.1 run_date类型为字符串
我们可以指定run_date的值为字符串类型,例如:”2019-05-22 11:58:00”,可以写成如下配置:
{
'id': 'date_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': 'date',
'run_date': '2019-05-22 11:58:00'
}
7.3.1.2 run_date类型为date
指定run_date的值类型为date时,只能精确到天,指定定时任务在具体哪一天执行。
{
'id': 'date_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': 'date',
'run_date': date(2019, 5, 22)
}
7.3.1.3 run_date类型为datetime
指定run_date的值类型为datetime时,可以精确到毫秒。
{
'id': 'date_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': 'date',
'run_date': datetime(2019, 5, 22, 12, 5, 0, 0)
}
7.3.2 interval触发器
interval触发器,是设置任务间隔多长时间运行一次。在前面的例子中我们一直使用的是是interval。它有几个比较常用的参数,间隔参数:seconds、minutes、hours分别是间隔几秒、间隔几分钟、间隔几小时,这几个参数只能设置也一个。时间范围范数:start_date、end_date。设置定时任务运行的时间范围。浮动参数:jitter,给每次触发添加一个随机浮动秒数,一般适用于多服务器,避免同时运行造成服务拥堵。
例如:
{
'id': 'job1',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': 'interval',
'minutes': 1,
'start_date': '2019-05-22 14:00:00',
'end_date': '2019-05-22 16:00:00',
'jitter': 10
}
7.3.3 cron触发器
可以说cron触发器是很强大了,常用的定时任务框架,大多都支持cron定时调度。APScheduler对crontab表达式进行了一层分装,我们可以传入如下参数
class apscheduler.triggers.cron.CronTrigger(
year=None,
month=None,
day=None,
week=None,
day_of_week=None,
hour=None,
minute=None,
second=None,
start_date=None,
end_date=None,
timezone=None,
jitter=None)
当省略时间参数时,在显式指定参数之前的参数会被设定为,之后的参数会被设定为最小值,week 和day_of_week的最小值为。比如,设定day=1, minute=20等同于设定year=’*‘, month='*’, day=1, week=’*‘, day_of_week=’*‘, hour=’*‘, minute=20, second=0,即每个月的第一天,且当分钟到达20时就触发。
表达式类型
| 表达式 | 参数类型 | 描述 |
|---|---|---|
| * | 所有 | 通配符。例:minutes=*即每分钟触发 |
| */a | 所有 | 可被a整除的通配符。 |
| a-b | 所有 | 范围a-b触发 |
| a-b/c | 所有 | 范围a-b,且可被c整除时触发 |
| xth y | 日 | 第几个星期几触发。x为第几个,y为星期几(英文缩写) |
| last x | 日 | 一个月中,最后个星期几触发 |
| last | 日 | 一个月最后一天触发 |
| x,y,z | 所有 | 组合表达式,可以组合确定值或上方的表达式 |
注!month和day_of_week参数分别接受的是英语缩写jan– dec 和 mon – sun
比如设置定时任务在每年的6月、7月、8月、11月和12月的第三个周五,00:00、01:00、02:00和03:00触发。配置定时任务如下所示:
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': 'cron',
'month': '6-8,11-12',
'day': '3rd fri',
'start_date': '2019-05-22 14:00:00',
'end_date': '2019-05-22 16:00:00',
'jitter': 10
}
当然也可以使用crontab表达式,不过需要from_crontab方法创建trigger,如下代码所示:
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': CronTrigger.from_crontab('* * * * *'),
'jitter': 10
}
7.4 Executor 执行器的配置
关于执行器这一块,我查阅的资料不是很详细。APScheduler提供这几种类型处理器:asyncio、gevent、processpool、threadpool、tornado、twisted。
from pkg_resources import iter_entry_points
_executor_plugins = dict((ep.name, ep) for ep in iter_entry_points('apscheduler.executors'))
print(_executor_plugins)
{'asyncio': EntryPoint.parse('asyncio = apscheduler.executors.asyncio:AsyncIOExecutor [asyncio]'), 'debug': EntryPoint.parse('debug = apscheduler.executors.debug:DebugExecutor'), 'gevent': EntryPoint.parse('gevent = apscheduler.executors.gevent:GeventExecutor [gevent]'), 'processpool': EntryPoint.parse('processpool = apscheduler.executors.pool:ProcessPoolExecutor'), 'threadpool': EntryPoint.parse('threadpool = apscheduler.executors.pool:ThreadPoolExecutor'), 'tornado': EntryPoint.parse('tornado = apscheduler.executors.tornado:TornadoExecutor [tornado]'), 'twisted': EntryPoint.parse('twisted = apscheduler.executors.twisted:TwistedExecutor [twisted]')}
通常我们使用额是threadpool和processpool。可以通过如下的配置进行配置:
SCHEDULER_EXECUTORS = {
'default': {
'type': 'threadpool',
'max_workers': 20
},
'process': {
'type': 'processpool',
'max_workers': 10
}
}
创建job的时候,可以通过executor参数执行该job所使用的执行器,如下代码所示。
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': CronTrigger.from_crontab('* * * * *'),
'executor': 'process'
}
7.5 JobStore持久化定时任务
Flask-APScheduler支持定时任务的持久化,默认是使用内存存储定时任务,也支持基于SQLAlchemy的关系型数据库、非关系的MongoDB、Redis、Rethinkdb、另外也支持Zookeeper。
from pkg_resources import iter_entry_points
_jobstore_plugins = dict((ep.name, ep) for ep in iter_entry_points('apscheduler.jobstores'))
print(_jobstore_plugins)
{'memory': EntryPoint.parse('memory = apscheduler.jobstores.memory:MemoryJobStore'), 'mongodb': EntryPoint.parse('mongodb = apscheduler.jobstores.mongodb:MongoDBJobStore [mongodb]'), 'redis': EntryPoint.parse('redis = apscheduler.jobstores.redis:RedisJobStore [redis]'), 'rethinkdb': EntryPoint.parse('rethinkdb = apscheduler.jobstores.rethinkdb:RethinkDBJobStore [rethinkdb]'), 'sqlalchemy': EntryPoint.parse('sqlalchemy = apscheduler.jobstores.sqlalchemy:SQLAlchemyJobStore [sqlalchemy]'), 'zookeeper': EntryPoint.parse('zookeeper = apscheduler.jobstores.zookeeper:ZooKeeperJobStore [zookeeper]')}
7.5.1MemoryJobStore
该存储器是APScheduler默认的,不需要手动指定。当然也可以通过配置文件进行显示指定,配置如下所示:
SCHEDULER_JOBSTORES = {
'default': MemoryJobStore()
}
7.5.2 SQLAlchemyJobStore
在前面讲Flask的ORM框架的时候,我们提到过Flask-SQLAlchemy,这里Flask-APScheduler可以基于它进行关系型数据库的定时任务持久化, MySQL、SQLite、Oracle、Postgresql等。这里为了方便演示,使用SQLite进行持久化。在使用SQLAlchemyJobStore之前首先要安装该插件。
pip install flask-sqlalchemy
配置如下所示:
SCHEDULER_JOBSTORES = {
'default': MemoryJobStore(),
'sqlalchemy': SQLAlchemyJobStore(url='sqlite:///test.db')
}
并且在配置定时任务的时候,显示的指定该job所使用的jobstore。
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': CronTrigger.from_crontab('* * * * *'),
'executor': 'process',
'jobstore':'sqlalchemy'
}
启动应用之后,会发现自动创建了一个名为apscheduler_jobs的表。如下图所示:
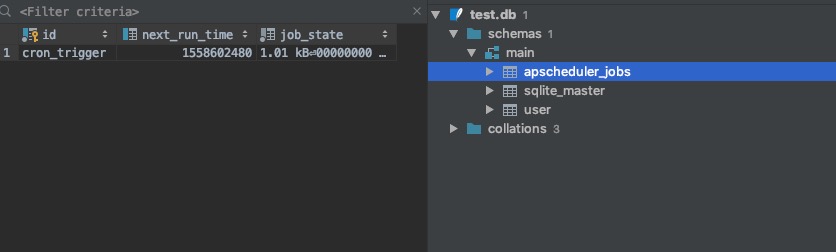
7.5.3 RedisJobStore
同样我们也可以使用Redis进行持久化,首先需要安装Python的Redis包。
pip install redis
配置:
SCHEDULER_JOBSTORES = {
# 'default': MemoryJobStore(),
# 'sqlalchemy': SQLAlchemyJobStore(url='sqlite:///test.db'),
'redis': RedisJobStore(host='localhost', port=6379)
}
显示指定:
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': CronTrigger.from_crontab('* * * * *'),
'executor': 'process',
'jobstore': 'redis'
}
如下图所示,发现redis里写入了APScheduler相关的数据。

7.5.4 RethinkDBJobStore
关于rethindb,https://rethinkdb.com/。APScheduler同样支持使用RethinkDB做定时任务持久化。
依然首选需要安装RethinkDB的包。
pip install rethinkdb
配置:
SCHEDULER_JOBSTORES = {
# 'default': MemoryJobStore(),
# 'sqlalchemy': SQLAlchemyJobStore(url='sqlite:///test.db'),
# 'redis': RedisJobStore(host='localhost', port=6379),
'rethinkdb': RethinkDBJobStore(host='localhost', port=28015)
}
显示在job里指定jobstore
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': CronTrigger.from_crontab('* * * * *'),
'executor': 'process',
'jobstore': 'rethinkdb'
}
重启应用,发现在rethinkdb里写入了定时任务的相关信息。
7.5.5 MongoDBJobStore
依然需要安装mongo的python包
pip install pymongo
配置:
SCHEDULER_JOBSTORES = {
# 'default': MemoryJobStore(),
# 'sqlalchemy': SQLAlchemyJobStore(url='sqlite:///test.db'),
# 'redis': RedisJobStore(host='localhost', port=6379),
# 'rethinkdb': RethinkDBJobStore(host='localhost', port=28015)
'mongodb': MongoDBJobStore(host='localhost',port=27017)
}
显示的在job中指定:
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': CronTrigger.from_crontab('* * * * *'),
'executor': 'process',
'jobstore': 'mongodb'
}
重启应用,查看数据库如下所示:
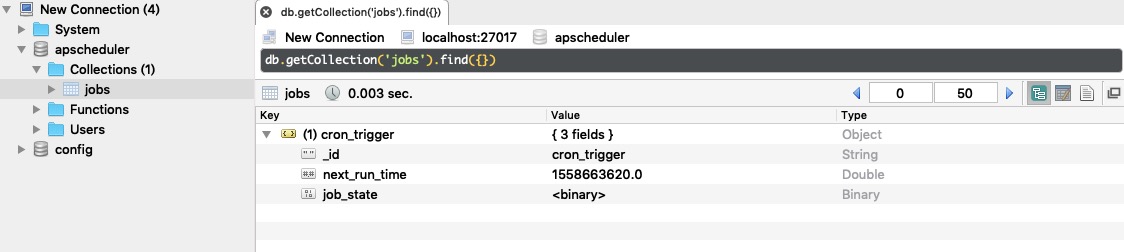
7.5.6 ZooKeeperJobStore
依然是需要安装zookeeper的python客户端,这里使用的是kazoo
pip install kazoo
配置:
SCHEDULER_JOBSTORES = {
# 'default': MemoryJobStore(),
# 'sqlalchemy': SQLAlchemyJobStore(url='sqlite:///test.db'),
# 'redis': RedisJobStore(host='localhost', port=6379),
# 'rethinkdb': RethinkDBJobStore(host='localhost', port=28015)
# 'mongodb': MongoDBJobStore(host='localhost',port=27017)
'zookeeper': ZooKeeperJobStore(hosts='localhost:2181')
}
显示的在job中指定jobstore:
{
'id': 'cron_trigger',
'func': 'config.scheduler:print_test',
'args': ('joke',),
'trigger': CronTrigger.from_crontab('* * * * *'),
'executor': 'process',
'jobstore': 'zookeeper'
}
进入zookeeper命令行,查看。

8 Socket插件Flask-SocketIO
相信websocket在平时的web开发中,也用到不少。这里主要介绍一下Flask里的Flask-SocketIO插件,该插件支持三种异步模式:eventlet、gevent、threading。
- eventlet是性能最佳的选项,支持长轮询和WebSocket传输。
- gevent在许多不同的配置中得到支持。gevent包完全支持长轮询传输,但与eventlet不同,gevent没有原生的WebSocket支持。要添加对WebSocket的支持,目前有两种选择:安装gevent-websocket 包为gevent添加WebSocket支持,或者可以使用带有WebSocket功能的uWSGI Web服务器。gevent的使用也是一种高性能选项,但略低于eventlet。
- theading需要注意的是它缺乏其他两个选项的性能,因此它只应用于简化开发工作流程,此选项仅支持长轮询传输。
Flask-SocketIO会根据安装的内容自动检测要使用的异步框架。优先选择eventlet,然后是gevent。对于gevent中的WebSocket支持,首选uWSGI,然后是gevent-websocket。如果既未安装eventlet也未安装gevent,则使用Flask开发服务器。更多关于Flask-SocketIO的使用可以查看官网:https://flask-socketio.readthedocs.io/en/latest/。
8.1 快速使用
首先需要安装Flask-SocketIO的包
pip install flask-socketio
初始化
# create a flask app
app = Flask(__name__)
# create socketio
socketio = SocketIO()
if __name__ == '__main__':
# init scheduler
scheduler.init_app(app=app)
scheduler.start()
scheduler_api()
# init socketio
socketio.init_app(app=app)
# run server
socketio.run(app=app, host='0.0.0.0', port=5000, debug=False)
8.2 演示Demo
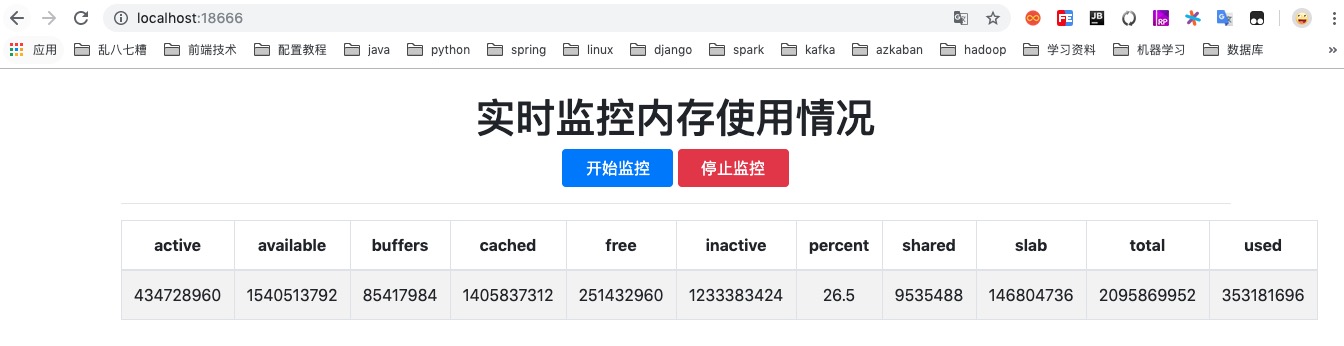
官网文档关于Flask-SocketIO的说明已经很详细了,就不做多余的copy。使用Flask-SocketIO接收消息、发送消息、广播、房间等功能都可以参考官网例子。这里就简单写一个hello world级别的demo,演示一下Flask-SokcetIO如何使用。该demo主要功能就是实时获取内存使用情况,并将信息推送给前台,如下所示:
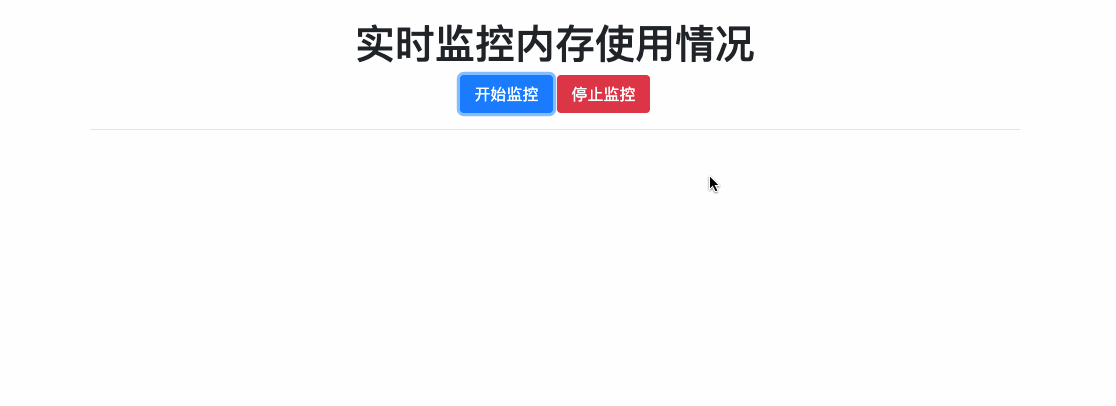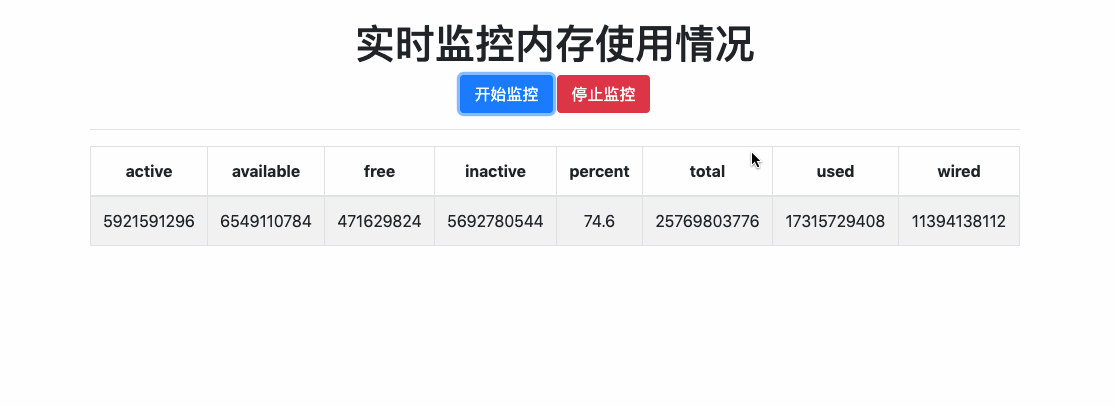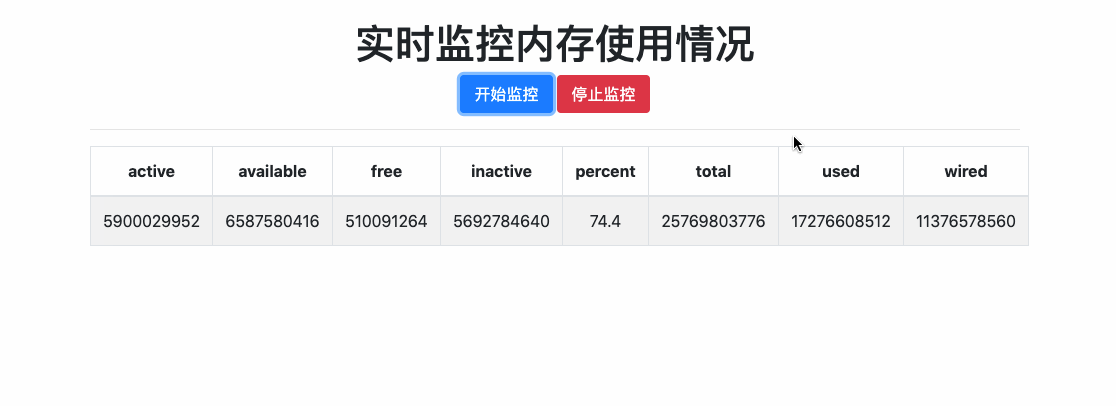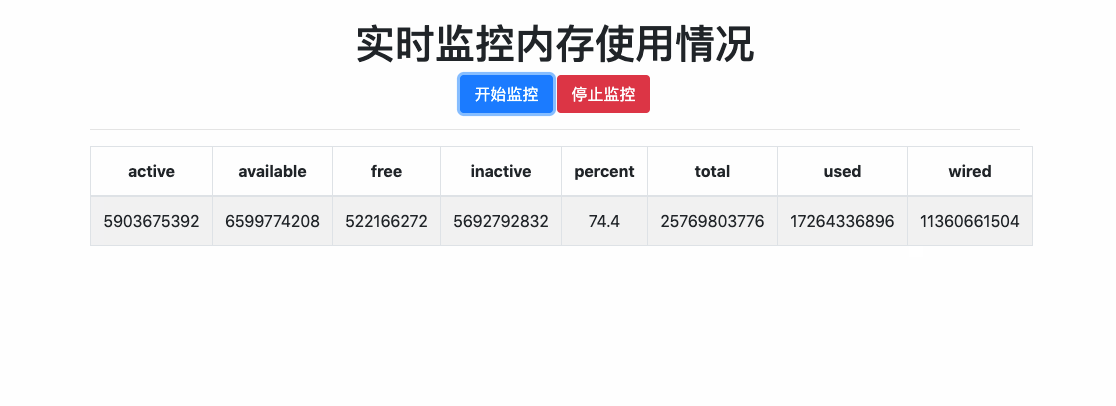
主要思路是:当用户点击 [开始监控]按钮时,触发socket连接,后台socket接收连接事件之后,启动后台任务每两秒钟获取一次内存信息,然后推送给前台,前台接收到消息后实时展示。当用户点击[停止监控]按钮是,触发socket销毁,后台socket借口销毁事件之后,停止监控内存。
8.2.1 获取内存信息
这里使用psutil获取内存信息,需要先安装此包。
pip install psutil
获取内存信息并解析成json
def get_virtual_memory():
"""
获取内存使用情况
:return: dict
"""
memory_info = psutil.virtual_memory()
return {attr: getattr(memory_info, attr) for attr in dir(memory_info) if
not attr.__contains__("_") and not isinstance(getattr(memory_info, attr), type(len))}
json格式如下所示:
{
"active": 5771452416,
"available": 6745636864,
"free": 762896384,
"inactive": 5699289088,
"percent": 73.8,
"total": 25769803776,
"used": 17115865088,
"wired": 11344412672
}
8.2.2 编写异步方法
该方法主要功能是每2秒获取一次内存信息,然后推送给前台。这里使用tasks字典来存放任务状态,
使用emit()方法推送消息。代码如下所示:
def background_task(sid):
# add sid to tasks
tasks[sid] = True
while tasks[sid]:
info = get_virtual_memory()
socketio.emit("server_response", {'data': info}, namespace='/ws')
socketio.sleep(2)
if not tasks[sid]:
tasks.pop(sid)
8.2.3 SocketIO监听connect事件
后台使用@socketio.on(“connect”, namespace=”/ws”)监听connect事件,并使用socketio.start_background_task()启动后台任务。代码如下所示:
@socketio.on("connect", namespace="/ws")
def handle_connect():
"""
handle connect
:return:
"""
sid = getattr(request, 'sid')
socketio.start_background_task(background_task, sid)
emit("connect", {'data': '连接成功'})
8.2.4 SocketIO监听disconnect事件
后台使用@socketio.on(“disconnect”, namespace=”/ws”)监听disconnect事件,并设置tasks状态为False用以停止后台任务。代码如下:
@socketio.on("disconnect", namespace="/ws")
def handle_disconnect():
sid = getattr(request, 'sid')
if sid in tasks:
tasks[sid] = False
8.2.5 前台展示
前台主要使用socket.io.js与后台通信。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Flask Demo</title>
<link rel="stylesheet" href="https://cdn.bootcss.com/bootstrap/4.0.0/css/bootstrap.min.css"
integrity="sha384-Gn5384xqQ1aoWXA+058RXPxPg6fy4IWvTNh0E263XmFcJlSAwiGgFAW/dAiS6JXm" crossorigin="anonymous">
<script src="https://cdn.bootcss.com/jquery/3.2.1/jquery.slim.min.js"
integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN"
crossorigin="anonymous"></script>
<script src="https://cdn.bootcss.com/popper.js/1.12.9/umd/popper.min.js"
integrity="sha384-ApNbgh9B+Y1QKtv3Rn7W3mgPxhU9K/ScQsAP7hUibX39j7fakFPskvXusvfa0b4Q"
crossorigin="anonymous"></script>
<script src="https://cdn.bootcss.com/bootstrap/4.0.0/js/bootstrap.min.js"
integrity="sha384-JZR6Spejh4U02d8jOt6vLEHfe/JQGiRRSQQxSfFWpi1MquVdAyjUar5+76PVCmYl"
crossorigin="anonymous"></script>
<script src="https://cdn.bootcss.com/socket.io/2.2.0/socket.io.dev.js"></script>
</head>
<body>
<div class="container">
<br>
<h1 class="text-center">实时监控内存使用情况</h1>
<div class="row">
<div style="margin-bottom: 5%" class="col-md-12 text-center head-title-font">
<button id="start-monitor" class="btn btn-primary" style="width: 10%">开始监控</button>
<button id="stop-monitor" class="btn btn-danger" style="width: 10%">停止监控</button>
<hr>
<table data-toggle="table" class="table table-striped table-bordered">
<thead>
<tr id="table_head">
</tr>
</thead>
<tbody>
<tr id="table_content">
</tr>
</tbody>
</table>
</div>
</div>
</div>
<script>
const url = "ws://localhost:5000/ws";
let socket = null;
//开始监控
$("#start-monitor").click(function () {
socket = io(url)
socket.on('connect', function (msg) {
if (!$.isEmptyObject(msg)) {
alert("开启监控")
socket.on('server_response', function (msg) {
let headHtml = ''
let content = ''
for (let key in msg['data']) {
headHtml += '<th>' + key + '</th>'
content += `<td>${msg['data'][key]}</td>`
}
$("#table_head").html(headHtml)
$("#table_content").html(content)
});
}
});
})
// 停止监控
$("#stop-monitor").click(function () {
socket.disconnect()
})
</script>
</body>
</html>
9 使用自定义红图打造层次结构分明的项目
之前小节讲解了如果使用Flask快速创建一个Web服务,并介绍了Flask的几种扩展。可以看出Flask是一个渐进式的web服务框架,我们可以根据需求动态的进行组件扩展。这一节主要介绍一下如何使用自定义的红图打造一个层次结构分明的项目。为什么要打造一个层次分明的项目,对我个人来说,受spring mvc框架的影响,希望把项目能够按照架构分层,像视图层、逻辑层、数据访问层等,更重要的一点,层次分明的项目,可读性更强。
9.1 项目结构及说明
这里创建了一个小的项目,功能层面上实现了博客、用户、标签的CURD操作。提供了RESTful风格的接口。项目集成了上面讲述的blueprint、redprint用于进行项目的层次划分,集成了Flask-SocketIO插件用以提供WebSocket服务,集成了Flask-SQLAlchemy用以对关系型数据库的操作,集成了Flask-APScheduler插件用以执行定时任务。项目结构如下所示:
├── README.md
├── application # 应用代码文件夹
│ ├── __init__.py # 初始化应用
│ ├── api # api包,用以提供RESTful接口
│ │ ├── __init__.py
│ │ └── v1 # v1版本包
│ │ ├── __init__.py # 初始化v1蓝图,注册红图
│ │ ├── blog # 博客相关接口
│ │ │ ├── business.py
│ │ │ └── endpoints.py
│ │ ├── socketio.py
│ │ ├── tag # 标签相关接口
│ │ │ ├── business.py
│ │ │ └── endpoints.py
│ │ └── user # 用户相关接口
│ │ ├── business.py
│ │ └── endpoints.py
│ ├── apsheduler
│ │ ├── __init__.py
│ ├── config # 应用相关配置目录
│ │ ├── __init__.py
│ │ ├── logging.conf # 日志配置文件
│ │ ├── scheduler.py # flask-apscheduler配置文件
│ │ └── setting.py # 应用配置文件
│ ├── database
│ │ ├── __init__.py # 初始化数据库
│ │ └── models.py # 模型类,对象关系映射
│ ├── libs # 组件包
│ │ ├── __init__.py
│ │ ├── error.py # 处理错误请求,返回结构化数据
│ │ ├── ok.py # 处理正常请求,返回结构化数据
│ │ └── redprint.py # 红图插件,提供红图路由
│ ├── socketio # flask-socketio扩展
│ │ ├── __init__.py
│ └── templates # 用以存放模板以及静态资源。
│ ├── index.html
│ └── static
│ ├── css
│ └── js
├── application.db # sqlite数据库文件
├── logs
│ └── application.log # 应用日志
├── manager.py # 应用入口脚本,提供服务启动、数据库初始化、数据库情况等命令
└── requirements.txt # 依赖包清单
9.2 代码及接口说明
关于项目搭建,以及每一模块的详细说明,这里就不做详细描述,完整的代码已经上传到GitHub上了,项目地址:https://github.com/shirukai/flask-framework-redprint.git
接口的话这里生成了一份PostMan的文档。https://documenter.getpostman.com/view/2759292/S1TSYymv 可以在本地将服务起来,进行接口测试。
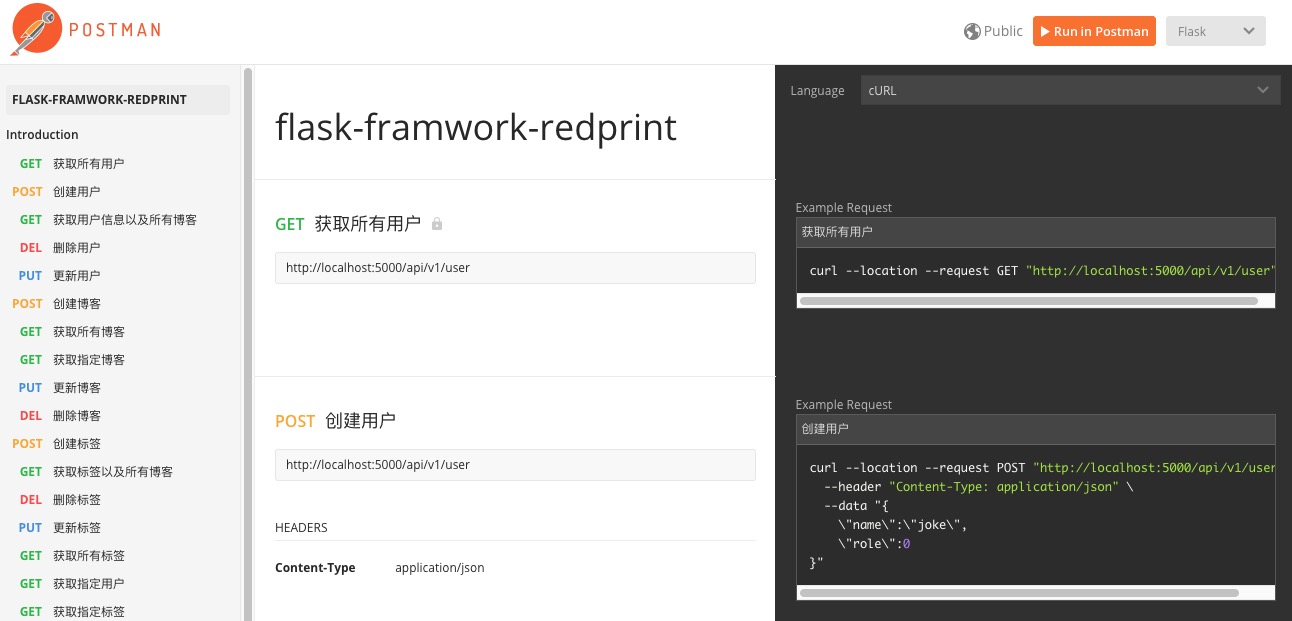
10 使用flask-restplus插件打造RESTFul风格项目
上面我们已经使用Redprint打造了一个层次接口分明的项目,并且也具有了一定的RESFul风格,能够满足大部分的项目开发。但是提供的REST API管理起来并不容易,在Spring项目里,我们可以使用Swagger来管理API,同样Flask也支持Swagger,因为是渐进式框架, 同样需要我们安装支持swagger的扩展,这里使用的是flask-restplus,官方网址:https://flask-restplus.readthedocs.io/en/stable/,它的主旨是以最少的设置进行最佳实践,快速构建REST API并提供一个连贯的装饰器和工具集来描述我们的API并正确公开其文档。
10.1 安装flask-restplus
像其它扩展一样,flask-restplus可以通过pip直接安装
pip install flask-restplus
或者使用easy_install
easy_install flask-restplus
10.2 项目结构及说明
这里对之前的使用红图创建的项目进行改造,使用flask-restplus来替代红图的作用。主体结构不变,主要对endpoints以及v1.__init__.py进行改造,具体实现可以参考代码。
├── README.md
├── application
│ ├── __init__.py
│ ├── api
│ │ ├── __init__.py
│ │ └── v1
│ │ ├── __init__.py # 注册restplus的namespace
│ │ ├── blog
│ │ │ ├── business.py
│ │ │ └── endpoints.py
│ │ ├── restplus.py # restplus初始化
│ │ ├── serializers.py # 串行口用以格式化请求参数和返回值
│ │ ├── socketio.py
│ │ ├── tag
│ │ │ ├── business.py
│ │ │ └── endpoints.py
│ │ └── user
│ │ ├── business.py
│ │ └── endpoints.py
│ ├── apsheduler
│ │ ├── __init__.py
│ ├── config
│ │ ├── __init__.py
│ │ ├── logging.conf
│ │ ├── scheduler.py
│ │ └── setting.py
│ ├── database
│ │ ├── __init__.py
│ │ └── models.py
│ ├── libs
│ │ ├── __init__.py
│ │ ├── error.py
│ │ ├── ok.py
│ │ └── redprint.py
│ ├── socketio
│ │ ├── __init__.py
│ └── templates
│ ├── index.html
│ └── static
│ ├── css
│ └── js
├── application.db
├── logs
│ └── application.log
├── manager.py
└── requirements.txt
10.3 代码及接口说明
代码同样放到了GitHub上,可以下载代码参考,项目地址:https://github.com/shirukai/flask-framwork-restplus.git。
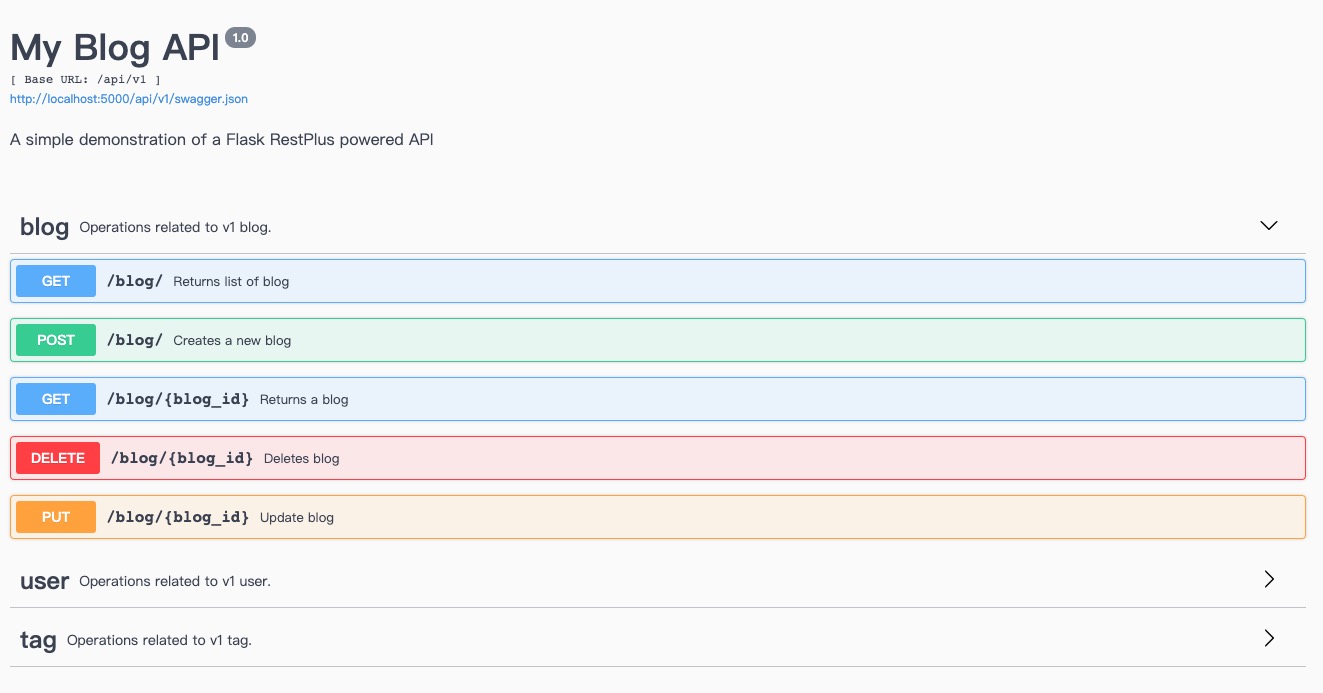
刚才也提到过,RESTPlus会自动为我们生成接口文档,当我们启动项目之后,可以访问http://localhost:5000/api/v1查看swagger。
11 Flask项目发布
Flask自动的app.run()启动的web服务是用来开发的,并不适合生成环境,所以官方不建议使用app.run()作为生产的容器。关于Flask的项目发布,官方也提供了几种方式,具体的可以参考:https://dormousehole.readthedocs.io/en/latest/deploying/。这里就不一一讲解,因为这个地方我接触的也不多,暂且只写一下使用uWSGI进行Flask项目的发布吧。
11.1 安装uWSGI
使用pip安装uwsgi
pip install uwsgi
11.2 uwsgi命令的方式启动flask项目
这里以flask-framework-redprint这个项目为例子,使用uwsgi命令行启动服务。
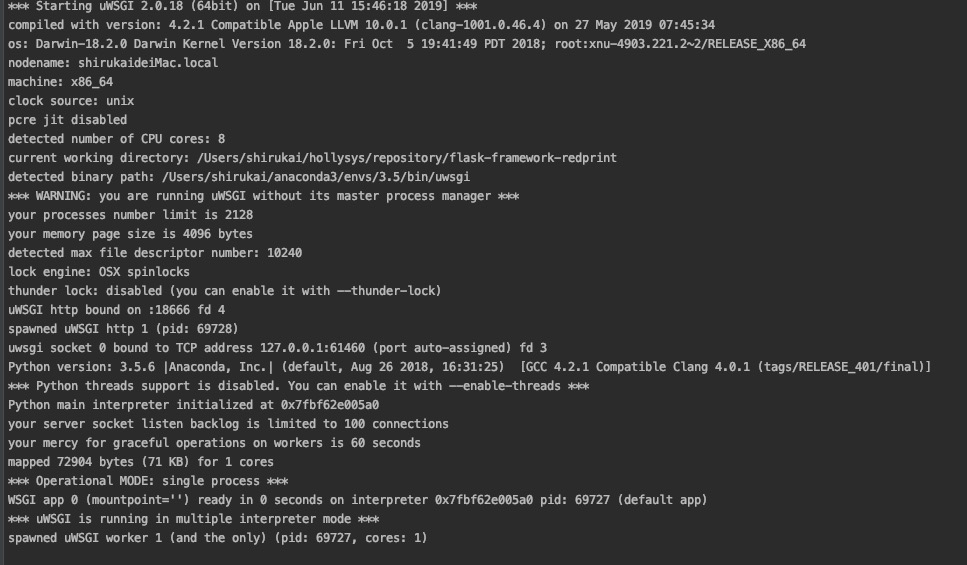
uwsgi --http :18666 --wsgi-file manager.py --callable app
11.3 使用配置文件的方式启动flask项目
上面使用命令可以简单的启动一个flask服务,但是如果命令参数比较多,使用命令就比较繁琐,这时候我们可以通过配置文件的方式启动。给我们的flask项目设置一个uwsgi配置文件。同样是以flask-framework-redprint为例,在项目根目录创建一个名为uwsgi.ini的配置文件,内容如下:
[uwsgi]
wsgi-file = manager.py
callable = app
gevent = 1000
http-websockets = true
master = true
http = 0.0.0.0:18666
启动服务
uwsgi uwsgi.ini
效果与命令行一样。
12 Flask项目容器化
docker,docker快到碗里来,flask,flask快到docker里去。目前我司项目部署大多都是使用docker,这里不禁要感慨一下,曾几何时使用spring mvc,需要一大把的xml文件,去配置bean,去配置mybatis等等,各种配置文件,搞不好哪里就出问题了,而且启动的时候还需要打成war放到tomcat里,繁琐易出错。现在使用spring boot简化了太多的配置,而且自带web容器,方便到爱不释手,再加上docker加持,从开发到生产节省了太多的精力了。说这么多,只是想表达,新技术给我们带来的极大的便利。接触docker不长,但已经被深深的吸引,上文在讲Flask定时任务插件时,提到的几种持久化方式,像Redis、RethinkDB、MongoDB、还有Zookeeper等,我都是通过docker部署的,几乎是一条命令,就部署完成了,节省了太多部署步骤。所以这里也简单讲一下,如何将我们的Flask服务容器化。
12.1 使用Dockerfile创建容器镜像
在项目根目录创建名为Dockerfile的文件,内容如下:
FROM python:3
ARG SERVER_PORT=18666
MAINTAINER shirukai "shirukai@hollysys.net"
# set work dir
WORKDIR flask-framework-redprint
# copy server files
COPY . .
# install dependencies
RUN pip install --no-cache-dir -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# expose server port
EXPOSE ${SERVER_PORT}
# set time zone
ENV TZ Asia/Shanghai
# start flask service when the container starts
CMD uwsgi uwsgi.ini
在项目路径执行docker命令创建镜像
docker build -t flask-framework-redprint:v1 .
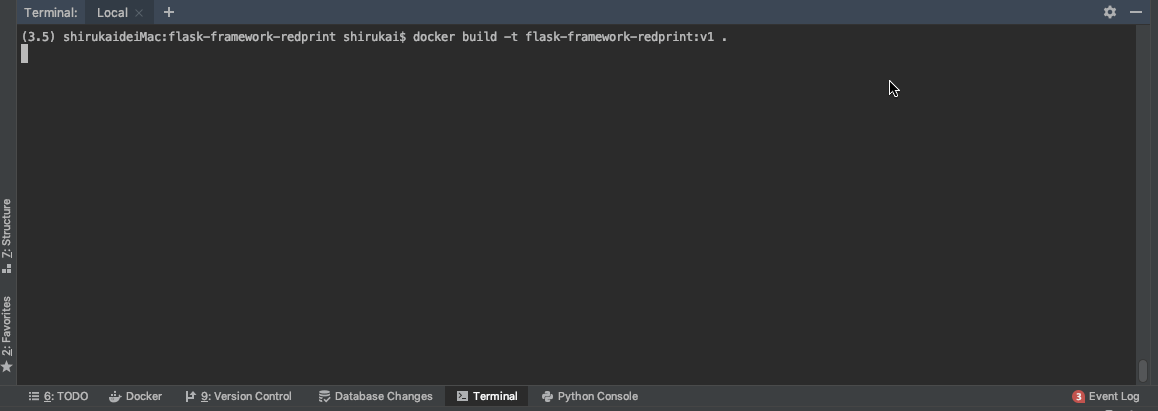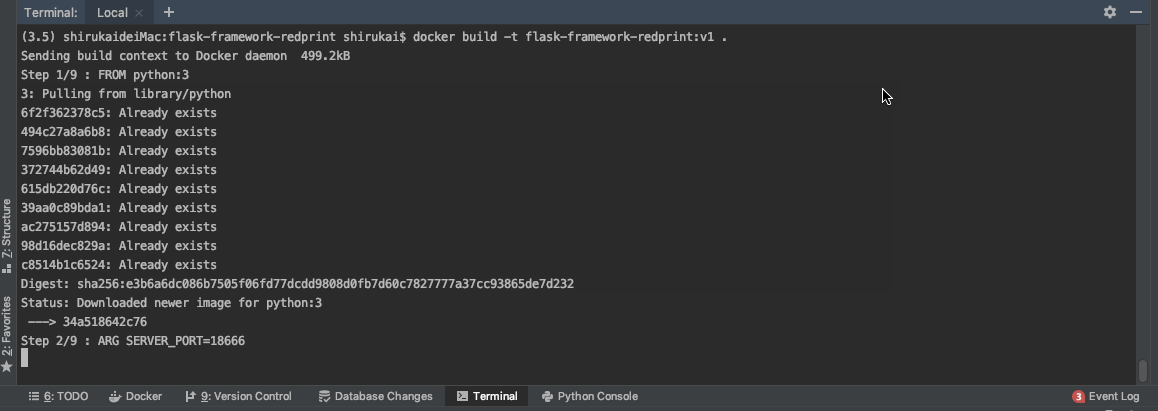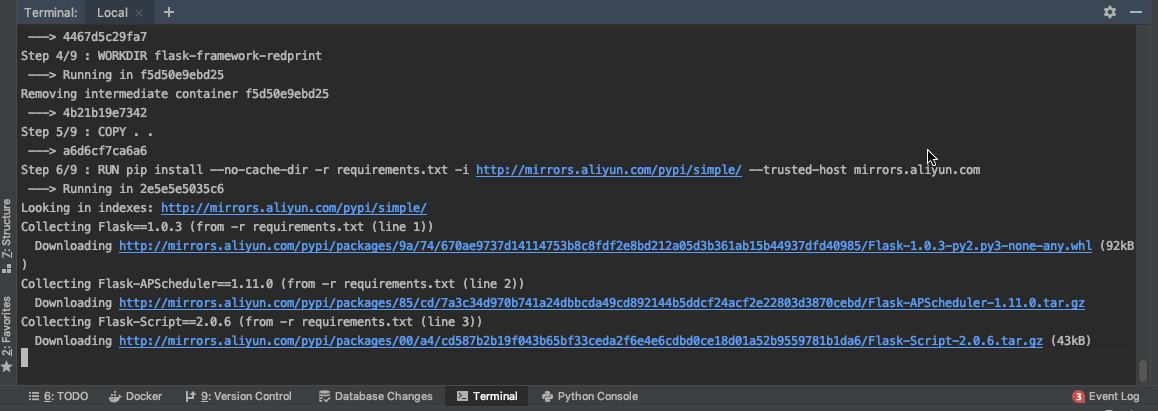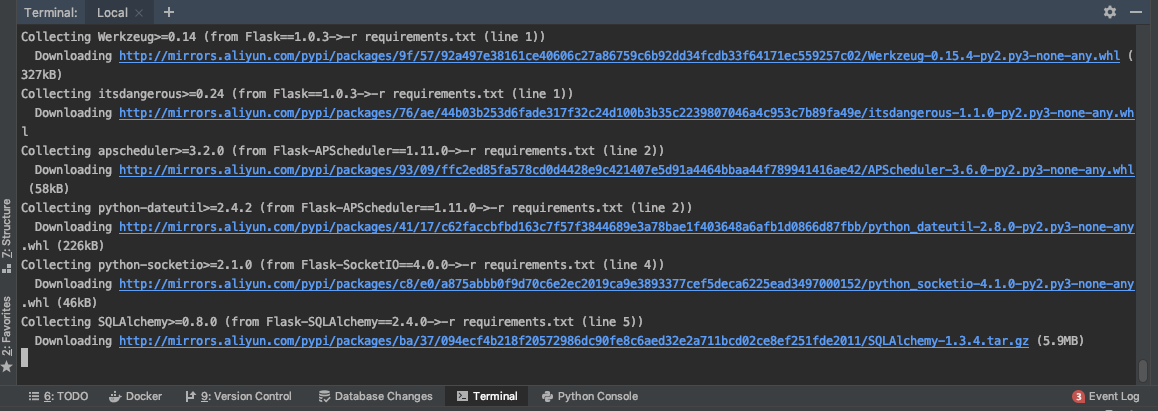
等待创建完成,我们可以使用docker images查看我们的镜像。
12.2 启动容器
镜像创建完成之后,我们就可以启动我们的docekr容器了,使用如下命令运行
docker run -itd -p 18666:18666 flask-framework-redprint:v1
查看容器状态
docker ps

查看容器日志
docekr logs 8ca71365a64e
访问localhost:18666查看
总结
Flask的知识点整理到这里总算要告一段落,前前后后花了差不多一个月的时间,断断续续。期间在图书馆拜读了基本关于Flask的书《Flask Web开发》和《Flask Web开发实战:入门、进阶与原理解析》,怎么说呢,这两本书其实大同小异,内容差不多,后者实战的东西更多一点,没有深入阅读。从这两本书中,补充了不少知识,比如请求钩子、关系模型等。之前也接触过Python的另一个热门的Web框架Django,那会学习起来比较费劲,因为刚接触Python,需要学习语法也需要学习框架,对于Django框架的学习只停留在了会使用的阶段。在学习Flask的时候,轻松了不少,一个原因是框架本身的轻量级,另一个原因是有了语言基础,学习起来并不费劲。本文是我对Flask的学习记录,从0到1的学习过程,希望有所帮助,不足或者有错误的地方,烦请指正。

Contents
- 1. 1 环境准备
- 2. 2 快速创建一个Web服务
- 3. 3 Flask请求处理
- 4. 4 Flask蓝图
- 5. 5 自定义Flask红图
- 6. 6 ORM插件 Flask-SQLAlchemy
- 7. 7 定时调度插件Flask-APScheduler
- 8. 8 Socket插件Flask-SocketIO
- 9. 9 使用自定义红图打造层次结构分明的项目
- 10. 10 使用flask-restplus插件打造RESTFul风格项目
- 11. 11 Flask项目发布
- 12. 12 Flask项目容器化
- 13. 总结