Flink版本:1.8.2
Hadoop: 3.0.3
参考文章:
文中关于Per-Job、Session模式的描述摘自《Deploy Apache Flink® Natively on YARN/Kubernetes》 https://ververica.cn/developers/deploy-apache-flink-natively-on-yarn-kubernetes/
Flink在YARN上部署有两种模式,一种是Session模式,另一种是Per-Job模式。
Yarn 模式运行 Flink job 的好处有:
资源按需使用,提高集群的资源利用率
任务有优先级,根据优先级运行作业
基于 Yarn 调度系统,能够自动化地处理各个角色的 Failover
○ JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
○ 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
○ 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
1 准备环境
为了方便演示在YARN上进行Session模式和Per-Job模式部署,我们需要进行环境准备。
以下环境是前提条件:
- Hadoop版本在2.2以上
- 安装有HDFS和YARN服务
下载Flink
官网下载页面:https://flink.apache.org/downloads.html 这里我们下载flink版本为1.8.2,scala版本为2.12的安装包。
wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.8.2/flink-1.8.2-bin-scala_2.12.tgz解压
tar -zxvf flink-1.8.2-bin-scala_2.12.tgz目录如下图所示:

查看版本
./bin/flink -v Version: 1.8.2, Commit ID: 6322618
提交客户端常用命令参数列表,使用./bin/flink run -h查看
| 参数 | 说明 |
|---|---|
| -c,–class <classname> | 带有程序入口点的类(“ main”方法或“ getPlan()”方法。仅当JAR文件未在其manifest中指定该类时才需要。 |
| -C,–classpath <url> | 将URL添加到群集中所有节点上的每个用户代码类加载器。路径必须指定协议(例如file://),并且可以在所有节点上访问(例如,通过NFS共享)。可以多次使用此选项来指定多个URL。 |
| -d,–detached | 以detached模式运行Job |
| -n,–allowNonRestoredState | 允许跳过无法还原的保存点状态。如果在触发保存点时从程序中删除了一部算子,则需要允许此操作。 |
| -p,–parallelism <parallelism> | 运行程序的并行度。可选,用于覆盖配置中指定的默认值。 |
| -q,–sysoutLogging | 禁止将日志输出为标准输出 |
| -s,–fromSavepoint <savepointPath> | 指定savepoint路径,从改savepoint进行恢复 |
| -sae,–shutdownOnAttachedExit | 如果作业以attached模式提交,在CLI突然终止时(例如,响应用户中断,例如键入Ctrl + C),尽最大努力关闭集群。 |
YARN Cluster相关的参数
| 参数 | 说明 |
|---|---|
| -d,–detached | 以detached模式运行Job |
| -m,–jobmanager<arg> | 要连接的JobManager(master)的地址,使用此参数连接到与配置中指定的JobManager不同的JobManager。 |
| -sae,–shutdownOnAttachedExit | 如果作业以attached模式提交,在CLI突然终止时(例如,响应用户中断,例如键入Ctrl + C),尽最大努力关闭集群。 |
| -yD <property=value> | 配置参数,例如-yDhostname=localhost |
| -yd,–yarndetached | 以detached模式运行作业(不建议使用;使用非特定于YARN的选项) |
| -yh,–yarnhelp | 帮助说明 |
| -yid,–yarnapplicationId <arg> | 访问正在运行的YARN回话,指定YARN的application id |
| -yj,–yarnjar <arg> | Flink jar文件的路径 |
| -yjm,–yarnjobManagerMemory <arg> | 带可选单元的JobManager容器的内存(默认值:MB) |
| -yn,–yarncontainer <arg> | 要分配的YARN容器数(=任务管理器数) |
| -ynl,–yarnnodeLabel <arg> | 为YARN应用程序指定YARN节点标签 |
| -ynm,–yarnname <arg> | 为YARN上的应用程序设置自定义名称 |
| -yq,–yarnquery | 显示可用的YARN资源(内存,核心) |
| -yqu,–yarnqueue <arg> | 指定YARN队列 |
| -ys,–yarnslots <arg> | 每个TaskManager的slot数量 |
| -yst,–yarnstreaming | 以streaming模式启动flink |
| -yt,–yarnship <arg> | 将文件发送到指定目录(用于传输) |
| -ytm,–yarntaskManagerMemory <arg> | 每个TaskManager容器的内存,带有可选单位(默认值:MB) |
| -yz,–yarnzookeeperNamespace <arg> | 为高可用性模式创建Zookeeper子路径的命名空间 |
| -z,–zookeeperNamespace <arg> | 为高可用性模式创建Zookeeper子路径的命名空间 |
2 Per-Job模式
2.1 描述
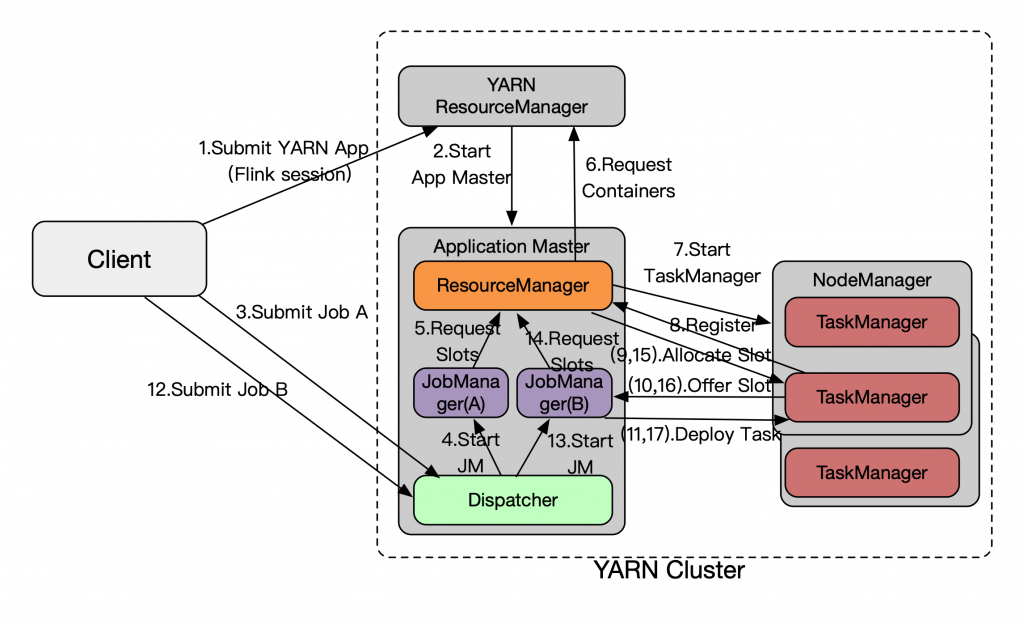
Per-Job即一个Flink Job与其YARN Application(App)生命周期绑定,执行过程如下图,在提交YARN App时同时将Flink Job的file/jars通过YARN Distributed Cache分发,一次性完成提交,而且JM是根据JobGraph产生的Task的资源实际需求来向RM申请slot执行,Flink RM再动态的申请/释放YARN的Container。
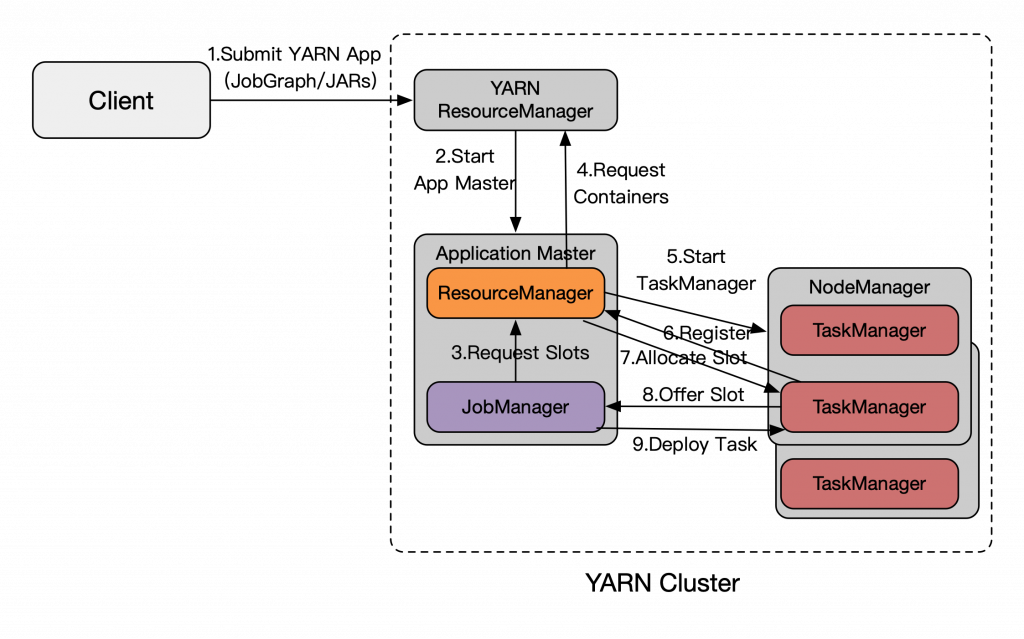
2.1 使用Per-Job模式向YARN提交Job
这里以提交官方example/streaming包下提供的SocketWindowWordCount为例,需要我们提供一个socket地址和端口,我们在本地使用nc命令监听9090端口。
nc -lk 9090
使用命令行提交:
./bin/flink run -m yarn-cluster examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9090
注意:如果遇到错误,可以参考第四部分错误问题汇总
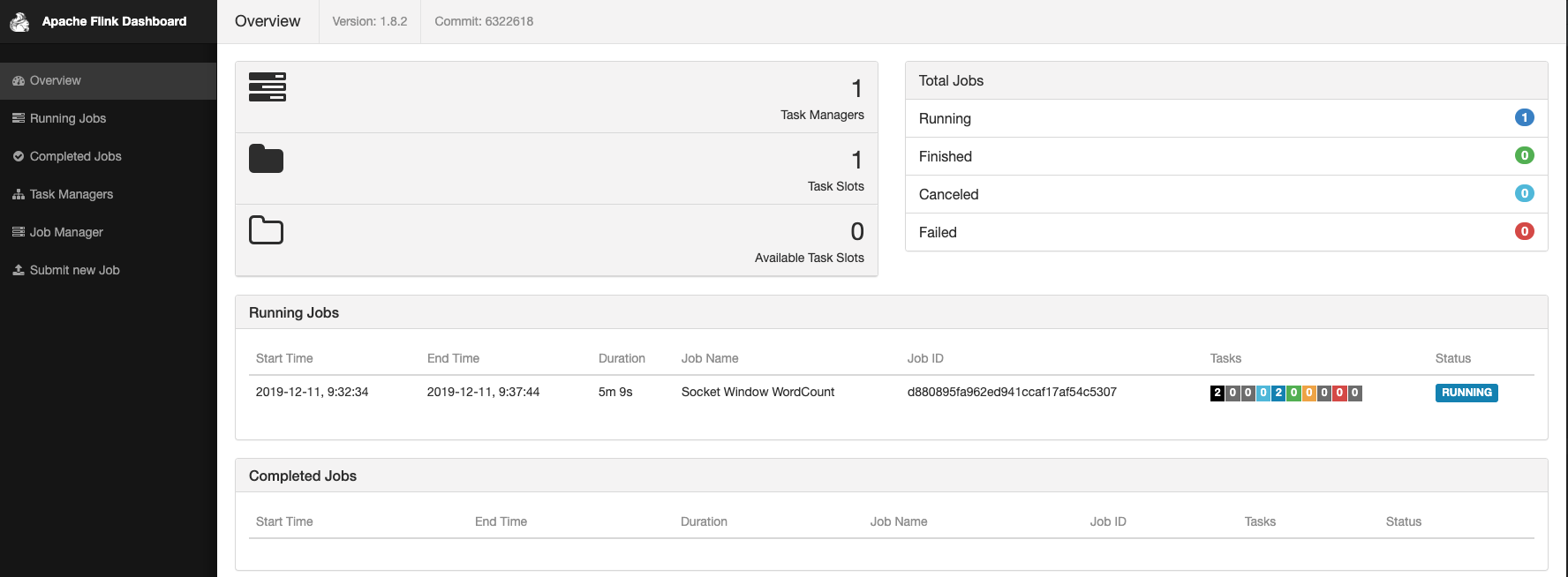
如下图所示,提交成功。

我们可以进入YARN Web查看我们刚才提交的应用。

点击【ApplicationMaster】进入Flink Web。
在socket命令窗口,输入单词hello world

点击Flink Web左侧导航栏中的【Task Managers】,选择一个Task,然后点击【Stdout】查看输出。
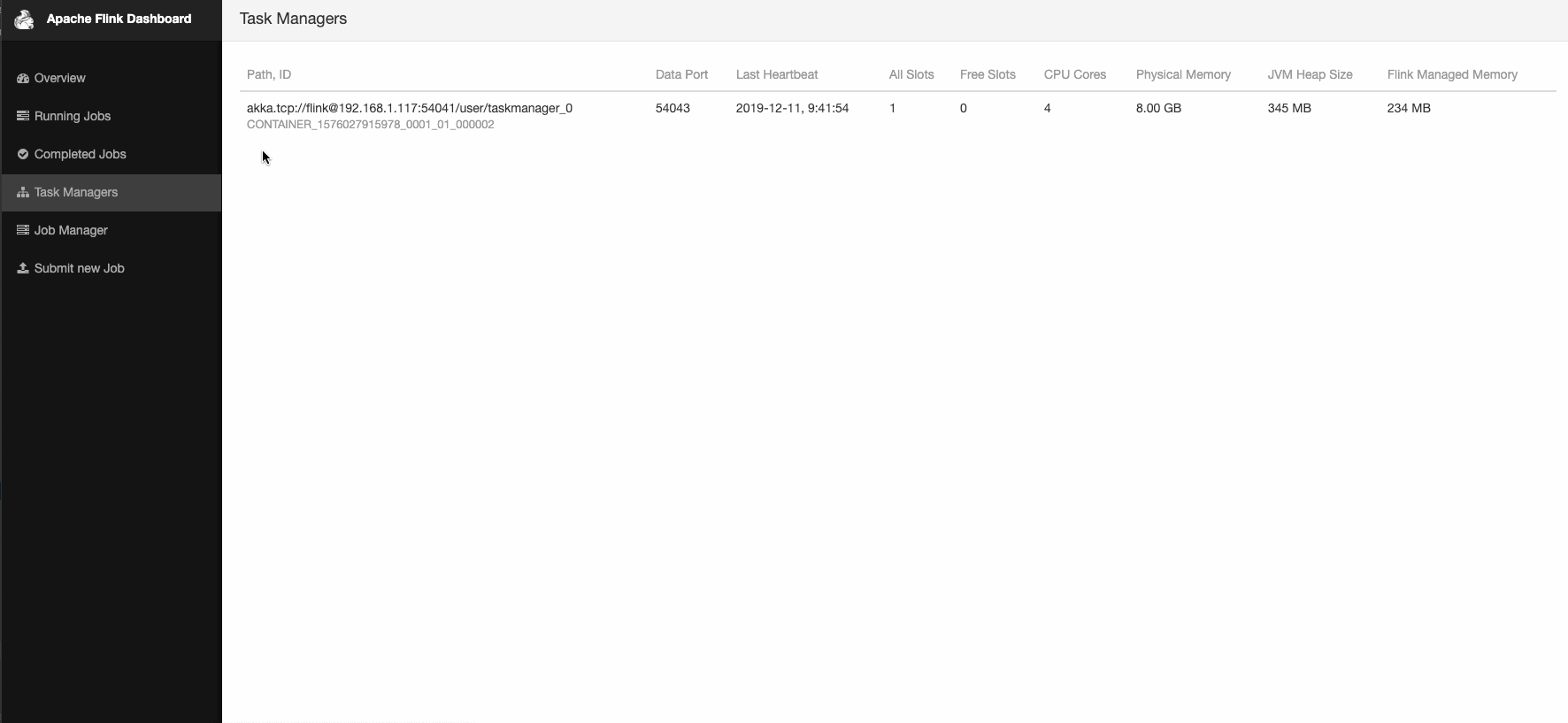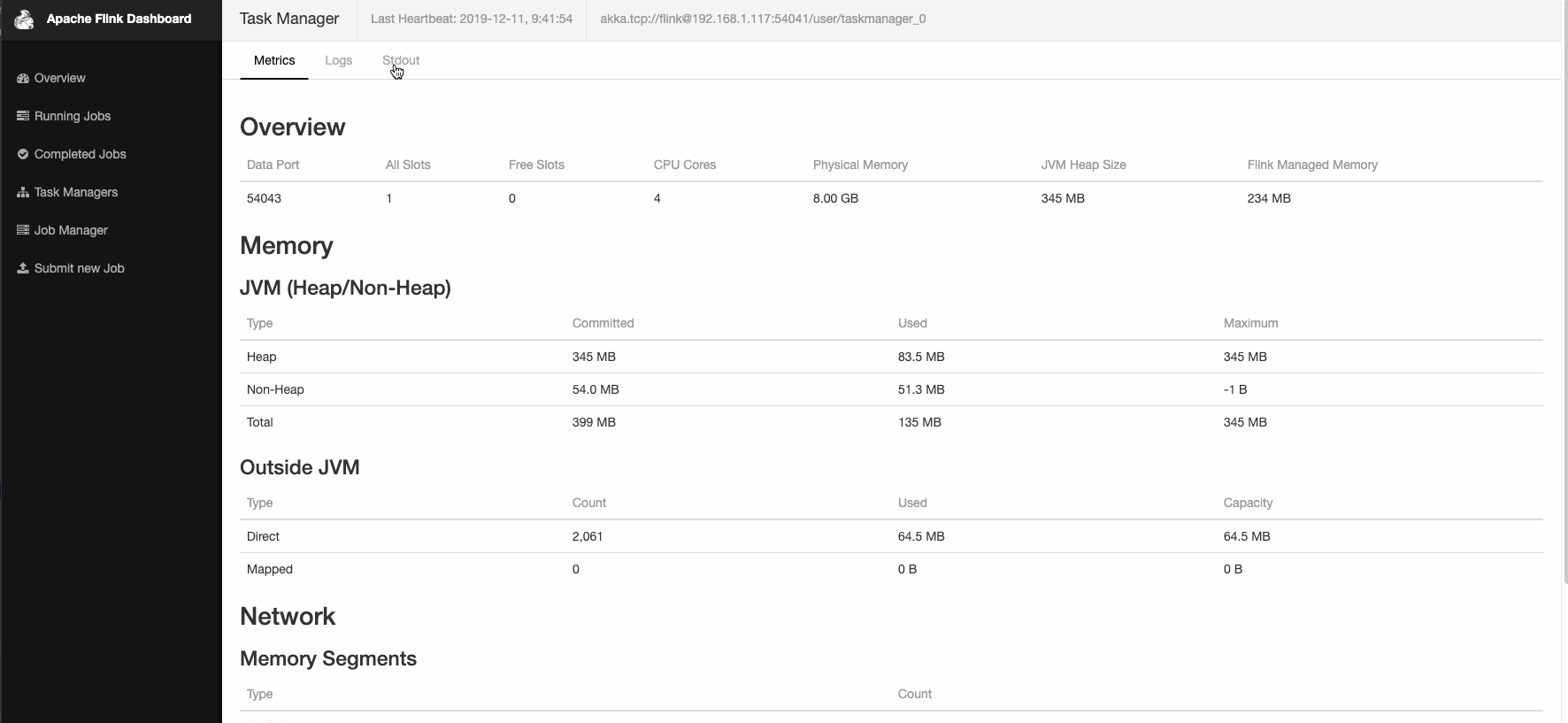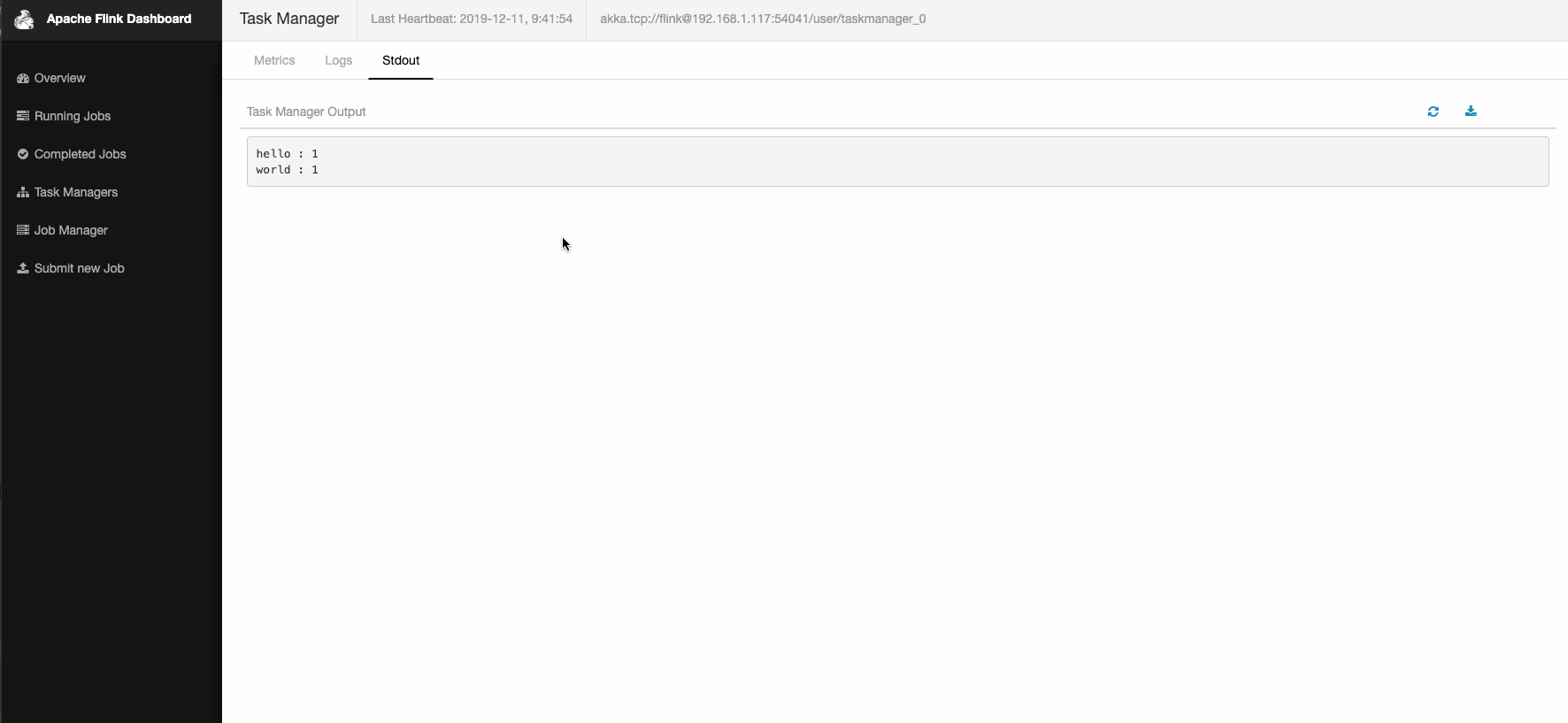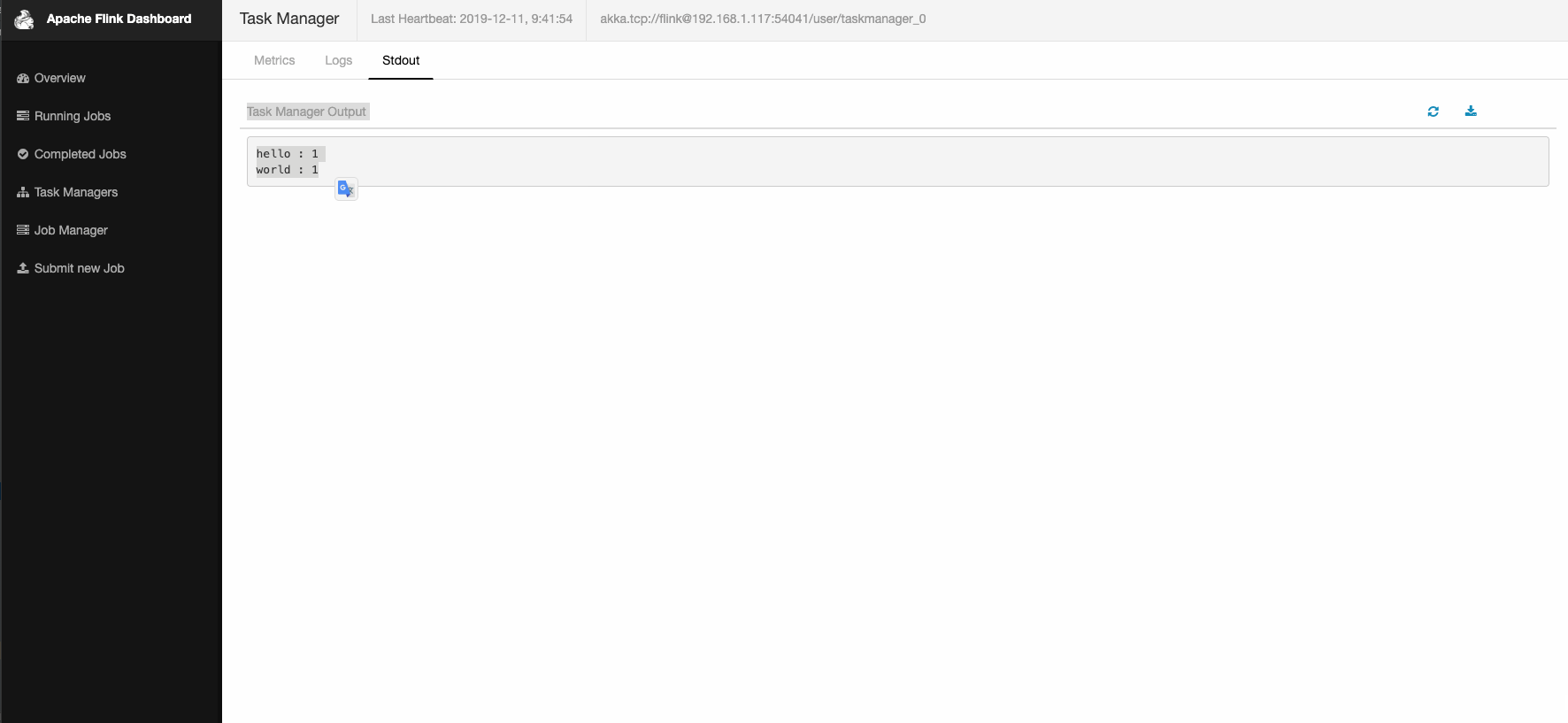
提交job时,我们也可以指定一些参数,详情查看第1部分的参数列表。
3 Session模式
3.1 描述
Per-Job还是存在局限,YARN App的提交时资源申请和启动TM的时间较长(秒级),尤其在交互式分析短查询等场景上,Job计算逻辑执行时间很短,那么App的启动时间占比大就严重影响了端到端的用户体验,缺少了Standalone模式上Job提交快的优点。但FLIP-6架构的威力,还是能轻松化解这个问题,如下图所示,通过预启动的YARN App来跑一个Flink Session(Master和多个TM已启动,类似Standalone可运行多个Job),再提交执行Job,这些Job就可以很快利用已有的资源来执行计算。Blink分支与Master具体实现有点不同(是否预起TM),后续会合并统一,并且继续开发实现Session的资源弹性——按需自动扩缩TM数量,这点是standalone无法实现的。
3.2 Session模式下提交Job
启动Flink集群
./bin/yarn-session.sh -n 2 -jm 1024m -tm 2048-n 指定container参数为2个
-jm 指定jobmanager内存为1024mb
-tm 指定taskmanager内存为2048
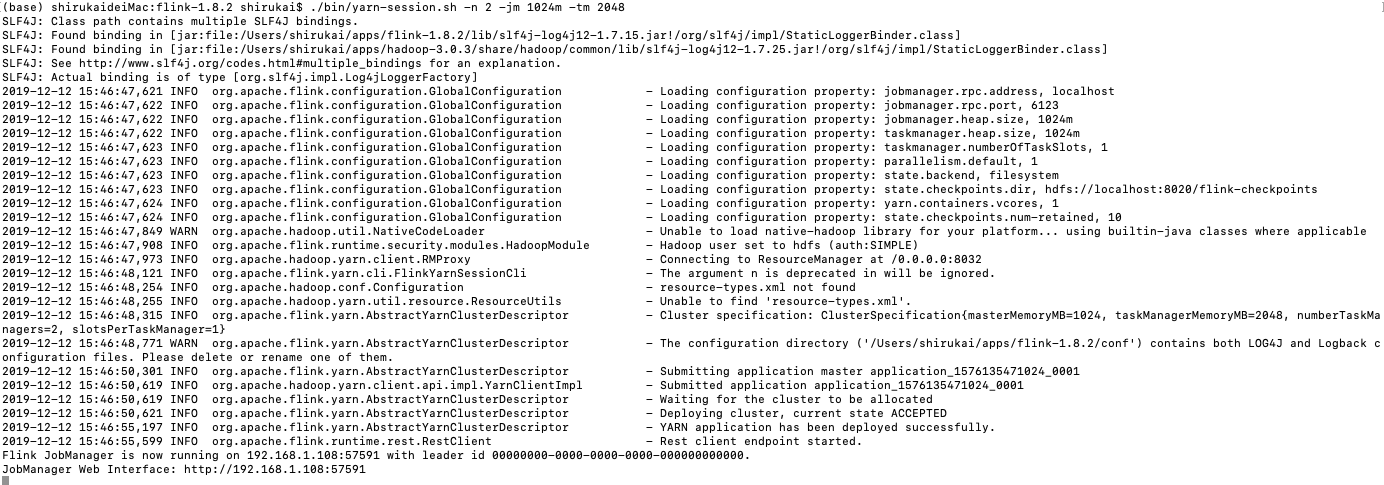
根据日志信息
JobManager Web Interface: http://192.168.1.108:57591我们通过浏览器访问该地址: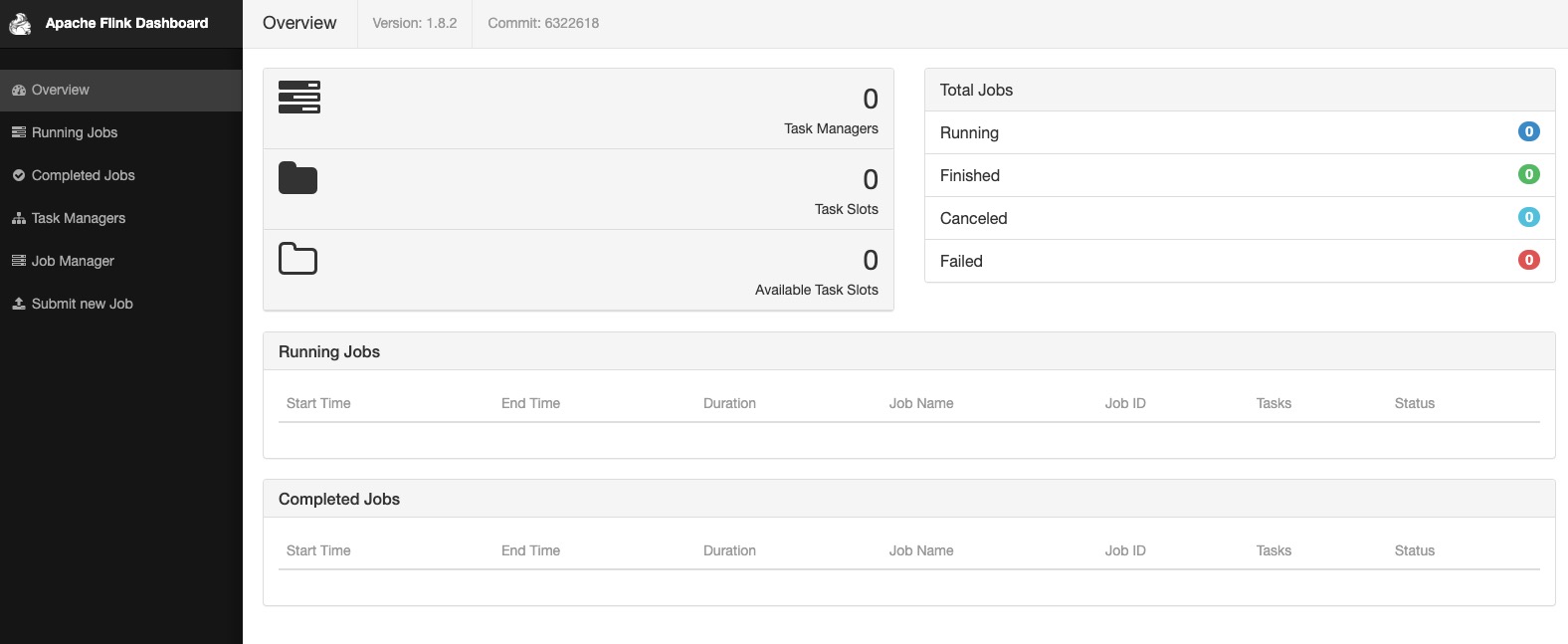
提交Flink job到Flink集群,这里还以SocketWindowWordCount为例,所以需要我们先使用
nc -lk 9090监听端口,然后执行如下命令提交job注意:这里需要从上一步的日志中找到我们再YARN上启动的Application ID,例如这里拿到的ID为:application_1576135471024_0001,我们需要通过-yid指定该参数
./bin/flink run -yid application_1576135471024_0001 examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9090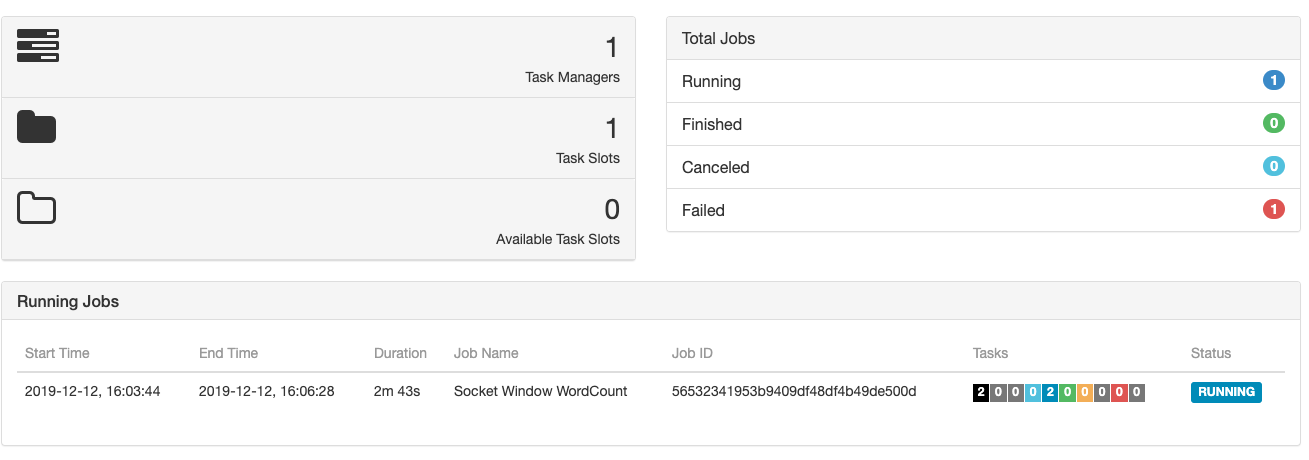
同样在socket命令窗口,输入单词hello world,查看TaskManager里的输出。
停止集群
有两种方式停止Session集群:
方式1
echo stop | ./bin/yarn-serssion.sh -id <application_id>方式2
yarn application -kill <application_id>
4 YARN模式下HighAvailability配置
Flink在YARN模式下的高可用,并不会启动多个Jobmanager实例来实现高可用,而是依赖YARN失败重启机制。
先要确保启动 Yarn 集群用的“yarn-site.xml”文件中的这个配置,这个是 Yarn 集群级别 AM 重启的上限。
<property> <name>yarn.resourcemanager.am.max-attempts</name> <value>20</value> <description> The maximum number of application master execution attempts. </description> </property>在conf/flink-conf.yaml文件中配置Flink Jobmanager能够重启的数量
yarn.application-attempts: 10 # 1+ 9 retriesHA依赖ZK,同样需要在conf/flink-conf.yaml文件中进行zk相关的配置
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'. high-availability: zookeeper # jobmanager的元数据存放在dfs,zk里只存路径。这里要求指定所有节点都可以访问的分布式存储(like HDFS, S3, Ceph, nfs, ...) high-availability.storageDir: hdfs:///flink/ha/ # zk地址 high-availability.zookeeper.quorum: localhost:2181
5 错误问题汇总
4.1 Could not identify hostname and port in ‘yarn-cluster’
错误信息:
在向YARN提交任务的时候报如下错误
------------------------------------------------------------
The program finished with the following exception:
java.lang.RuntimeException: Could not identify hostname and port in 'yarn-cluster'.
at org.apache.flink.client.ClientUtils.parseHostPortAddress(ClientUtils.java:47)
at org.apache.flink.client.cli.AbstractCustomCommandLine.applyCommandLineOptionsToConfiguration(AbstractCustomCommandLine.java:83)
at org.apache.flink.client.cli.DefaultCLI.createClusterDescriptor(DefaultCLI.java:60)
at org.apache.flink.client.cli.DefaultCLI.createClusterDescriptor(DefaultCLI.java:35)
at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:224)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
at org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
原因分析:
Flink客户端向YARN提交任务,需要YARN的相关依赖,通过这些依赖包,客户端会找到YARN ResourceManager的地址,并向其提交任务。由于环境中不具备这些依赖,就会报日志中所述的错误。
解决方法:
解决这个问题,有两种方法:
从官网下载HADOOP相关的依赖,并将其放到FLINK_HOME/lib/目录下。
地址:https://flink.apache.org/downloads.html,按照需求下载hadoop依赖,例如[Pre-bundled Hadoop 2.7.5](https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-7.0/flink-shaded-hadoop-2-uber-2.7.5-7.0.jar) (asc, sha1)
在环境中配置HADOOP_CLASSPATH变量
https://ci.apache.org/projects/flink/flink-docs-stable/ops/deployment/hadoop.html
export HADOOP_CLASSPATH=`hadoop classpath`
4.2 The number of requested virtual cores per node 1 exceeds the maximum number of virtual cores 0 available in the Yarn Cluster. Please note that the number of virtual cores is set to the number of task slots by default unless configured in the Flink config with ‘yarn.containers.vcores.’
错误信息:
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster
at org.apache.flink.yarn.AbstractYarnClusterDescriptor.deploySessionCluster(AbstractYarnClusterDescriptor.java:387)
at org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:259)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
at org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)
at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
Caused by: org.apache.flink.configuration.IllegalConfigurationException: The number of requested virtual cores per node 1 exceeds the maximum number of virtual cores 0 available in the Yarn Cluster. Please note that the number of virtual cores is set to the number of task slots by default unless configured in the Flink config with 'yarn.containers.vcores.'
at org.apache.flink.yarn.AbstractYarnClusterDescriptor.isReadyForDeployment(AbstractYarnClusterDescriptor.java:259)
at org.apache.flink.yarn.AbstractYarnClusterDescriptor.deployInternal(AbstractYarnClusterDescriptor.java:459)
at org.apache.flink.yarn.AbstractYarnClusterDescriptor.deploySessionCluster(AbstractYarnClusterDescriptor.java:380)
... 9 more
原因分析:
YARN虚拟核数不够导致此错误
解决方法:
https://issues.apache.org/jira/browse/FLINK-9013
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>5</value>
</property>

Contents
- 5.1. 4.1 Could not identify hostname and port in ‘yarn-cluster’
- 5.2. 4.2 The number of requested virtual cores per node 1 exceeds the maximum number of virtual cores 0 available in the Yarn Cluster. Please note that the number of virtual cores is set to the number of task slots by default unless configured in the Flink config with ‘yarn.containers.vcores.’