官网位置:https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/dev/stream/operators/
Operators transform one or more DataStreams into a new DataStream. Programs can combine multiple transformations into sophisticated dataflow topologies.
算子可以将一个或多个DataStream转化为新的DataStream。程序可以将多种转换组合成复杂的数据流拓扑。下面将介绍一下Flink DataStream API中一些常用的算子,注意:本文是以Scala代码为例,有些语法在Java里不通用。
1 DataStream Transformations
官网以表格的形式列了一些转换类的算子,有些可能不好理解,这里以实际的代码例子进行演示。
DataStream常用转换如下图所示:
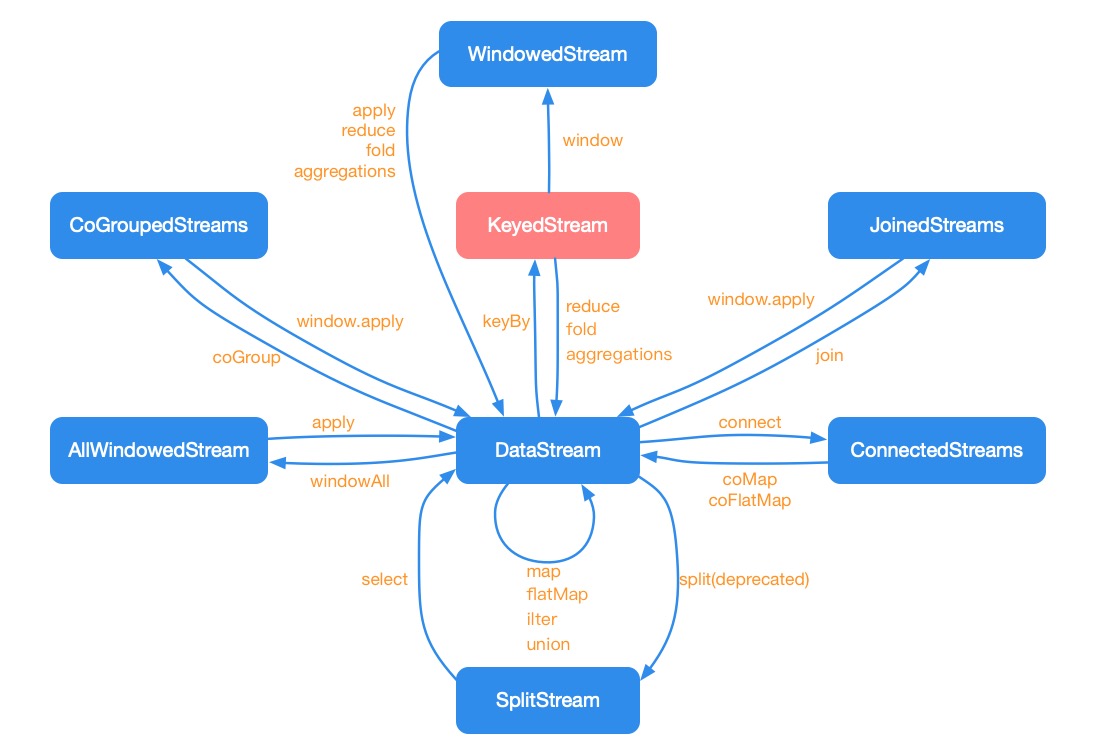
1.1 map
类型转换:
DataStream->DataStream
描述:
熟悉scala的同学,对于这个map应该很好理解,map操作是依次取DataStream中一个元素并生成另一个元素。
调用方式:
- 传入一个继承自MapFunction[T,R]的实例
def map[R: TypeInformation](mapper: MapFunction[T, R]): DataStream[R]
- 函数式调用,传入一个参数类型为T,返回值为R的函数
def map[R: TypeInformation](fun: T => R): DataStream[R]
代码演示:
先通过1到10的集合生成一个DataStream,并通过map操作,将其每个元素都乘以2,生成新的DataStream。
// create DataStream from collection
val data = env.fromCollection(1 to 10)
// 将每个元素*2
data.map(_ * 2).print("map")
输出:
map:7> 10
map:4> 4
map:3> 2
map:2> 16
map:8> 12
map:6> 8
map:5> 6
map:1> 14
map:3> 18
map:4> 20
1.2 flatMap
类型转换:
DataStream->DataStream
描述:
flatMap与map类似,只是它是依次取DataStream中的一个元素生成0个或多个元素。
调用方式:
它在scala里提供了三种调用方式:
- 传入一个继承自FlatMapFunction[T, R]的类实例
def flatMap[R: TypeInformation](flatMapper: FlatMapFunction[T, R]): DataStream[R]
- 传入参数为T和Collector[R]无返回值的函数
def flatMap[R: TypeInformation](fun: (T, Collector[R]) => Unit): DataStream[R]
- 传入参数类型为T,返回值类型为TraversableOnce(集合特质,常见集合都继承该特质)的函数
def flatMap[R: TypeInformation](fun: T => TraversableOnce[R]): DataStream[R]
代码演示:
先通过Array(1,2,3)和Array(4,5,6)两个元素生成一个DataStream,并通过flatMap操作,将两个数组展开
// create DataStream from elements
val data = env.fromElements(Array(1,2,3),Array(4,5,6))
// 将数据展开
data.flatMap(_.toList).print("flatMap")
结果:
flatMap:1> 4
flatMap:8> 1
flatMap:1> 5
flatMap:8> 2
flatMap:1> 6
flatMap:8> 3
1.3 filter
类型转换:
DataStream->DataStream
描述:
按照条件过滤,得到满足条件的元素生成新的DataStream
调用方式:
调用方式有两种:
- 传入一个继承自FilterFunction[T]类实例
def filter(filter: FilterFunction[T]): DataStream[T]
- 传入一个入参类型为T,返回值类型为Boolean的函数
def filter(fun: T => Boolean): DataStream[T]
代码演示:
先通过1 到10的集合生成一个DataStream,并通过filter操作,过滤出奇数
// create DataStream from collection
val data = env.fromCollection(1 to 10)
// 输出奇数
data.filter(_ % 2 == 1).print("filter")
输出:
filter:3> 1
filter:5> 3
filter:7> 5
filter:1> 7
filter:3> 9
1.4 keyBy
类型转换:
DataStream->KeyedStream
描述:
根据指定的Key选择器,进行分区,生成KeyedStream
调用方式:
在scala里key选择器有四种指定方式:
- 对于tuple和array类型,我们可以指定一个或多个key的位置
def keyBy(fields: Int*): KeyedStream[T, JavaTuple]
- 指定一个或多个key的字段表达式
def keyBy(firstField: String, otherFields: String*): KeyedStream[T, JavaTuple]
- 传入key选择函数
def keyBy[K: TypeInformation](fun: T => K): KeyedStream[T, K]
- 实现key选择器KeySelector,并传入该实例
def keyBy[K: TypeInformation](fun: KeySelector[T, K]): KeyedStream[T, K]
代码演示:
先通过集合生成一个DataStream,然后根据第一个元素进行KeyBy
// create DataStream from collection
val data = env.fromCollection(List(("device-1", 1), ("device-2", 2), ("device-1", 2)))
data.keyBy(_._1)
输出:
keyed:3> (device-2,2)
keyed:1> (device-1,1)
keyed:1> (device-1,2)
1.5 reduce
类型转换:
KeyedStream->DataStream
描述:
在KeyedStream上,将当前值以及上次计算结果应用到指定的reduce函数中得到新的值,依次计算
调用方式:
在scala里reduce调用有两种方式:
- 实现ReduceFunction[T]接口中的reduce方法,并传入该实例
def reduce(reducer: ReduceFunction[T]): DataStream[T]
- 传入参数类型为T,T返回值为T的函数
def reduce(fun: (T, T) => T): DataStream[T]
代码演示:
将上面KeyBy之后生成的KeyedStream,应用reduce算子,进行累加
keyedStream.reduce((value1, value2) => {
(value1._1, value1._2 + value2._2)
}).print("reduce")
输出:
reduce:1> (device-1,1)
reduce:3> (device-2,2)
reduce:1> (device-1,3)
1.6 fold(deprecated)
类型转换:
KeyedStream->DataStream
描述:
在KeyedStream上,与reduce类似,只是多了一个初始值。
调用方式:
在scala里fold调用有两种方式:
- 实现FoldFunction[T,R]接口中的fold方法,并传入该实例,另外还需要传入初始化值。
def fold[R: TypeInformation](initialValue: R, folder: FoldFunction[T,R]):
DataStream[R]
- 柯里化传参,第一个参数为初始值,第二个参数为函数表达式
def fold[R: TypeInformation](initialValue: R)(fun: (R,T) => R): DataStream[R]
代码演示:
将上面KeyBy之后生成的KeyedStream,应用fold算子,进行字符串拼接
keyedStream.fold("start")((accumulator, value) => {
s"$accumulator-${value._1}-${value._2}"
}).print("fold")
输出:
fold:1> start-device-1-1
fold:3> start-device-2-2
fold:1> start-device-1-1-device-1-2
1.7 aggregations
类型转换:
KeyedStream->DataStream
描述:
在KeyedStream上,应用聚合方法,Flink提供内置的聚合方法有:sum、min、minBy、maxBy。这里解释一下min和minBy,max和maxBy之间的却别。以max和maxBy为例,max(position|field)只是返回指定的position或field的最大值,其它字段的值为第一次出现的记录值,而maxBy(position|field)则是返回position或field最大值所在的记录。怎么理解呢?假如streamData:DataStream[DeviceEvent]有两条记录 DeviceEvent(1,1,1)、 DeviceEvent(2,2,2),即
val streamData:DataStream[DeviceEvent]=env.fromElements(DeviceEvent(1,1,1),DeviceEvent(2,2,2))
我们通过按照第一个元素keyBy,然后按照第二个元素max
streamData.keyBy(0).max(1)
我们会得到结果:
1,1,1
1,2,1
如果我们同样按照第一个元素keyBy,但是按照第二个元素maxBy
streamData.keyBy(0).maxBy(1)
将会得到如下结果:
1,1,1
2,2,2
min和minBy同理。
调用方式:
flink内置聚合方法在scala里的调用方式有两种:
- 传入position参数
def sum(position: Int): DataStream[T]
- 传入field参数
def sum(field: String): DataStream[T]
代码演示:
演示这几种聚合方法
// create DataStream from collection
val data: DataStream[(String, Int, String)] = env.fromCollection(List(("device-1", 3, "1-3"), ("device-1", 1, "1-1"), ("device-2", 2, "2-2"), ("device-1", 2, "1-2")))
val keyedStream = data.keyBy(0)
keyedStream.sum(1).print("sum")
keyedStream.min(1).print("min")
keyedStream.max(1).print("max")
keyedStream.minBy(1).print("minBy")
keyedStream.maxBy(1).print("maxBy")
输出:
sum:3> (device-2,2,2-2)
max:3> (device-2,2,2-2)
min:1> (device-1,3,1-3)
maxBy:3> (device-2,2,2-2)
maxBy:1> (device-1,3,1-3)
minBy:1> (device-1,3,1-3)
sum:1> (device-1,3,1-3)
max:1> (device-1,3,1-3)
minBy:3> (device-2,2,2-2)
min:3> (device-2,2,2-2)
max:1> (device-1,3,1-3)
minBy:1> (device-1,1,1-1)
maxBy:1> (device-1,3,1-3)
max:1> (device-1,3,1-3)
min:1> (device-1,1,1-3)
minBy:1> (device-1,1,1-1)
sum:1> (device-1,4,1-3)
min:1> (device-1,1,1-3)
maxBy:1> (device-1,3,1-3)
sum:1> (device-1,6,1-3)
1.8 window
类型转换:
KeyedStream->WindowedStream
描述:
在KeyedStream上的窗口装换,Flink提供了四种窗口类型:Tumbling Windows(滚动窗口)、Sliding Windows(滑动窗口)、Session Windows(会话窗口)、Global Windows(全局窗口),滚动窗口和滑动窗口分为基于时间的窗口和基于个数的窗口,而基于时间的窗口又分为事件时间窗口和处理时间窗口。关于窗口的更多内容会在下一篇文章中记录,这里只做简单演示。
调用方式:
window在scala里的调用方式有五种:
- timeWindow(size: Time),传入类型为Time的窗口大小,Flink会根据指定的time characteristic来判断是处理时间滚动窗口还是事件时间滚动窗口。
def timeWindow(size: Time): WindowedStream[T, K, TimeWindow]
- timeWindow(size: Time, slide: Time),传入类型为Time的窗口大小,以及类型为Time的窗口滑动大小,Flink同样会根据指定的time characteristic来判断是处理时间滑动窗口还是事件时间滑动窗口。
def timeWindow(size: Time, slide: Time): WindowedStream[T, K, TimeWindow]
- countWindow(size: Long),传入Long类型的窗口大小,Flink会应用为基于个数的滚动窗口。
def countWindow(size: Long): WindowedStream[T, K, GlobalWindow]
- countWindow(size: Long, slide: Long),传入Long类型的窗口大小,以及Long类型的窗口滑动带下,生成基于个数的滑动窗口。
def countWindow(size: Long, slide: Long): WindowedStream[T, K, GlobalWindow]
- window,需要传入WindowAssigner实例
def window[W <: Window](assigner: WindowAssigner[_ >: T, W]): WindowedStream[T, K, W]
代码演示:
// create data from collection
val data = env.fromCollection(1 to 10)
data.countWindowAll(5)
1.9 windowAll
类型转换:
DataStream->AllWindowedStream
描述:
在DataStream上的窗口装换,与window类似,只是window应用在KeyedStream上,需要先进行KeyBy操作,windowAll可以直接应用到DataStream上。
调用方式:
window在scala里的调用方式有五种:
- timeWindowAll(size: Time)传入类型为Time的窗口大小,Flink会根据指定的time characteristic来判断是处理时间滚动窗口还是事件时间滚动窗口。
def timeWindowAll(size: Time): AllWindowedStream[T, TimeWindow]
- timeWindow(size: Time, slide: Time),传入类型为Time的窗口大小,以及类型为Time的窗口滑动大小,Flink同样会根据指定的time characteristic来判断是处理时间滑动窗口还是事件时间滑动窗口。
def timeWindowAll(size: Time, slide: Time): AllWindowedStream[T, TimeWindow]
- countWindow(size: Long),传入Long类型的窗口大小,Flink会应用为基于个数的滚动窗口。
def countWindowAll(size: Long, slide: Long): AllWindowedStream[T, GlobalWindow]
- countWindow(size: Long, slide: Long),传入Long类型的窗口大小,以及Long类型的窗口滑动带下,生成基于个数的滑动窗口。
def countWindowAll(size: Long): AllWindowedStream[T, GlobalWindow]
- windowAll,需要传入WindowAssigner实例
windowAll[W <: Window](assigner: WindowAssigner[_ >: T, W]): AllWindowedStream[T, W]
代码演示:
// create data from collection
val data = env.fromCollection((1 to 10).map(x => (x % 2, x)))
// get KeyedDataStream
val keyedStream = data.keyBy(0)
val windowStream = keyedStream.countWindow(5)
输出:
windowStream.sum(1).print("countWindow")
countWindow:6> (1,25)
countWindow:6> (0,30)
1.10 WindowedStream apply
类型转换:
WindowedStream->DataStream
描述:
在WindowedStream上应用WindowFunction,当窗口被触发时调用指定的WindowFunction。
调用方式:
apply在scala里的调用方式有两种(其它预聚合的调用方式已废弃):
- 继承WindowFunction实现apply方法,并传入该实例
def apply[R: TypeInformation](
function: WindowFunction[T, R, K, W]): DataStream[R]
- 传入匿名函数
def apply[R: TypeInformation](
function: (K, W, Iterable[T], Collector[R]) => Unit): DataStream[R]
代码演示:
在上面生成的windowStream调用apply
val dataStream = windowedStream.apply((key, window, input, out: Collector[(Int, String, Int)]) => {
var sum = 0
input.foreach(element => {
sum += element._2
})
out.collect(key.getField(0), window.toString, sum)
})
dataStream.print("simple apply")
输出:
simple apply:6> (1,GlobalWindow,25)
simple apply:6> (0,GlobalWindow,30)
1.11 WindowedStream reduce
类型转换:
WindowedStream->DataStream
描述:
在WindowedStream上应用ReduceFunction,与DataStream上的ReduceFunction相同,当窗口被触发时调用指定的ReduceFunction。
调用方式:
reduce在scala里的调用方式有六种,其中包括几种预聚合的方式调用:
- 继承ReduceFunction实现reduce方法,并传入该实例
def reduce(function: ReduceFunction[T]): DataStream[T]
- 传入匿名函数
def reduce(function: (T, T) => T): DataStream[T]
- 传入ReduceFunction[T]作为预聚合器,当数据到达时调用,传入WindowFunction作为窗口函数,当触发窗口计算的时候调用。
def reduce[R: TypeInformation](
preAggregator: ReduceFunction[T],
function: WindowFunction[T, R, K, W]): DataStream[R]
- 传入匿名函数作为预聚合器,当数据到达时调用,传入WindowFunction作为窗口函数,当触发窗口计算的时候调用。
def reduce[R: TypeInformation](
preAggregator: (T, T) => T,
windowFunction: (K, W, Iterable[T], Collector[R]) => Unit): DataStream[R]
- 传入匿名函数作为预聚合器,当数据到达时调用,传入ProcessWindowFunction作为窗口函数,当触发窗口计算的时候调用。
def reduce[R: TypeInformation](
preAggregator: (T, T) => T,
function: ProcessWindowFunction[T, R, K, W]): DataStream[R]
- 传入ReduceFunction[T]作为预聚合器,当数据到达时调用,传入ProcessWindowFunction作为窗口函数,当触发窗口计算的时候调用。
def reduce[R: TypeInformation](
preAggregator: ReduceFunction[T],
function: ProcessWindowFunction[T, R, K, W]): DataStream[R]
代码演示:
在上面生成的windowStream调用reduce
windowedStream.reduce(new ReduceSum).print("function reduce")
windowedStream.reduce((value1, value2) => (value2._1, value1._2 + value2._2)).print("simple reduce")
输出:
simple reduce:6> (1,25)
function reduce:6> (1,25)
simple reduce:6> (0,30)
function reduce:6> (0,30)
1.11 WindowedStream fold(deprecated)
deprecated
1.12 WindowedStream aggregations
类型转换:
WindowedStream->DataStream
描述:
WindowedStream上的聚合函数,与DataStream上的相同,也有sum、min、minBy、max、maxBy,参考DataStream上的aggregations。
调用方式:
参考DataStream上的aggregations。
代码演示:
windowedStream.sum(0).print("sum")
windowedStream.min(0).print("min")
windowedStream.max(0).print("max")
windowedStream.minBy(0).print("minBy")
windowedStream.maxBy(0).print("maxBy")
输出:
maxBy:6> (1,1)
minBy:6> (1,1)
max:6> (1,1)
sum:6> (5,1)
min:6> (1,1)
maxBy:6> (0,2)
minBy:6> (0,2)
max:6> (0,2)
sum:6> (0,2)
min:6> (0,2)
1.13 union
类型转换:
DataStream[T],DataStream[T],*->DataStream[T]
描述:
将两个或更多的流进行合并,要求数据类的类型是一直的。
调用方式:
该算子调用方式只有一种:
- 传入不定长的DataStream[T]
def union(dataStreams: DataStream[T]*): DataStream[T]
代码演示:
先通过1 到10的集合生成一个DataStream,并通过filter操作,过滤出奇数
val stream1 = env.fromCollection(1 to 10)
val stream2 = env.fromCollection(101 to 110)
stream1.union(stream2).print("union")
输出:
union:4> 1
union:7> 101
union:4> 9
union:2> 104
union:3> 105
union:5> 107
union:5> 2
union:1> 103
union:6> 108
union:1> 6
union:6> 3
union:8> 102
union:5> 10
union:2> 7
union:4> 106
union:3> 8
union:7> 109
union:8> 110
union:7> 4
union:8> 5
1.13 join
类型转换:
DataStream[T],DataStream[T2]->JoinedStreams[T, T2]
描述:
将两个按照指定的条件流进行join,两个流的数据类型可以不同,需要与窗口函数结合使用。
调用方式:
该算子调用方式只有一种:
- 传入需要Join的DataStream[T2]
def join[T2](otherStream: DataStream[T2]): JoinedStreams[T, T2]
代码演示:
定义两个流,一个是从集合中创建,另一个从socket中创建。
val stream1 = env.fromCollection(List(("device-1", 1), ("device-2", 2)))
val stream2 = env.socketTextStream("localhost", 9090).map(x => {
val token = x.split(" ")
(token(0), token(1))
})
val joinedStream: JoinedStreams[(String, Int), (String, String)]#Where[String]#EqualTo = stream1.join(stream2).where(_._1).equalTo(_._1)
joinedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.apply((first, second) => (first._1, second._2, first._2)).print("join")
使用nc -lk 9090监听9090端口,启动程序后,发送数据:
输出:
union:4> 1
union:7> 101
union:4> 9
union:2> 104
union:3> 105
union:5> 107
union:5> 2
union:1> 103
union:6> 108
union:1> 6
union:6> 3
union:8> 102
union:5> 10
union:2> 7
union:4> 106
union:3> 8
union:7> 109
union:8> 110
union:7> 4
union:8> 5

Contents
- 1. 1 DataStream Transformations
- 1.1. 1.1 map
- 1.2. 1.2 flatMap
- 1.3. 1.3 filter
- 1.4. 1.4 keyBy
- 1.5. 1.5 reduce
- 1.6. 1.6 fold(deprecated)
- 1.7. 1.7 aggregations
- 1.8. 1.8 window
- 1.9. 1.9 windowAll
- 1.10. 1.10 WindowedStream apply
- 1.11. 1.11 WindowedStream reduce
- 1.12. 1.11 WindowedStream fold(deprecated)
- 1.13. 1.12 WindowedStream aggregations
- 1.14. 1.13 union
- 1.15. 1.13 join