根据数据量动态调整Flink应用的算子并行度,在实际业务应用中很常见。对于无状态的算子来说,更改算子并行度非常的容易。但对于有状态的算子来说,调整算子并行度时,需要考虑状态的重新分配。之前文章里提到,Flink中的状态分为键值分区状态、算子列表状态、算子聚合状态、广播状态,那么这些状态在并行度改变时,是如何在子任务实例间迁移的?这篇文章,将分别使用代码示例介绍这四种状态的迁移过程。
1 键值分区状态
键值分区状态,是应用在KeyedStream上的算子里使用的状态,关于状态的知识,可以参考我的另一篇博客:https://blog.csdn.net/shirukai/article/details/102505946。
带有键值分区状态的算子在扩缩容时会根据新的任务数量对键值进行重新分区。也就是说,会重新对key分区,而对应的状态会随着key的迁移而迁移。
1.1 Key分区的知识
这里补充一下key分区的知识,当一条记录被上一个算子处理完,准备发往下一个算子时,如果我们指定了keyBy,Flink计算发往哪一个算子的逻辑如下:
根据key和最大并行度(maxParallelism)计算出KeyGroup的索引
首先理解两个概念:
最大并行度:Flink默认最大并行度为128,可以通过setMaxParallelism的方式来显式指定,关于最大并行度https://ci.apache.org/projects/flink/flink-docs-stable/ops/production_ready.html#set-an-explicit-max-parallelism。
KeyGroup:它是一组Key的集合,为了避免状态迁移时造成的性能影响,Flink并不是每个key都重新分区。而是先将key进行分组,之后一组一组重新分配。关于KeyGroup https://issues.apache.org/jira/browse/FLINK-3755。
Flink拿到这条记录时,会根据Key选择器拿到当前记录的Key,然后取到这个Key的HashCode,再经过Murmur Hash算法进行二次Hash,hash之后的值对最大并行度进行取余操作,所得结果就是KeyGroup的索引。
源码在:org.apache.flink.runtime.state.KeyGroupRangeAssignment
/** * Assigns the given key to a key-group index. * * @param key the key to assign * @param maxParallelism the maximum supported parallelism, aka the number of key-groups. * @return the key-group to which the given key is assigned */ public static int assignToKeyGroup(Object key, int maxParallelism) { return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism); } /** * Assigns the given key to a key-group index. * * @param keyHash the hash of the key to assign * @param maxParallelism the maximum supported parallelism, aka the number of key-groups. * @return the key-group to which the given key is assigned */ public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) { return MathUtils.murmurHash(keyHash) % maxParallelism; }根据下游算子的并行度,算子最大并行度,KeyGroup索引计算下游算子的索引
源码在:org.apache.flink.runtime.state.KeyGroupRangeAssignment
/** * Computes the index of the operator to which a key-group belongs under the given parallelism and maximum * parallelism. * * IMPORTANT: maxParallelism must be <= Short.MAX_VALUE to avoid rounding problems in this method. If we ever want * to go beyond this boundary, this method must perform arithmetic on long values. * * @param maxParallelism Maximal parallelism that the job was initially created with. * 0 < parallelism <= maxParallelism <= Short.MAX_VALUE must hold. * @param parallelism The current parallelism under which the job runs. Must be <= maxParallelism. * @param keyGroupId Id of a key-group. 0 <= keyGroupID < maxParallelism. * @return The index of the operator to which elements from the given key-group should be routed under the given * parallelism and maxParallelism. */ public static int computeOperatorIndexForKeyGroup(int maxParallelism, int parallelism, int keyGroupId) { return keyGroupId * parallelism / maxParallelism; }拿到下游算子的索引之后,Flink就会将当前数据发送给下游算子对应的Channel中。
1.2 键值状态迁移示意图
上面啰嗦一通目的是为了说明,键值状态的迁移,并不是对key进行重新分区,而是对KeyGroup进行重新分区。讲白一点就是,相同KeyGroup的记录,不管并行度如何改变,他们最终会在同一个SubTask中被处理。如下图所示为键值状态迁移的示意图,开始时,并行度为2,12个键值状态按照键值组的方式分成6组并分配到了两个子任务中。接下来改变并行度为3,Flink只会对键值组重新分区,将六组状态按照一定的规则分配到3个子任务中,从图中可以看出,每个子任务中的键值组虽然发生了变化,但是键值组里的元素都是与之前是一致的。接下来改变并行度为1,所有键值组都会分配到一个1任务里。
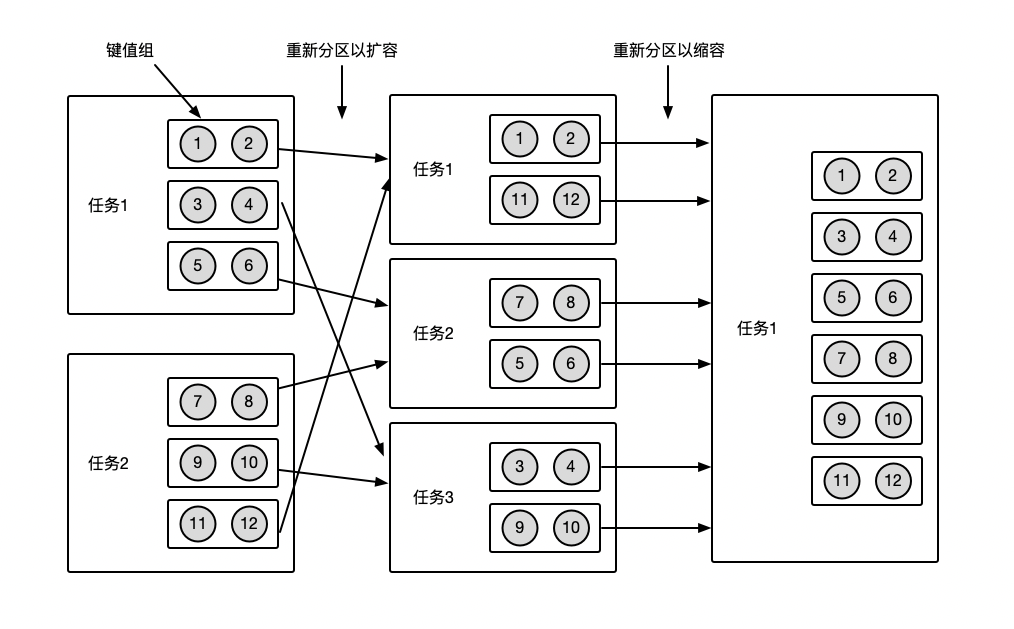
1.3 代码验证
接下来用代码来验证一下上面的迁移过程,由于涉及到并行度修改验证状态迁移,需要我们开启checkpoint,关于如果调试Local模式下带状态的Flink任务,可以参考我之前的文章:https://blog.csdn.net/shirukai/article/details/106926326。
1.3.1 验证场景及代码实现
输入数据结构为(id,value),其中id为设备ID,value为设备值,Flink从socket中实时接收数据,按照Id keyby之后,经过map算子计算累加和,然后将当前算子索引和结果输出到控制台。其中map计算时,需要保存上次计算的累加和到状态中。验证场景是:1.按照准备好的数据放,输出结果与预期相同2. 修改并行度之后,重新发送数据,原本在相同keygroup的状态,会被同一个子任务处理。
代码实现如下:
package com.hollysys.flink.streaming.state.redistribution
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.scala.DataStream
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
/**
* 验证Keyed 状态并行度改变时,重新分配示例
* keyby的每个key会被分到不同的key group中,状态迁移时,是随着key group进行迁移的
* org.apache.flink.runtime.state.KeyGroupRangeAssignment
* @author shirukai
*/
object KeyedStateRedistributionExample {
case class Device(id: String, value: Double)
case class Result(taskNumber: Int, deviceId: String, sum: Double)
def main(args: Array[String]): Unit = {
// 1. 创建本地运行环境
val (env, params) = FlinkLocalEnvUtil.createLocalCheckpointEnv(args)
// 2. 从socket中获取文本
val streamText: DataStream[String] = env.socketTextStream("127.0.0.1", 9000)
.name("SocketSource")
.uid("SocketSource")
// 3. 文本转换为Device样例类
val deviceStream = streamText.map(text => {
val items = text.split(" ")
Device(items(0), items(1).toDouble)
}).setParallelism(1)
.name("FormatDevice")
.uid("FormatDevice")
// 4. 计算累加和
val resultStream = deviceStream.keyBy(_.id).map(new ValueAccumulator)
// 设置并行度为1
.setParallelism(12)
.name("ValueAccumulator")
.uid("ValueAccumulator")
// 5. 输出到控制台
resultStream.print().name("Print").uid("Print")
// 6. execute
env.execute("KeyedStateRedistributionExample")
}
class ValueAccumulator extends RichMapFunction[Device, Result] {
private var accumulatorState: ValueState[Double] = _
override def open(parameters: Configuration): Unit = {
// 获取状态
accumulatorState = getRuntimeContext.getState(new ValueStateDescriptor[Double]("sum-state", classOf[Double]))
}
override def map(value: Device): Result = {
val sum = accumulatorState.value() + value.value
// 更新状态
accumulatorState.update(sum)
Result(getRuntimeContext.getIndexOfThisSubtask, value.id, sum)
}
}
}
1.3.2 准备数据
这里需要造一些比较特别的数据,不然很难测试出我们想要的结果。笔者电脑是6核12线程的,默认flink应用并行度是12。所以我们模拟一些数据,这些数据能够均匀的分配到每个算子上,并且每个算子只有一个KeyGroup,每个KeyGroup里有两条记录。我模拟出来的数据如下,以 “device-1 3 0”为例解释其结构,device-1为key值,3为KeyGroup索引,0为将会下发的算子索引。
[
"device-1 3 0",
"device-97 3 0",
"device-19 14 1",
"device-77 14 1",
"device-5 31 2",
"device-7 31 2",
"device-2 35 3",
"device-433 35 3",
"device-27 44 4",
"device-146 44 4",
"device-16 62 5",
"device-62 62 5",
"device-37 67 6",
"device-360 67 6",
"device-32 85 7",
"device-69 85 7",
"device-17 94 8",
"device-53 94 8",
"device-8 102 9",
"device-71 102 9",
"device-12 112 10",
"device-256 112 10",
"device-13 120 11",
"device-222 120 11"
]
| Key | KeyGroup索引 | 并行度为12时算子索引 |
|---|---|---|
| device-1 | 3 | 0 |
| device-97 | 3 | 0 |
| device-19 | 14 | 1 |
| device-77 | 14 | 1 |
| device-5 | 31 | 2 |
| device-7 | 31 | 2 |
| device-2 | 35 | 3 |
| device-433 | 35 | 3 |
| device-27 | 44 | 4 |
| device-146 | 44 | 4 |
| device-16 | 62 | 5 |
| device-62 | 62 | 5 |
| device-37 | 67 | 6 |
| device-360 | 67 | 6 |
| device-32 | 85 | 7 |
| device-69 | 85 | 7 |
| device-17 | 94 | 8 |
| device-53 | 94 | 8 |
| device-8 | 102 | 9 |
| device-71 | 102 | 9 |
| device-12 | 112 | 10 |
| device-256 | 112 | 10 |
| device-13 | 120 | 11 |
| device-222 | 120 | 11 |
造数程序如下:
/**
* KeyGroup分配测试
*
* @author shirukai
*/
object KeyGroupRangeAssignmentTest {
case class KeyGroup(key: String, group: Int)
def main(args: Array[String]): Unit = {
// 最大并行度
val maxParallelism = 128
// 算子并行度
val parallelism = 12
val map = mutable.SortedMap[Int, mutable.ListBuffer[KeyGroup]]()
for (elem <- 1.until(1000)) {
val key = s"device-$elem"
// 计算KeyGroup索引
val keyGroup = KeyGroupRangeAssignment.assignToKeyGroup(key, maxParallelism)
// 计算算子索引
val index = KeyGroupRangeAssignment.computeOperatorIndexForKeyGroup(maxParallelism, parallelism, keyGroup)
if (!map.contains(index)) {
map.put(index, mutable.ListBuffer(KeyGroup(key, keyGroup)))
} else {
val keyList = map(index)
if (keyList.size < 2) {
val group = keyList.head.group
if (group == keyGroup) {
keyList.append(KeyGroup(key, keyGroup))
}
}
}
}
implicit val formats: AnyRef with Formats = Serialization.formats(NoTypeHints)
println(Serialization.write(map.flatMap(i => {
i._2.map(k => s"${k.key} ${k.group} ${i._1}")
})))
}
}
1.3.3 验证
首次启动程序,然后逐条发送准备好的数据,输出结果中的算子索引与预期的相同。
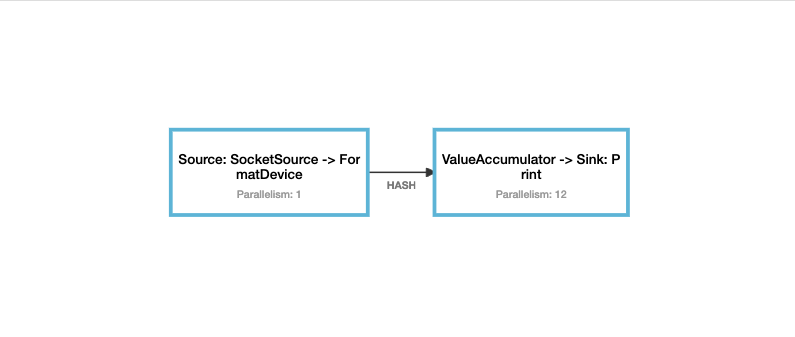
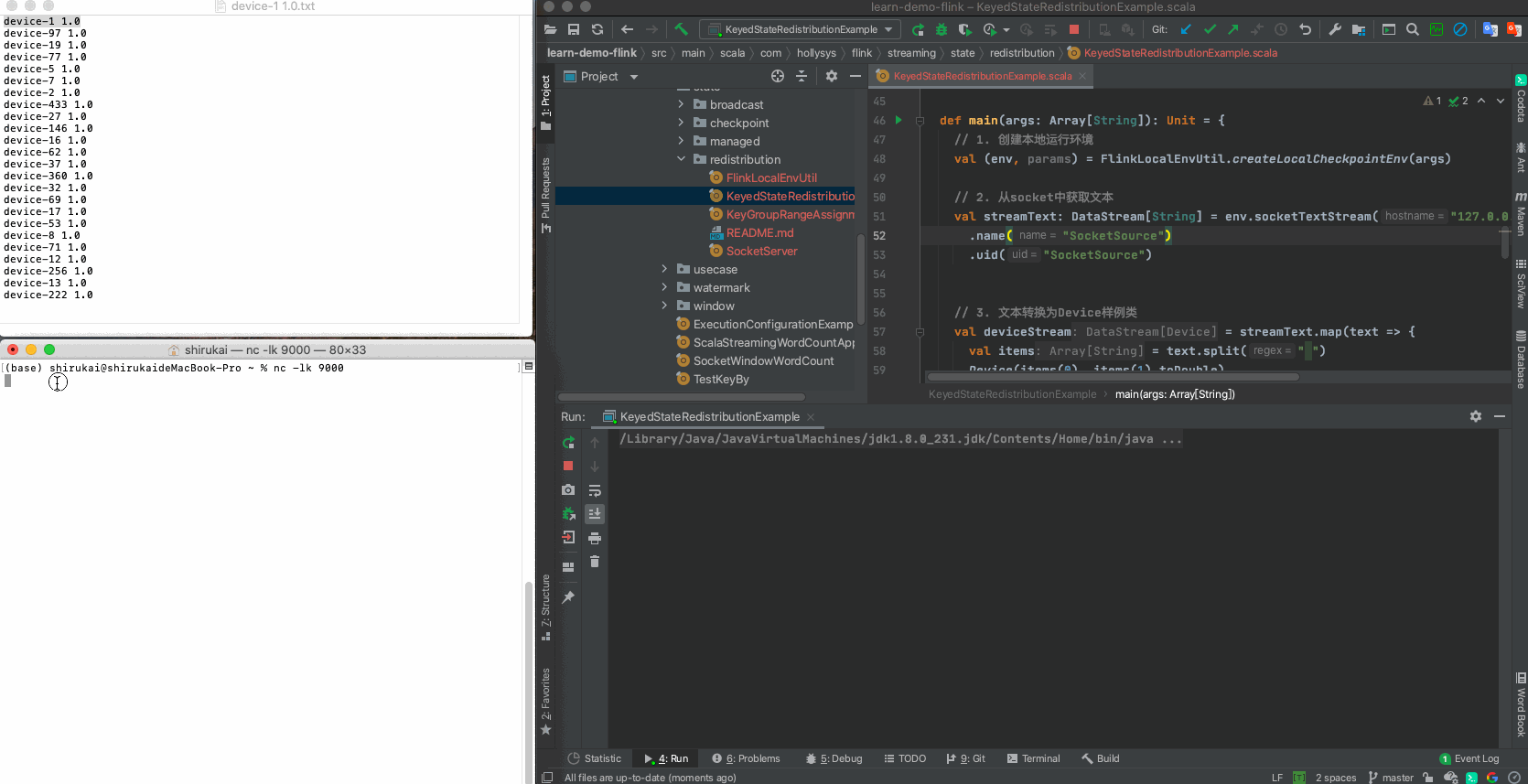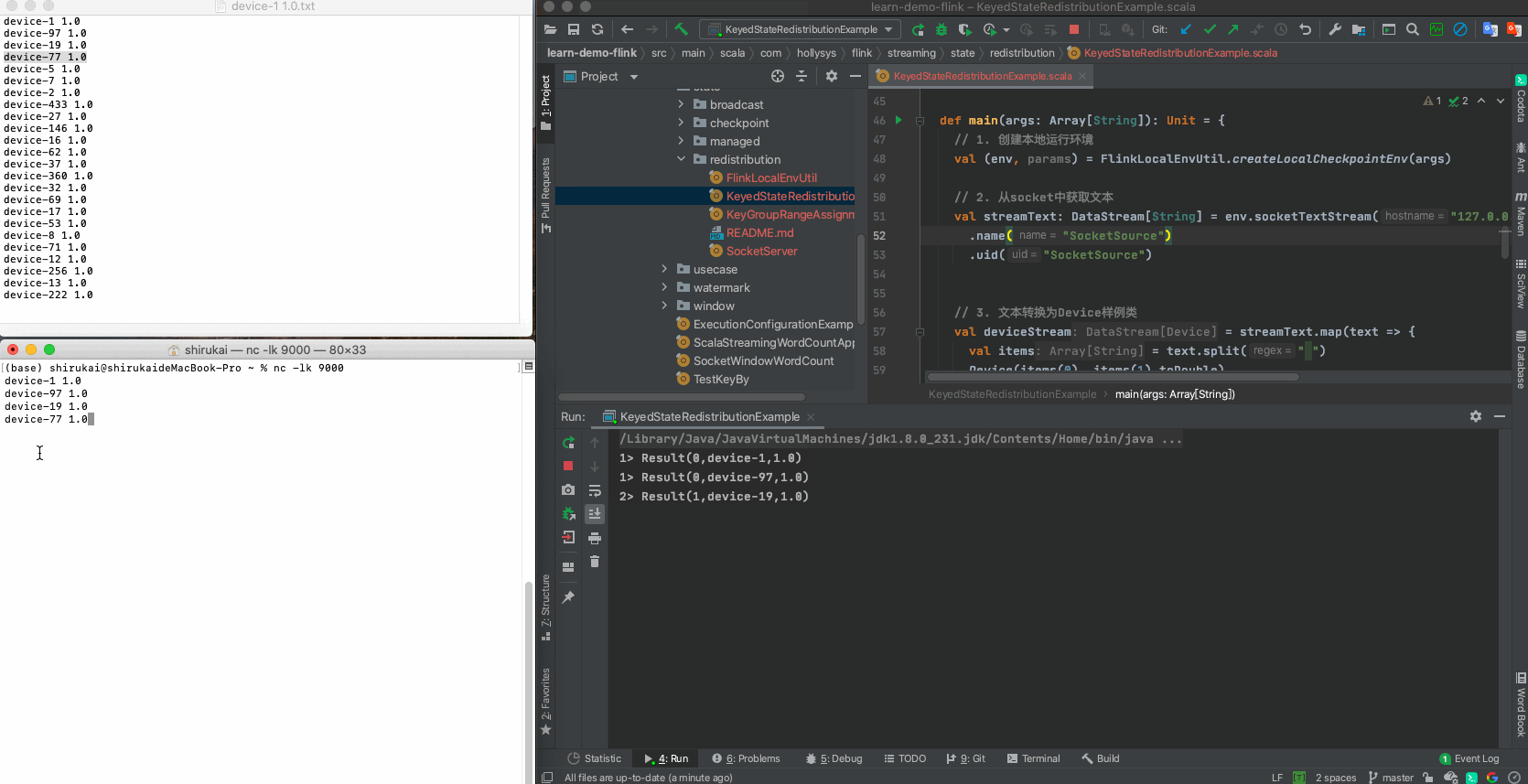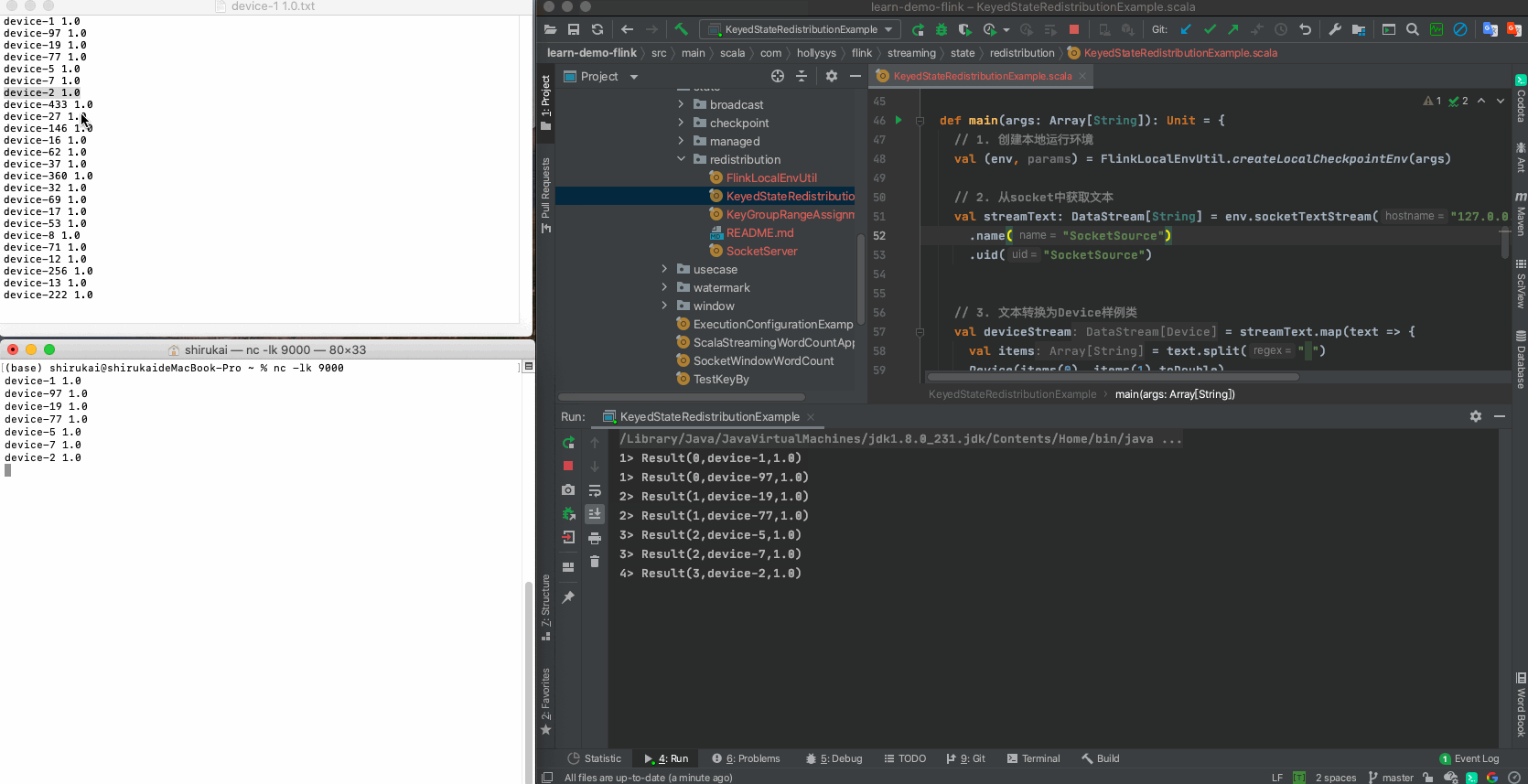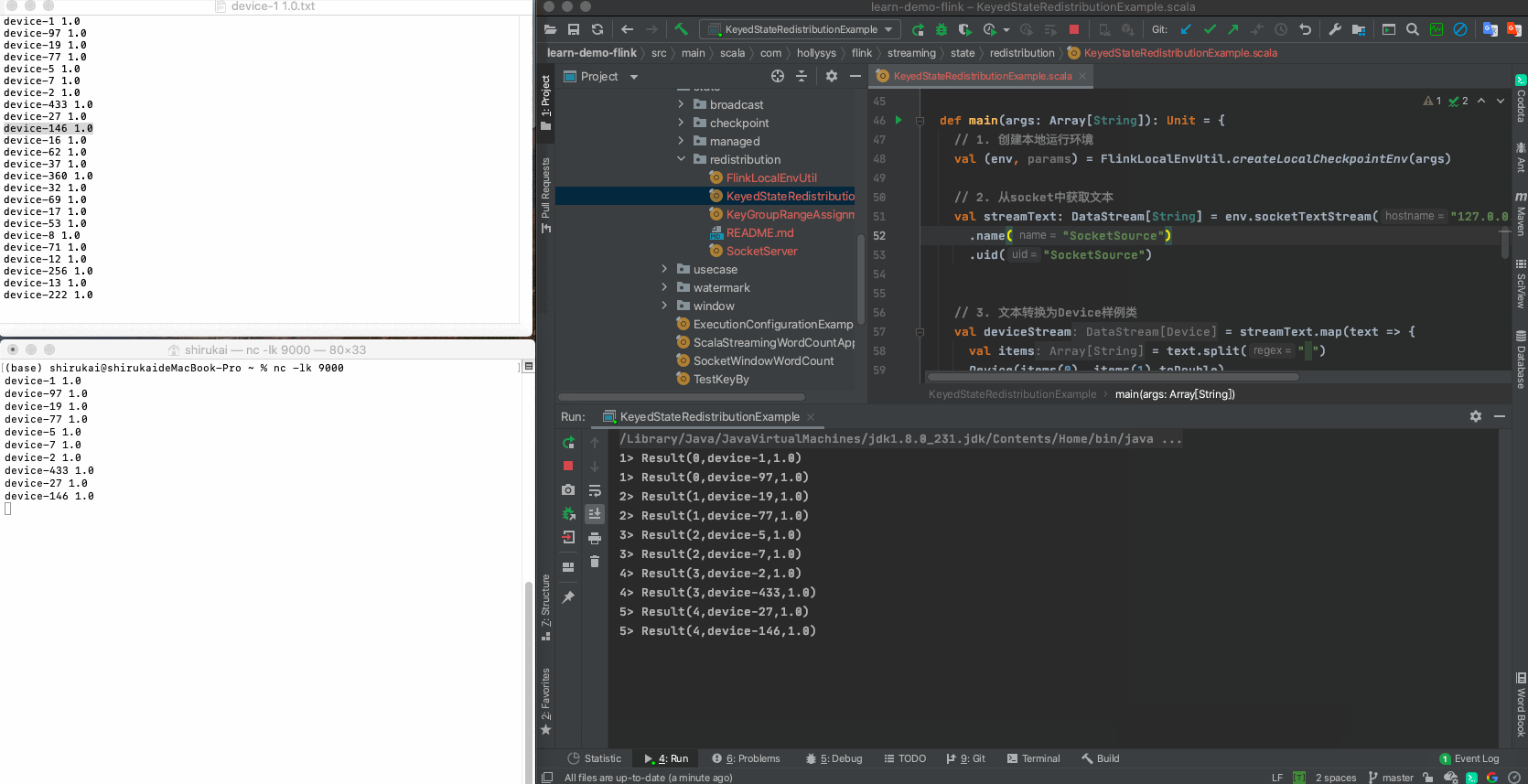
Key KeyGroup索引 并行度为12时算子索引 输入 并行度为12时的预期输出 device-1 3 0 device-1 1.0 Result(0,device-1,1.0) device-97 3 0 device-97 1.0 Result(0,device-97,1.0) device-19 14 1 device-19 1.0 Result(1,device-19,1.0) device-77 14 1 device-77 1.0 Result(1,device-77,1.0) device-5 31 2 device-5 1.0 Result(2,device-5,1.0) device-7 31 2 device-7 1.0 Result(2,device-7,1.0) device-2 35 3 device-2 1.0 Result(3,device-2,1.0) device-433 35 3 device-433 1.0 Result(3,device-433,1.0) device-27 44 4 device-27 1.0 Result(4,device-27,1.0) device-146 44 4 device-146 1.0 Result(4,device-146,1.0) device-16 62 5 device-16 1.0 Result(5,device-16,1.0) device-62 62 5 device-62 1.0 Result(5,device-62,1.0) device-37 67 6 device-37 1.0 Result(6,device-37,1.0) device-360 67 6 device-360 1.0 Result(6,device-360,1.0) device-32 85 7 device-32 1.0 Result(7,device-32,1.0) device-69 85 7 device-69 1.0 Result(7,device-69,1.0) device-17 94 8 device-17 1.0 Result(8,device-17,1.0) device-53 94 8 device-53 1.0 Result(8,device-53,1.0) device-8 102 9 device-8 1.0 Result(9,device-8,1.0) device-71 102 9 device-71 1.0 Result(9,device-71,1.0) device-12 112 10 device-12 1.0 Result(10,device-12,1.0) device-256 112 10 device-256 1.0 Result(10,device-256,1.0) device-13 120 11 device-13 1.0 Result(11,device-13,1.0) device-222 120 11 device-222 1.0 Result(11,device-222,1.0) 停止程序,修改map算子的并行度为6,启动程序,再次发送准备好的数据, 相同KeyGroup的记录,会被同一个算子处理。
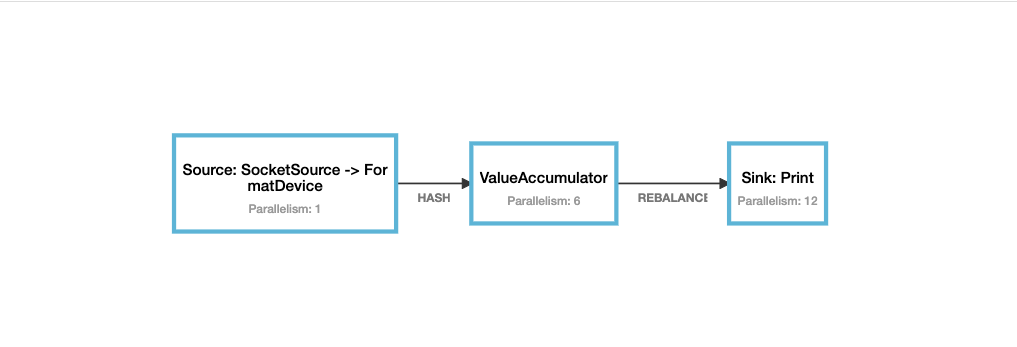
Key KeyGroup索引 并行度为12时算子索引 输入 并行度为6时的预期输出 device-1 3 0 device-1 1.0 Result(0,device-1,2.0) device-97 3 0 device-97 1.0 Result(0,device-97,2.0) device-19 14 1 device-19 1.0 Result(0,device-19,2.0) device-77 14 1 device-77 1.0 Result(0,device-77,2.0) device-5 31 2 device-5 1.0 Result(1,device-5,2.0) device-7 31 2 device-7 1.0 Result(1,device-7,2.0) device-2 35 3 device-2 1.0 Result(1,device-2,2.0) device-433 35 3 device-433 1.0 Result(1,device-433,2.0) device-27 44 4 device-27 1.0 Result(2,device-27,2.0) device-146 44 4 device-146 1.0 Result(2,device-146,2.0) device-16 62 5 device-16 1.0 Result(2,device-16,2.0) device-62 62 5 device-62 1.0 Result(2,device-62,2.0) device-37 67 6 device-37 1.0 Result(3,device-37,2.0) device-360 67 6 device-360 1.0 Result(3,device-360,2.0) device-32 85 7 device-32 1.0 Result(3,device-32,2.0) device-69 85 7 device-69 1.0 Result(3,device-69,2.0) device-17 94 8 device-17 1.0 Result(4,device-17,2.0) device-53 94 8 device-53 1.0 Result(4,device-53,2.0) device-8 102 9 device-8 1.0 Result(4,device-8,2.0) device-71 102 9 device-71 1.0 Result(4,device-71,2.0) device-12 112 10 device-12 1.0 Result(5,device-12,2.0) device-256 112 10 device-256 1.0 Result(5,device-256,2.0) device-13 120 11 device-13 1.0 Result(5,device-13,2.0) device-222 120 11 device-222 1.0 Result(5,device-222,2.0)
2 算子列表状态(ListCheckpointed)
算子列表状态在算子扩容时会对列表中的状态进行重新分配,通俗的理解就是,当算子任务并行度发生变化时会将之前的每一个子任务产生列表状态统一收集起来,然后在重新分配到更多或者更少的并行任务中。
2.1 列表状态的知识
列表状态是通过继承ListCheckpointed接口实现的作用在每个子任务实例上的算法状态。继承ListCheckpointed,需要实现两个方法restoreState和snapshotState。restoreState方法会在checkpoint恢复时被调用,Flink会将分配后的列表状态作为参数传入,用以恢复到之前检查点时的状态。snapshotState方法会在做ckeckpoint的时候被调用,需要返回当前的列表状态,用以将当前状态保存到checkpoint中。具体实现也可以参考之前的关于状态的博客:https://blog.csdn.net/shirukai/article/details/102505946
2.2 列表状态迁移示意图
列表状态的迁移相对来说比较容易理解,统一收集,重新分配。如下图为列表状态的迁移示例图,开始时,算子并行度为2,2个子任务中的列表状态里分别有3条状态。接下来并行度变为3,Flink会将之前一共6个状态收集起来重新分配到3个子任务里,实现扩容的状态迁移。接下来并行度变为1,Flink会将之前3个子任务中的所有状态收集起来,重新分配到1个子任务里,实现缩容的状态迁移。通过状态的迁移过程,也很好理解,为什么Flink要把算子状态设置为列表,就是为了在缩扩容时灵活分配。
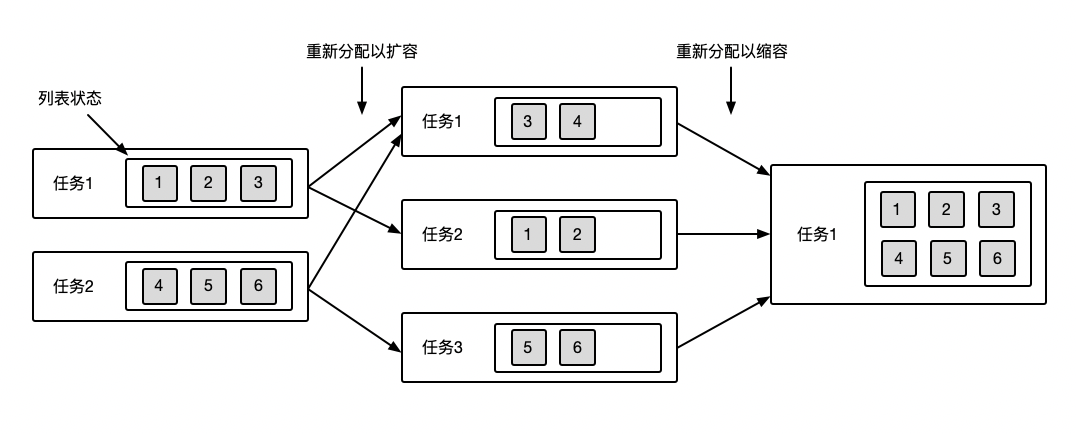
2.3 代码验证
2.3.1 验证场景及代码实现
输出数据格式为(id,value),其中id为设备id,value为设备值,使用flatmap在每个子任务中,统计value值大于指定阈值的个数,如果输出数据value值大于指定阈值,将当前子任务索引号和统计个数输出。
验证场景:
- 先将flatmap算子并行度设置为2,发送准备好的数据,输出结果符合预期
- 将flatmap算子并行度设置为3,会有2个算子基于之前的状态继续统计,另外一个算子从头统计。
代码实现:
package com.hollysys.flink.streaming.state.redistribution
import java.util
import java.util.Collections
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.checkpoint.ListCheckpointed
import org.apache.flink.streaming.api.scala.DataStream
import org.apache.flink.util.Collector
/**
* 验证列表状态,并行度改变时,状态重新分配示例
*
* @author shirukai
*/
object ListStateRedistributionExample {
case class Device(id: String, value: Double)
case class Result(taskNumber: Int, count: Long)
def main(args: Array[String]): Unit = {
// 1. 创建本地运行环境
val (env, params) = FlinkLocalEnvUtil.createLocalCheckpointEnv(args)
// 2. 从socket中获取文本
val streamText: DataStream[String] = env.socketTextStream("127.0.0.1", 9000)
.name("SocketSource")
.uid("SocketSource")
// 3. 文本转换为Device样例类
val deviceStream = streamText.map(text => {
val items = text.split(" ")
Device(items(0), items(1).toDouble)
}).setParallelism(1)
.name("FormatDevice")
.uid("FormatDevice")
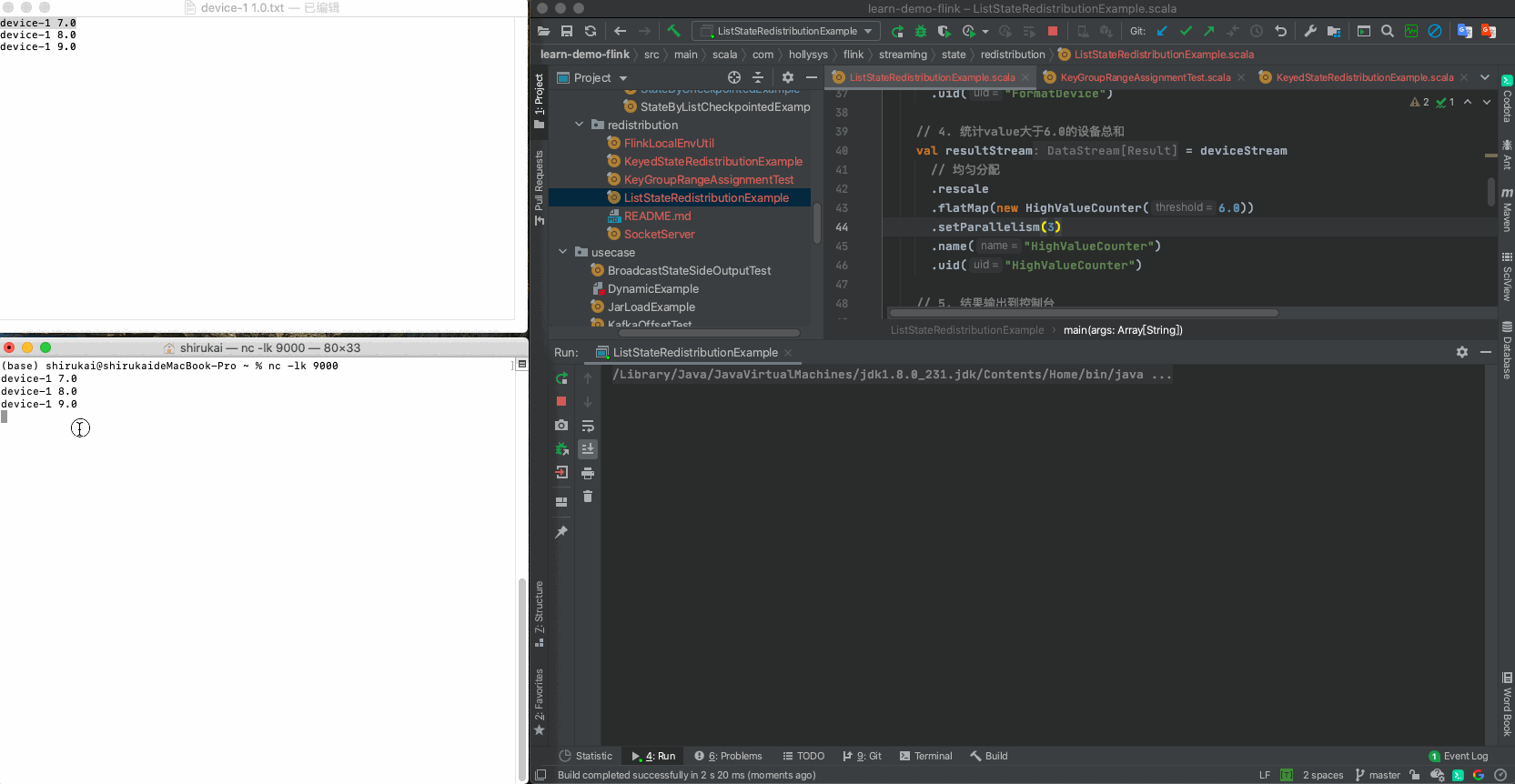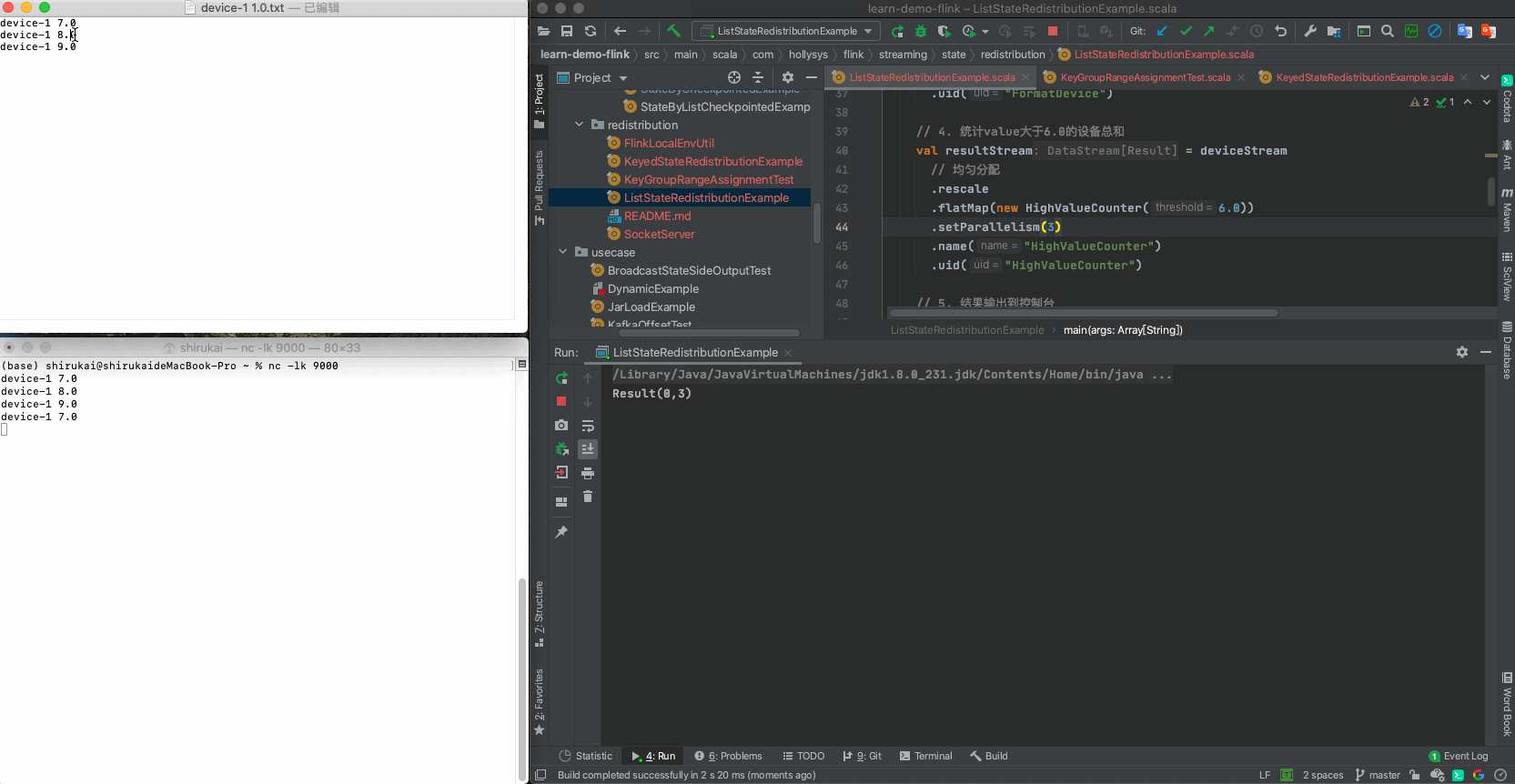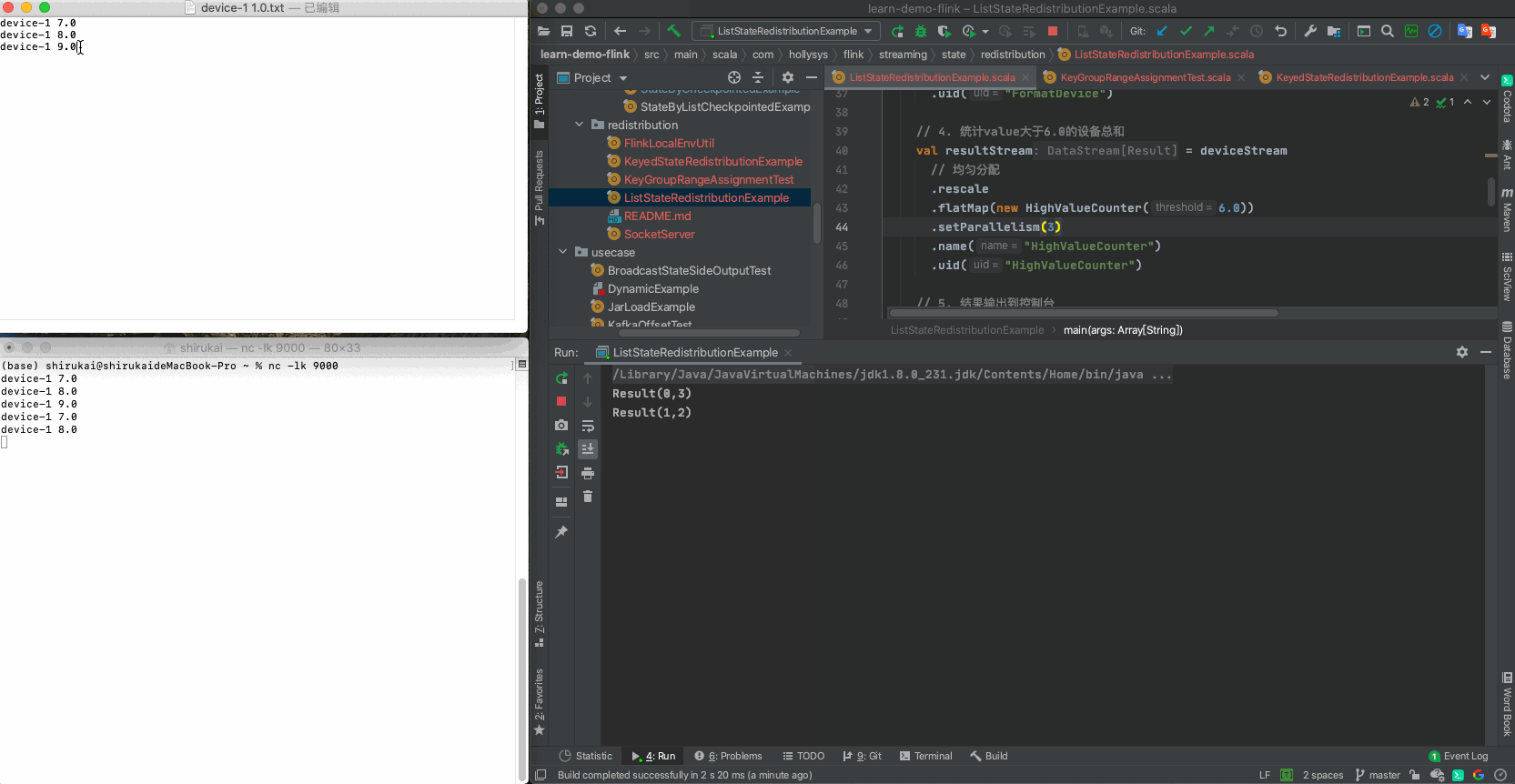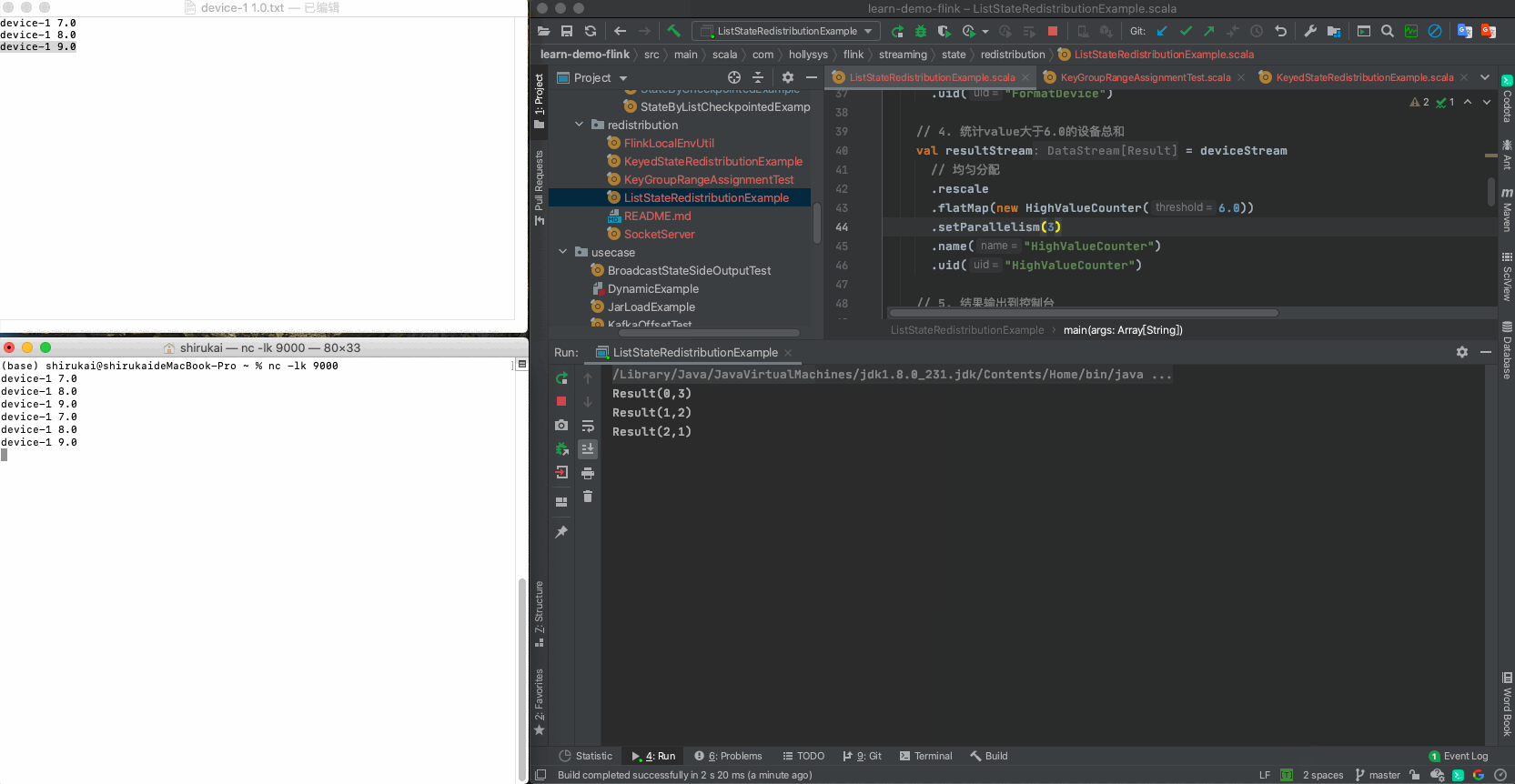
// 4. 统计value大于6.0的设备总和
val resultStream = deviceStream
// 均匀分配
.rescale
.flatMap(new HighValueCounter(6.0))
.setParallelism(2)
.name("HighValueCounter")
.uid("HighValueCounter")
// 5. 结果输出到控制台
resultStream.print()
.setParallelism(1)
.name("Print")
.uid("Print")
// 6. 提交执行
env.execute("ListStateRedistributionExample")
}
class HighValueCounter(threshold: Double) extends RichFlatMapFunction[Device, Result] with ListCheckpointed[java.lang.Long] {
// 子任务的索引号
private lazy val subTaskNumber = getRuntimeContext.getIndexOfThisSubtask
// 本地计数器变量
private var highValueCounter = 0L
override def flatMap(value: Device, out: Collector[Result]): Unit = {
if (value.value > threshold) {
// 如果超过阈值计数器加一
highValueCounter += 1
// 发出当前子任务索引和当前计数器值
out.collect(Result(subTaskNumber, highValueCounter))
}
}
/**
* 返回当前状态用以保存到快照中
*
* @param checkpointId 检查点ID
* @param timestamp 检查点时间戳
* @return
*/
override def snapshotState(checkpointId: Long, timestamp: Long): util.List[java.lang.Long] = {
Collections.singletonList(highValueCounter)
}
/**
* 恢复到之前检查点的状态
*
* @param state 检查点中的状态
*/
override def restoreState(state: util.List[java.lang.Long]): Unit = {
import scala.collection.JavaConverters._
for (cnt <- state.asScala) {
highValueCounter += cnt
}
}
}
}
2.3.2 准备数据
准备一下三条数据,用以从socket中输入
device-1 7.0
device-1 8.0
device-1 9.0
2.3.3 验证
设置flatmap的并行度为2,依次发送准备好的三条数据,输出结果与预期相同
输入 并行度为2预期输出 device-1 7.0 Result(0,1) device-1 8.0 Result(1,1) device-1 9.0 Result(0,2) 
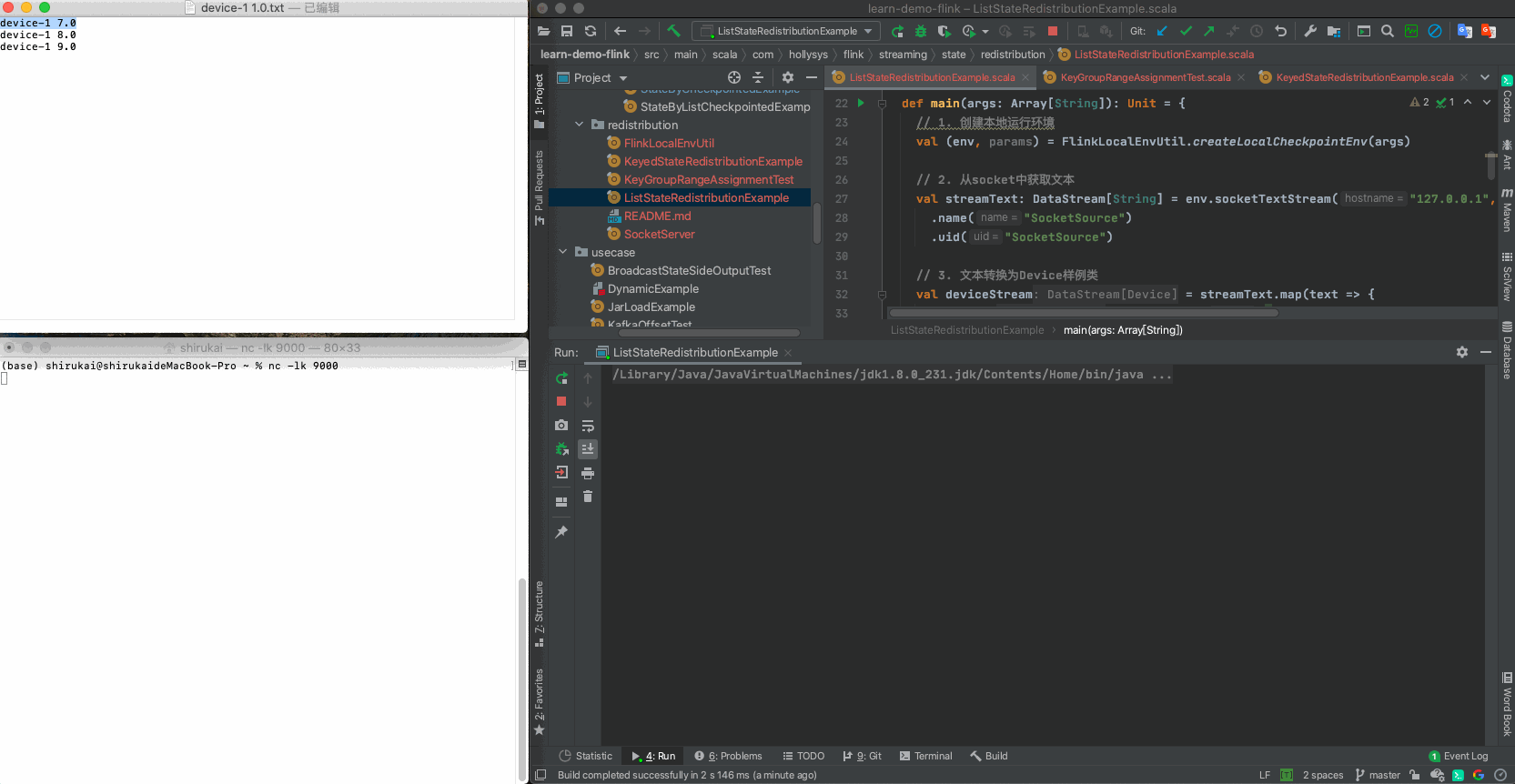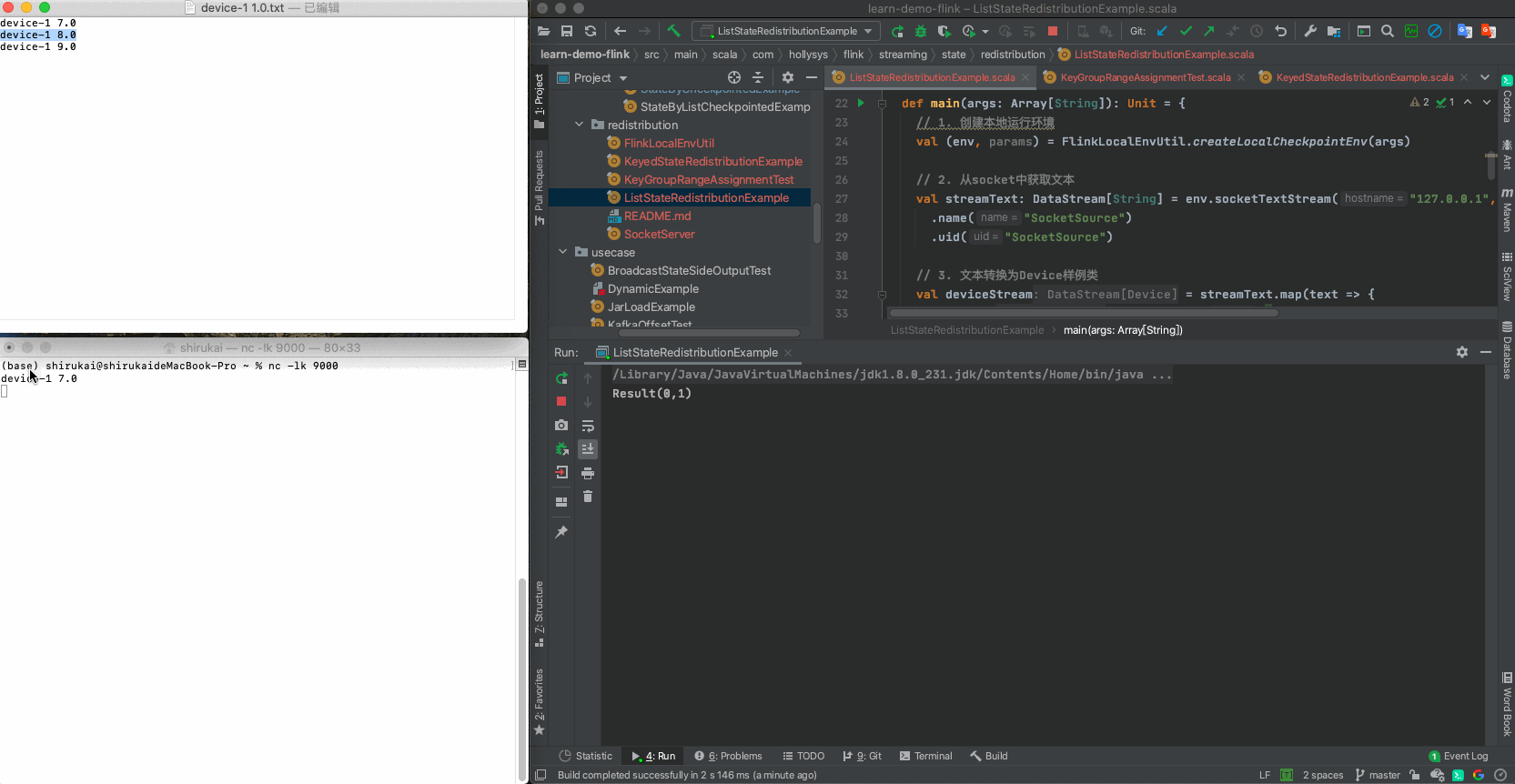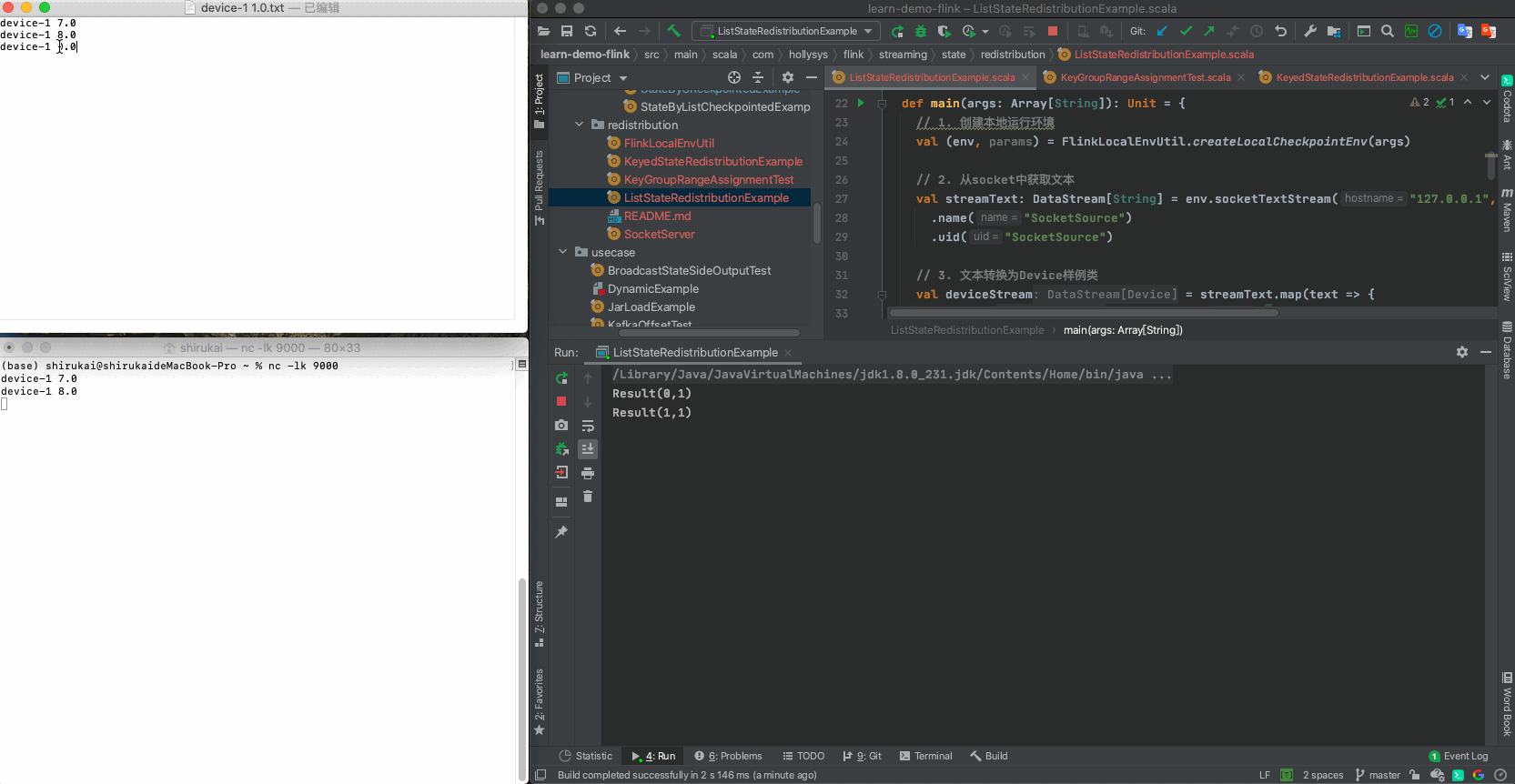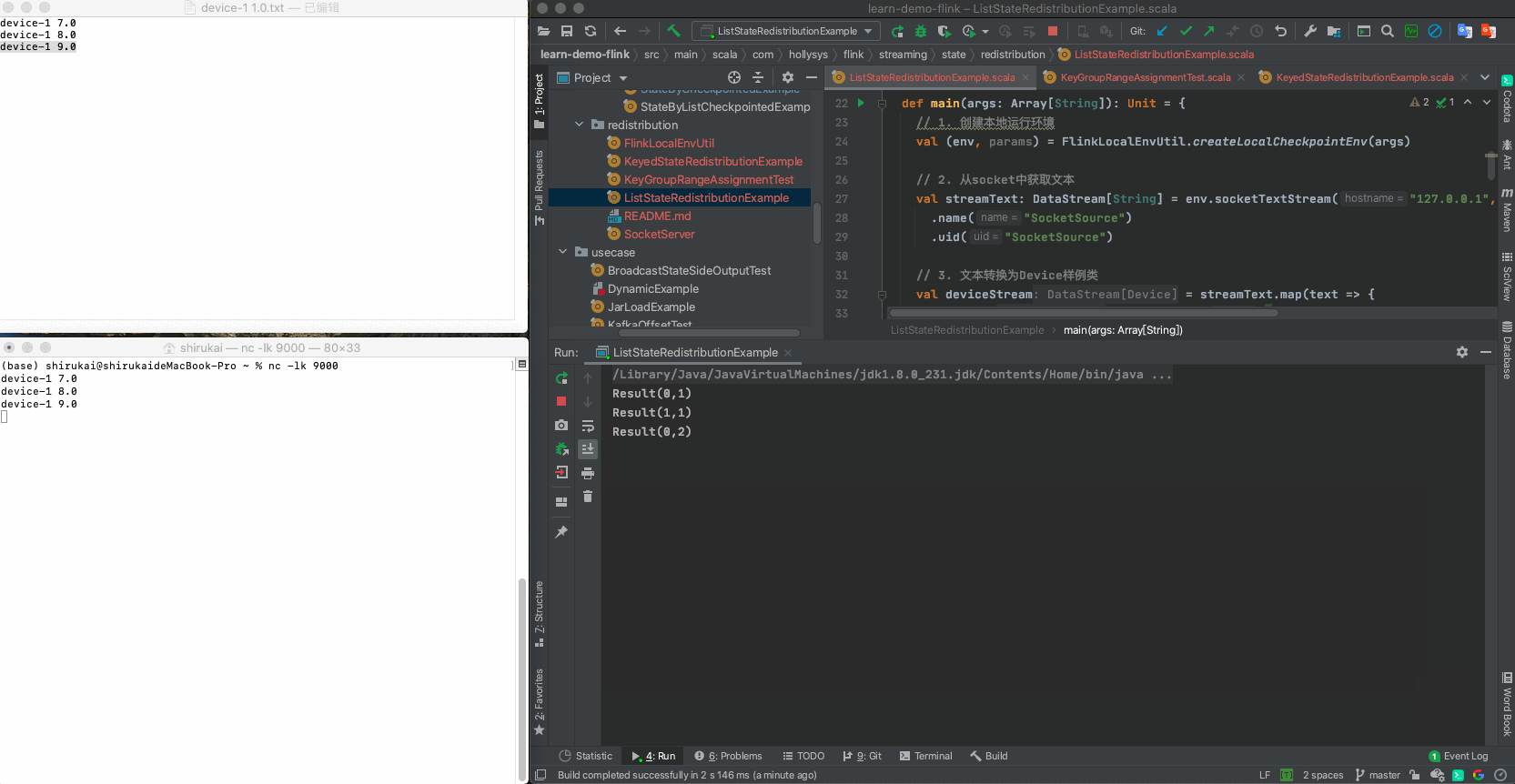
设置flatmap的并行度为2,依次发送准备好的三条数据,输出结果与预期相同
输入 并行度为3预期输出 device-1 7.0 Result(0,3) device-1 8.0 Result(1,2) device-1 9.0 Result(2,1) 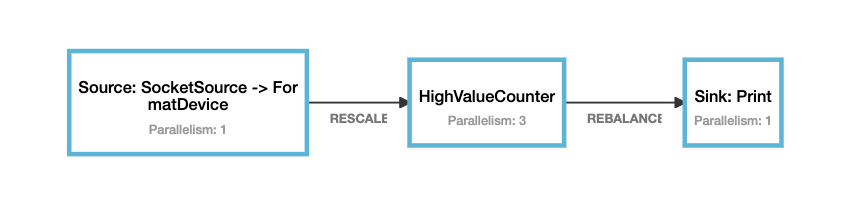
3 算子联合列表状态(CheckpointedFunction)
算子联合列表状态的算在扩缩容时会把状态列表的全部条目广播到全部的任务上。通俗的理解就是,在缩扩容时,会将之前算子所有子任务的状态都收集起来,使用广播的方式,将全量的状态列表广播给扩缩容后的每个子任务上。
3.1 算子联合列表状态
在Flink中CheckpointedFunction是指定有状态函数最底层的接口,也是唯一支持联合列表状态的接口。继承CheckpointedFunction需要实现2个方法:initializeState、snapshotState。initializeState用以初始化状态,该方法在checkpoint被恢复的时候调用,从该方法的上下文中,可以通过context.getOperatorStateStore.getUnionListState(descriptor)获取聚合状态。snapshotState方法与之前ListCheckpoint中实现的方法作用一样,做checkpoint的时候会调用。
具体实现也可以参考之前的关于状态的博客:https://blog.csdn.net/shirukai/article/details/102505946
3.2 联合列表状态迁移示意图
联合列表状态相比上面提到的联合状态,唯一的区别就是在缩扩容时,列表状态是根据任务分配状态,联合列表状态是广播全量状态。需要用户在代码中实现,哪些状态被保留,哪些状态被丢弃。如下图为联合列表状态的迁移示意图,开始时,算子并行度为2,每个人物里有两条状态,接下来并行度改为3,flink会将之前的算子状态分别广播到之后的每个算子任务中,从图中可以看出扩容后的每个任务里都会得到一个全量的状态列表,用户可以根据需求进行取舍。同理,当并行度改为1时,flink会将之前的算子状态统一广播到之后的一个子任务中得到全量的子任务。

3.3 代码验证
3.3.1 验证场景及代码实现
输出数据格式为(id,value),其中id为设备id,value为设备值,使用map在每个子任务中,将记录写入到state里,并输出状态中的所有状态。
验证场景:
- 并行度为2时,输入四条数据,每个算子中的状态会存两条记录
- 并行度改为3时,输入三条数据,每个算子汇总的状态会存5条数据,4条是之前扩容迁移后得到的全量,一条是刚刚进入的数据
代码实现:
package com.hollysys.flink.streaming.state.redistribution
import java.util
import org.apache.commons.collections.IteratorUtils
import org.apache.flink.api.common.functions.{MapFunction, RichMapFunction}
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext}
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction
import org.apache.flink.streaming.api.scala.DataStream
/**
* 验证联合列表状态,并行度改变时,状态迁移示例
*
* @author shirukai
*/
object UnionListStateRedistributionExample {
case class Device(id: String, value: Double)
case class Result(taskId: Int, devices: List[Device])
def main(args: Array[String]): Unit = {
// 1. 创建本地运行环境
val (env, params) = FlinkLocalEnvUtil.createLocalCheckpointEnv(args)
// 2. 从socket中获取文本
val streamText: DataStream[String] = env.socketTextStream("127.0.0.1", 9000)
.name("SocketSource")
.uid("SocketSource")
// 3. 文本转换为Device样例类
val deviceStream = streamText.map(text => {
val items = text.split(" ")
Device(items(0), items(1).toDouble)
}).setParallelism(1)
.name("FormatDevice")
.uid("FormatDevice")
val resultStream = deviceStream
// 均匀分配
.rescale
.map(new DeviceCollector)
.setParallelism(3)
.name("DeviceCollector")
.uid("DeviceCollector")
resultStream
.print()
.setParallelism(1)
.name("Print")
.uid("Print")
env.execute("UnionListStateRedistributionExample")
}
class DeviceCollector extends RichMapFunction[Device, Result] with CheckpointedFunction {
private var deviceCollectorState: ListState[Device] = _
private var deviceCollectorCache: util.List[Device] = _
override def map(value: Device): Result = {
deviceCollectorCache.add(value)
import scala.collection.JavaConverters._
Result(getRuntimeContext.getIndexOfThisSubtask, deviceCollectorCache.asScala.toList)
}
/**
* 当检查点被请求快照时调用,用以保存当前状态
*
* @param context ct
*/
override def snapshotState(context: FunctionSnapshotContext): Unit = {
// 清空之前的状态
deviceCollectorState.clear()
// 将缓存刷到状态里
deviceCollectorState.addAll(deviceCollectorCache)
}
/**
* 当并行实例被创建时调用,用以初始化状态
*
* @param context ct
*/
override def initializeState(context: FunctionInitializationContext): Unit = {
val deviceCollectorStateDesc = new ListStateDescriptor[Device]("device-collector-state", classOf[Device])
deviceCollectorState = context.getOperatorStateStore.getUnionListState(deviceCollectorStateDesc)
if (context.isRestored) {
// 将状态刷到缓存里
deviceCollectorCache = IteratorUtils.toList(deviceCollectorState.get().iterator()).asInstanceOf[util.List[Device]]
}else{
deviceCollectorCache = new util.ArrayList[Device]()
}
}
}
}
3.3.2 准备数据
准备以下三条数据,用以从socket中输入
device-1 7.0
device-1 8.0
device-1 9.0
device-1 10.0
device-1 11.0
device-1 12.0
device-1 13.0
3.3.3 验证
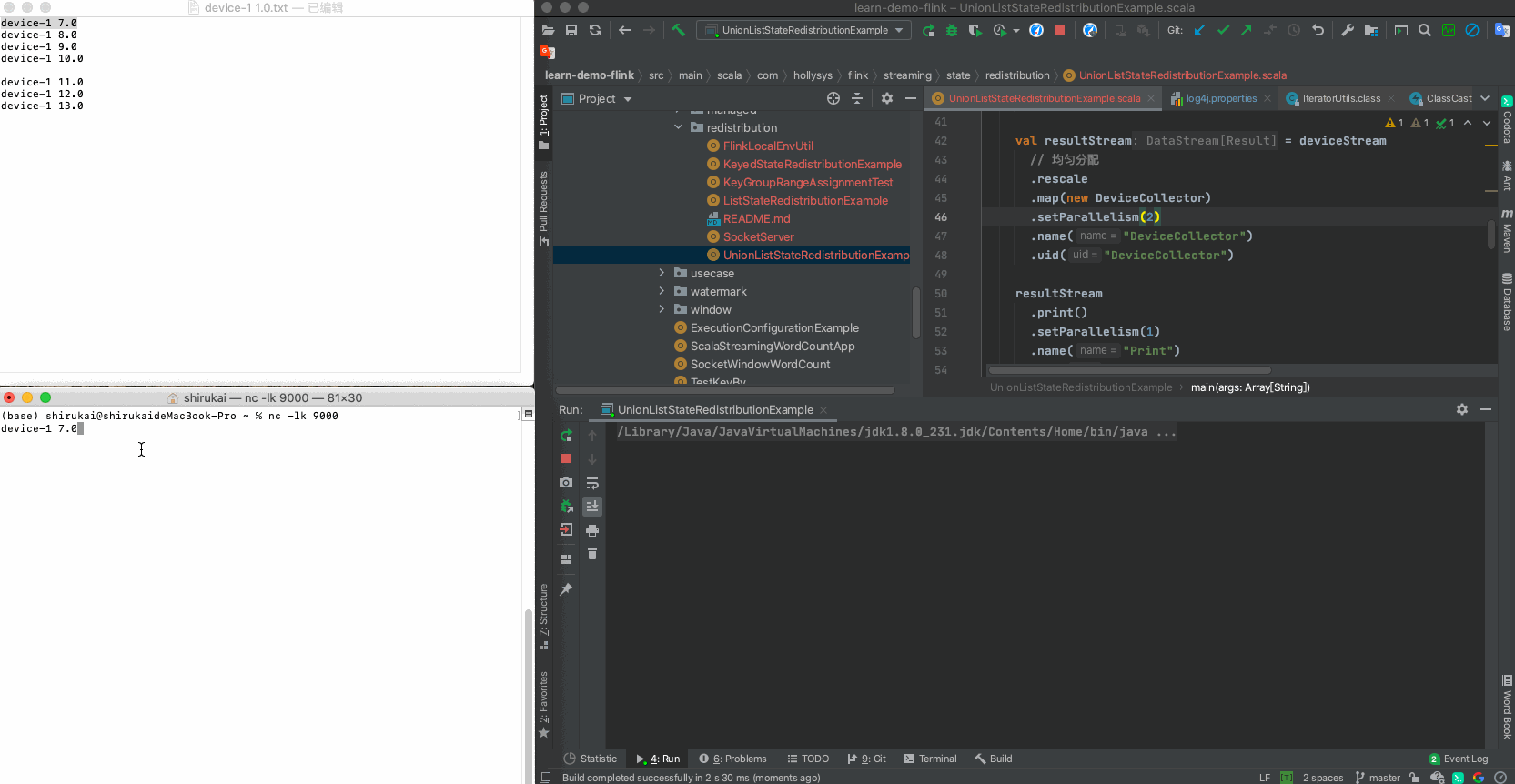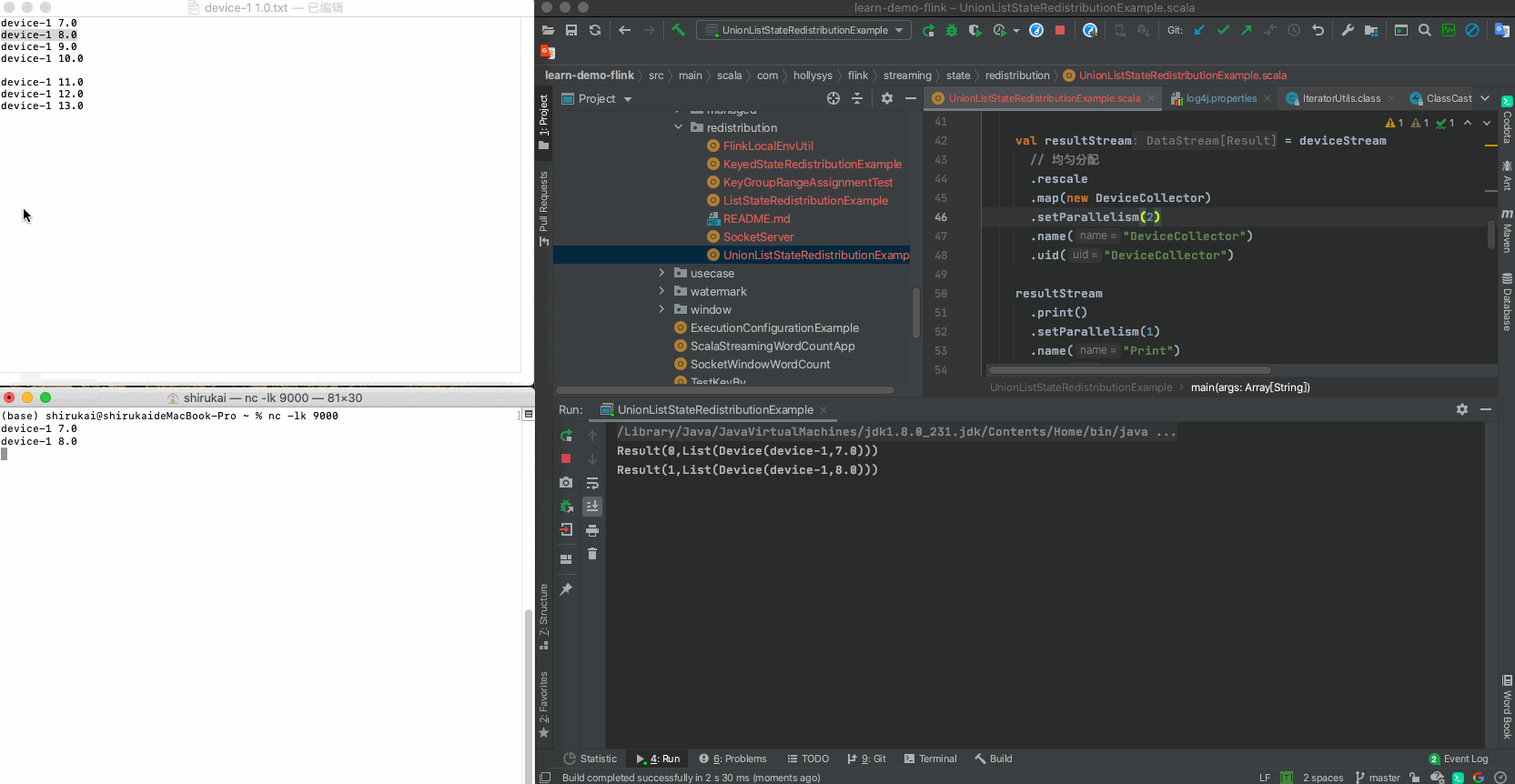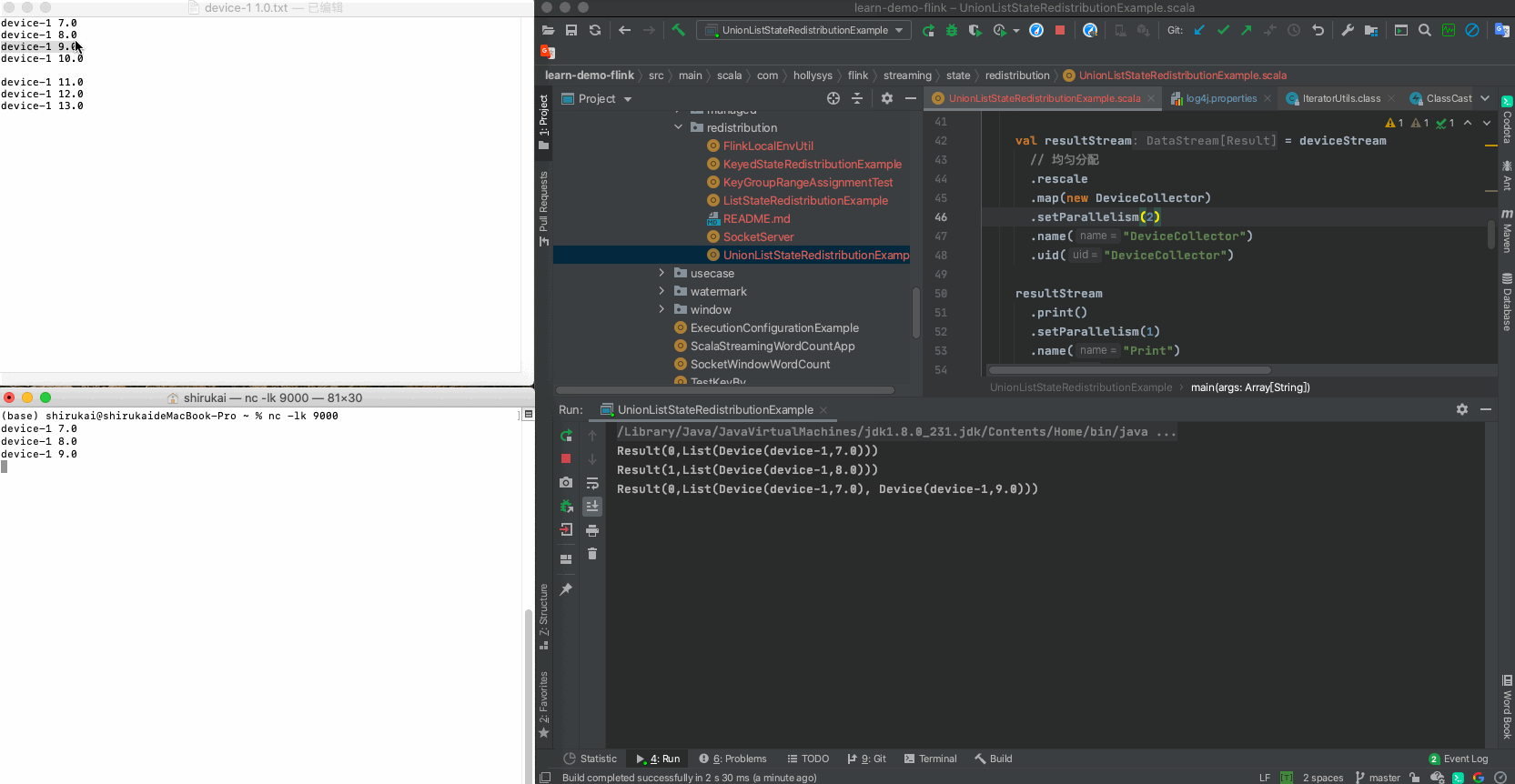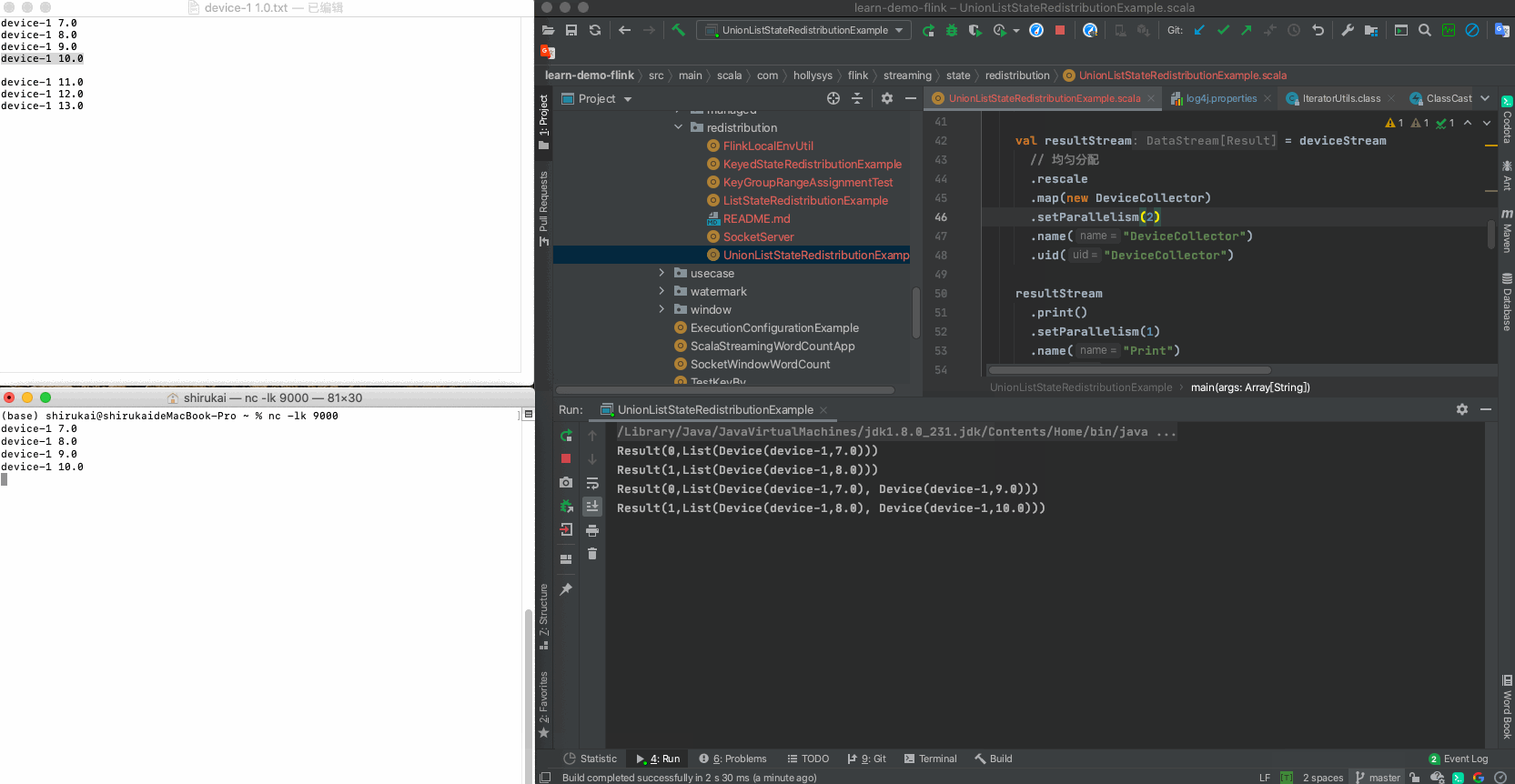
设置map算子的并行度为2,输入下列数据,输出结果与预期相同
a 修改并行度
val resultStream = deviceStream // 均匀分配 .rescale .map(new DeviceCollector) .setParallelism(2) .name("DeviceCollector") .uid("DeviceCollector")b 数据
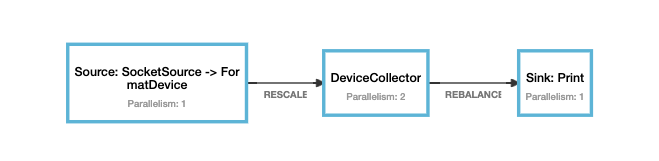
输入 并行度为2预期输出 device-1 7.0 Result(0,List(Device(device-1,7.0))) device-1 8.0 Result(1,List(Device(device-1,8.0))) device-1 9.0 Result(0,List(Device(device-1,7.0), Device(device-1,9.0))) device-1 10.0 Result(1,List(Device(device-1,8.0), Device(device-1,10.0))) c 拓扑图
d 运行示例
设置map算子的并行度为3,输入下列数据,输出结果与预期相同
a 修改并行度
val resultStream = deviceStream // 均匀分配 .rescale .map(new DeviceCollector) .setParallelism(3) .name("DeviceCollector") .uid("DeviceCollector")b 数据
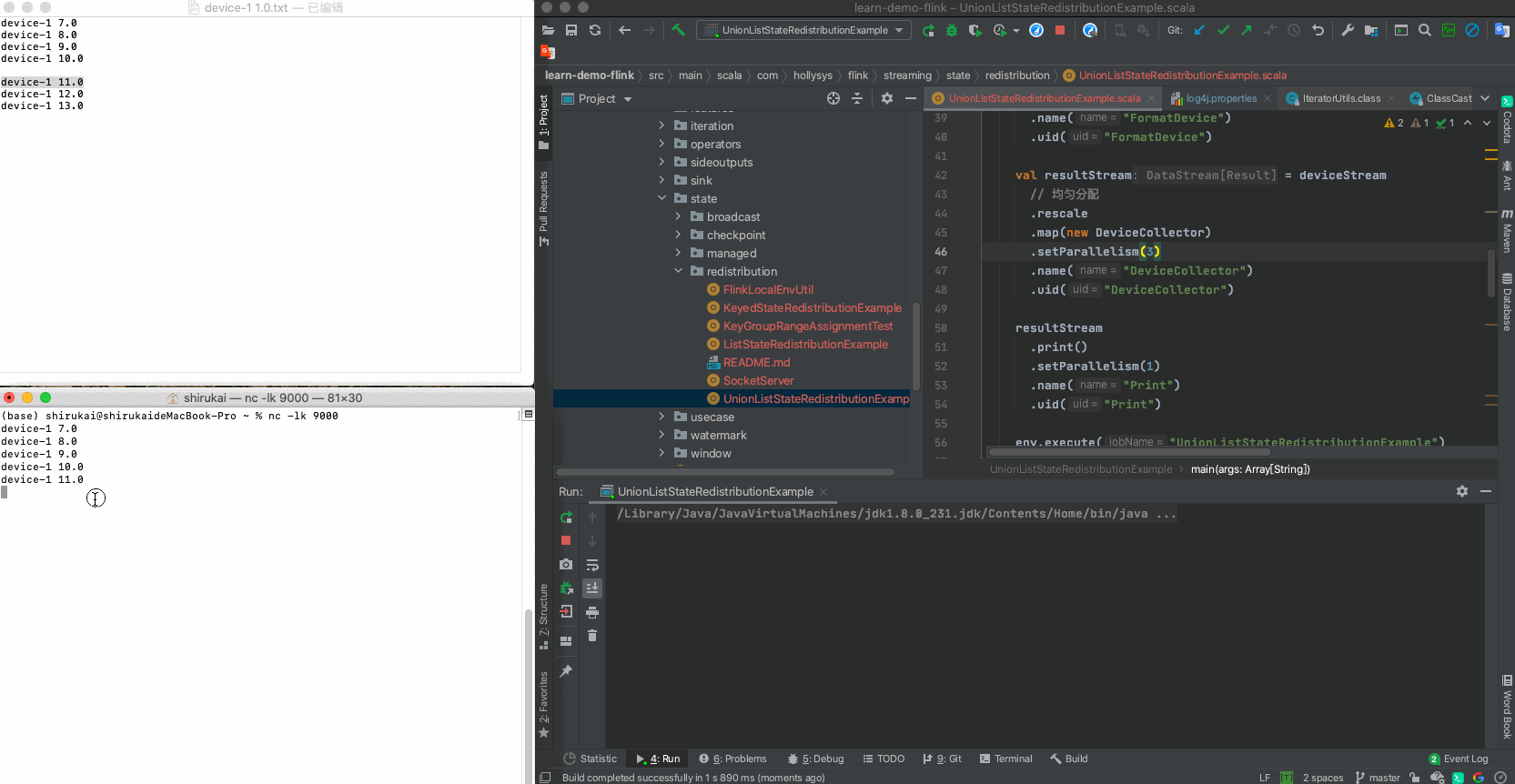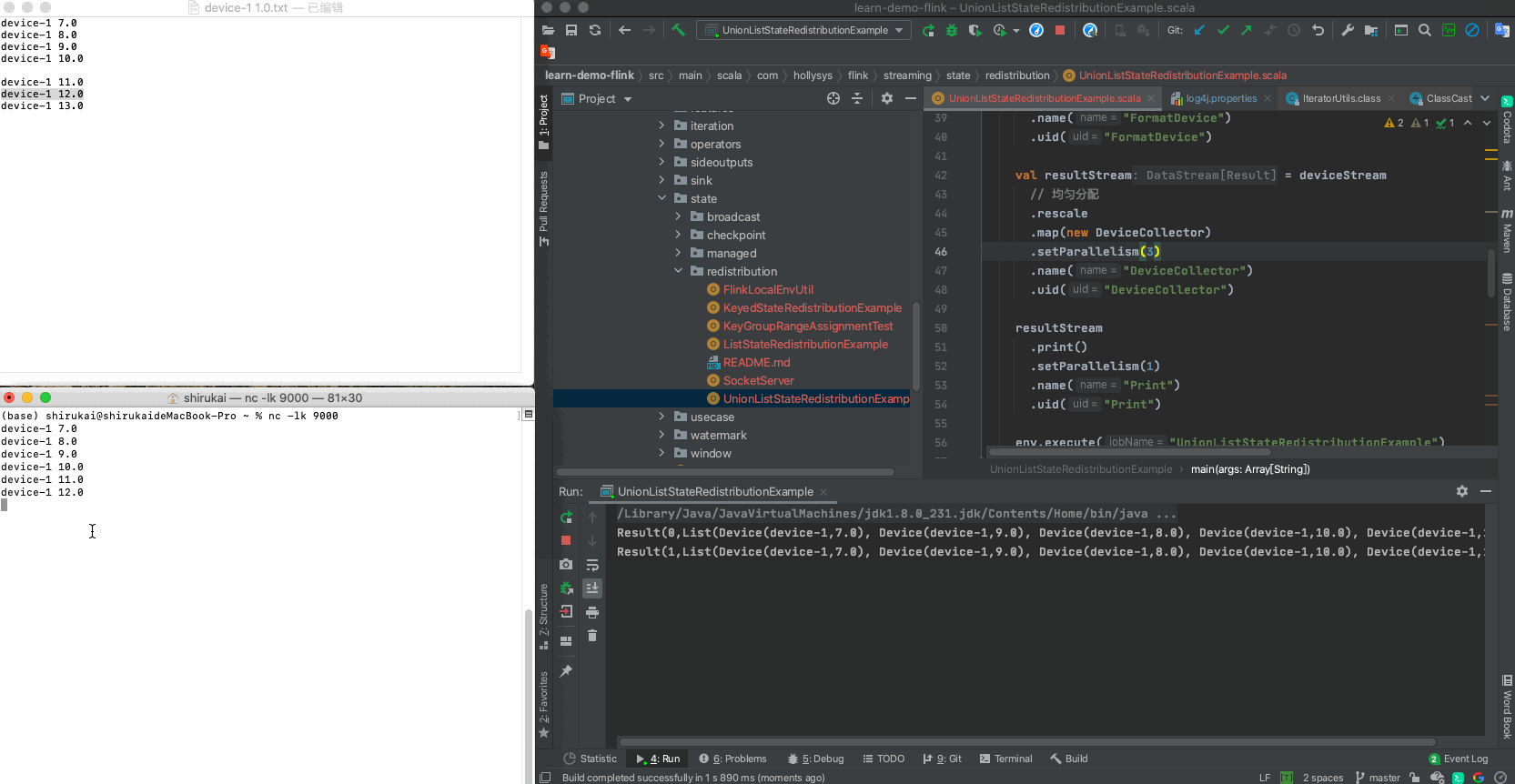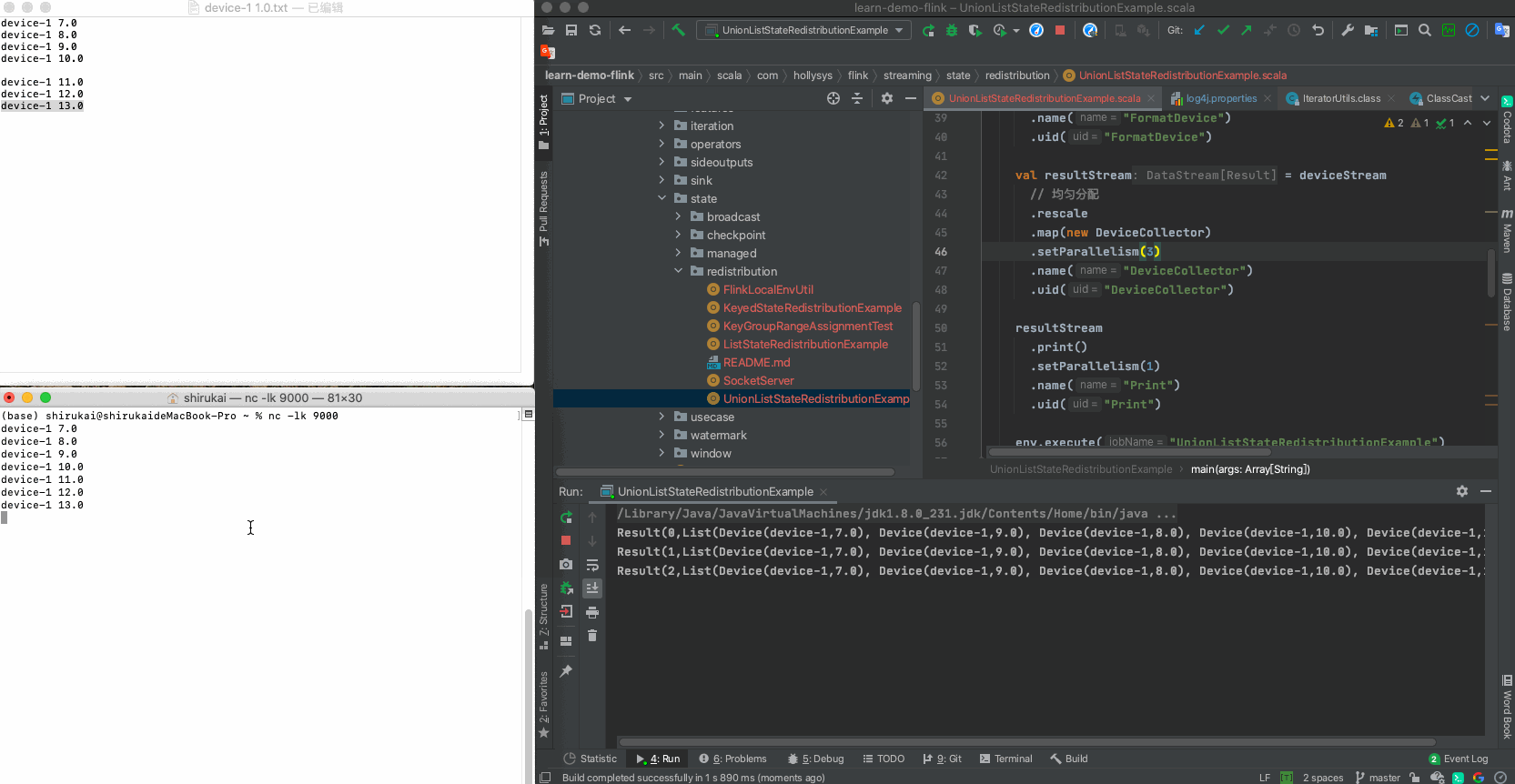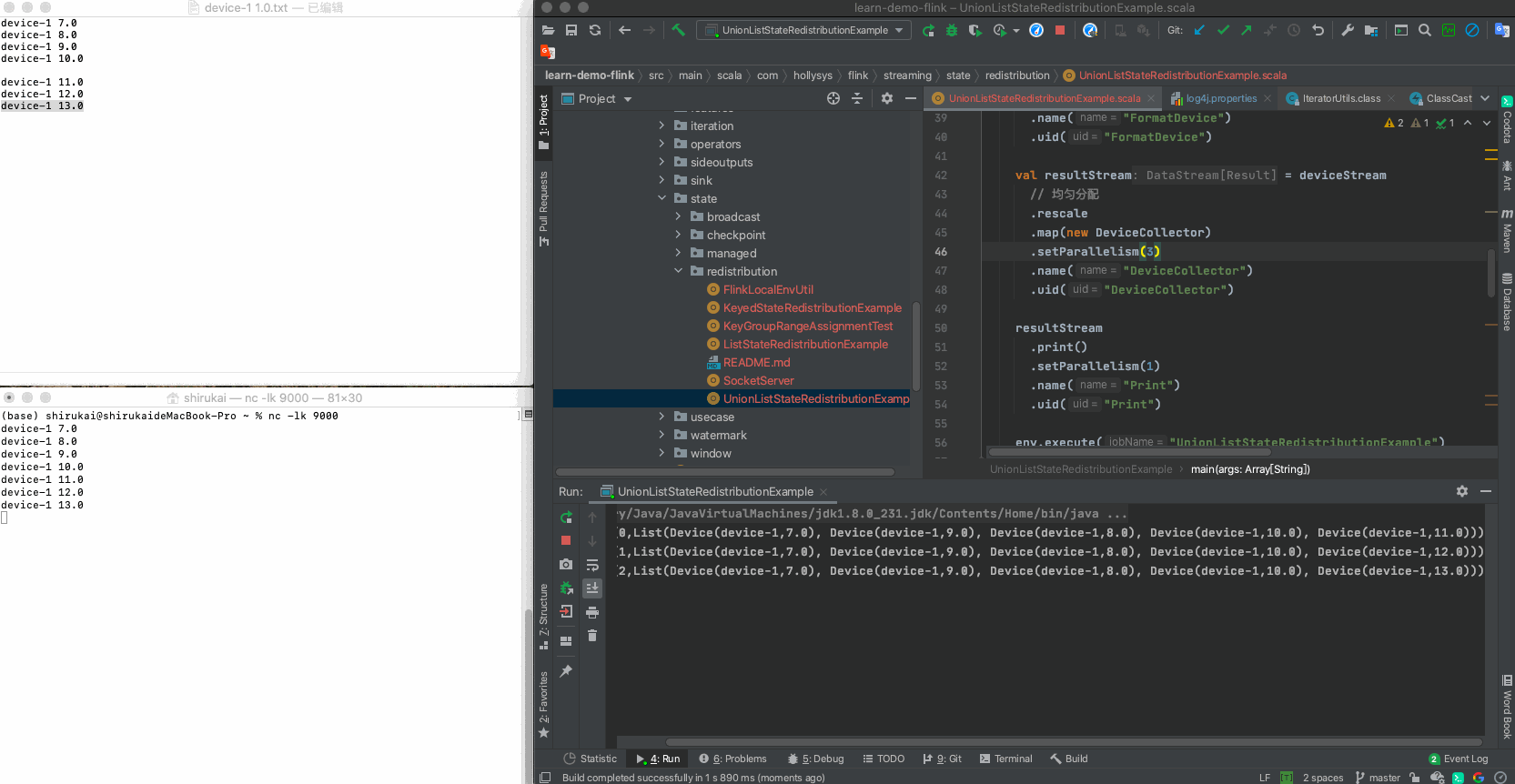
输入 并行度为3预期输出 device-1 11.0 Result(0,List(Device(device-1,7.0), Device(device-1,9.0), Device(device-1,8.0), Device(device-1,10.0), Device(device-1,11.0))) device-1 12.0 Result(1,List(Device(device-1,7.0), Device(device-1,9.0), Device(device-1,8.0), Device(device-1,10.0), Device(device-1,12.0))) device-1 13.0 Result(2,List(Device(device-1,7.0), Device(device-1,9.0), Device(device-1,8.0), Device(device-1,10.0), Device(device-1,13.0))) c 拓扑图
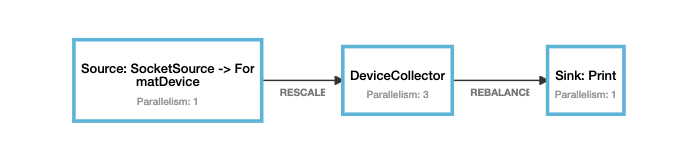
d 运行示例
4 广播状态
Flink里还有一种状态叫做广播状态,广播状态需要与广播流一起使用,该状态在扩容时,会以拷贝的形式,将之前子任务中的状态拷贝到新的任务中,在缩容时,拷贝对应的子任务状态即可。
4.1 广播状态的知识
上面说过,广播状态是需要与广播流一起使用的,广播流在配置动态更新、规则更新等场景应用的比较多。所谓广播流就是将上游算子的一条记录,通过广播的方式,下发给下游的每一个算子。声明一个广播流需要通过DataStream的broadcast方法,传入一个MapStateDescriptor对象。普通流需要通过connect方法与广播流进行连接,随后调用process方法,传入一个自定义的广播流处理算子。该算子需要继承BroadcastProcessFunction(如果前面是KeyedStream则需要继承KeyedBroadcastProcessFunction),并实现processElement和processBroadcastElement方法。
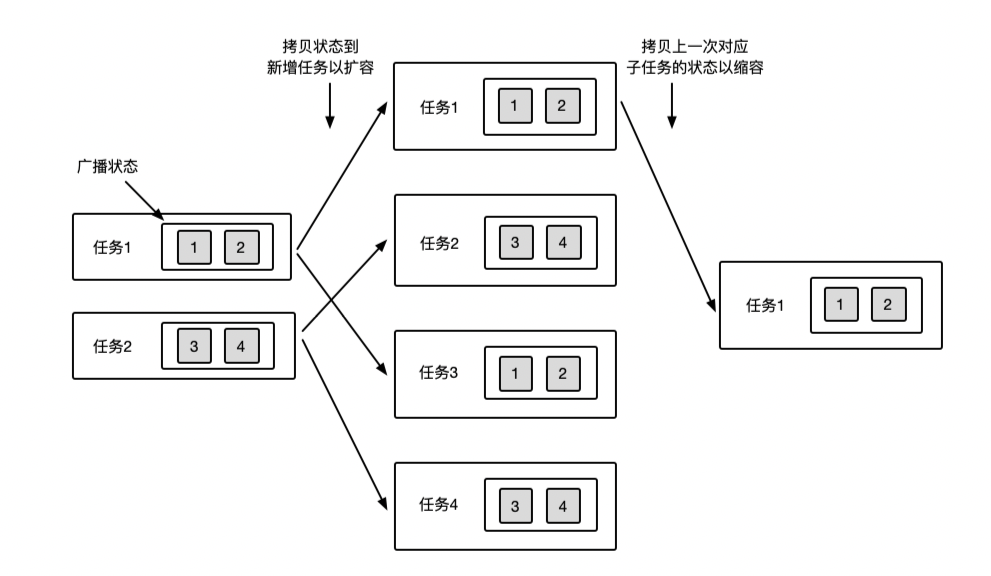
4.2 广播状态迁移示意图
广播状态的迁移是通过拷贝的方式进行的,在扩容时它会拷贝之前子任务中的状态来填充新增的子任务,在缩容时它会拷贝对应的子任务到当前子任务中。如下图所示为广播状态迁移的示意图,开始时并行度为2,当并行度变为4时,flink会将1,2子任务的状态,拷贝到新增的3、4任务中,同理,当并行度改为1时,会拷贝对应的子任务状态,到当前任务。
4.3 代码验证
4.3.1 验证场景及代码实现
输出数据格式为(id,value),其中id为设备id,value为设备值,广播流输入格式为(id,rule),其中id为规则id,rule为规则内容。将广播流与正常流进行连接,使用process在每个子任务中,将设备与规则列表绑定后发到下游算子。
验证场景:
- 先将process算子并行度设置为2,发送准备好的数据,输出结果符合预期
- 将process算子并行度设置为4,发送准备的数据,新增的3、4任务会分别拷贝原来1、2的状态,输出结果符合预期
代码实现:
package com.hollysys.flink.streaming.state.redistribution
import org.apache.flink.api.common.state.MapStateDescriptor
import org.apache.flink.streaming.api.scala.DataStream
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction
import org.apache.flink.util.Collector
/**
* 验证广播状态,并行度改变时,状态迁移示例
*
* @author shirukai
*/
object BroadcastStateRedistributionExample {
case class Device(id: String, value: Double)
case class Rule(id: String, rule: String, var taskId: Int)
case class Result(taskId: Int, device: Device, rules: List[Rule])
private val stateDescriptor = new MapStateDescriptor("rule-state",
createTypeInformation[String],
createTypeInformation[Rule])
def main(args: Array[String]): Unit = {
// 1. 创建本地运行环境
val (env, params) = FlinkLocalEnvUtil.createLocalCheckpointEnv(args)
// 2. 从socket中获取文本
val deviceStreamText: DataStream[String] = env.socketTextStream("127.0.0.1", 9000)
.name("DeviceSocketSource")
.uid("DeviceSocketSource")
val ruleStreamText: DataStream[String] = env.socketTextStream("127.0.0.1", 9001)
.name("RuleSocketSource")
.uid("RuleSocketSource")
// 3. 文本转换为样例类
val deviceStream = deviceStreamText.map(text => {
val items = text.split(" ")
Device(items(0), items(1).toDouble)
}).setParallelism(1)
.name("FormatDevice")
.uid("FormatDevice")
val ruleStream = ruleStreamText.map(text => {
val items = text.split(" ")
Rule(items(0), items(1), -1)
}).setParallelism(1)
.name("FormatRule")
.uid("FormatRule")
val broadcastStream = ruleStream.broadcast(stateDescriptor)
// 4. 绑定规则
val resultStream = deviceStream
.rescale
.connect(broadcastStream)
.process(new RuleBinding)
.setParallelism(2)
.name("RuleBinding")
.uid("RuleBinding")
resultStream
.print()
.setParallelism(1)
.name("Print")
.uid("Print")
env.execute("BroadcastStateRedistributionExample")
}
class RuleBinding extends BroadcastProcessFunction[Device, Rule, Result] {
override def processElement(value: Device,
ctx: BroadcastProcessFunction[Device, Rule, Result]#ReadOnlyContext,
out: Collector[Result]): Unit = {
val state = ctx.getBroadcastState(stateDescriptor)
import scala.collection.JavaConverters._
val taskId = getRuntimeContext.getIndexOfThisSubtask
val result = Result(taskId, value, state.immutableEntries().asScala.map(_.getValue).toList)
out.collect(result)
}
override def processBroadcastElement(value: Rule,
ctx: BroadcastProcessFunction[Device, Rule, Result]#Context,
out: Collector[Result]): Unit = {
val state = ctx.getBroadcastState(stateDescriptor)
value.taskId = getRuntimeContext.getIndexOfThisSubtask
state.put(value.id, value)
}
}
}
3.3.2 准备数据
准备以下数据,用以从socket中输入
# 设备流
device-1 8.0
# 规则流
id-1 rule-1
3.3.3 验证
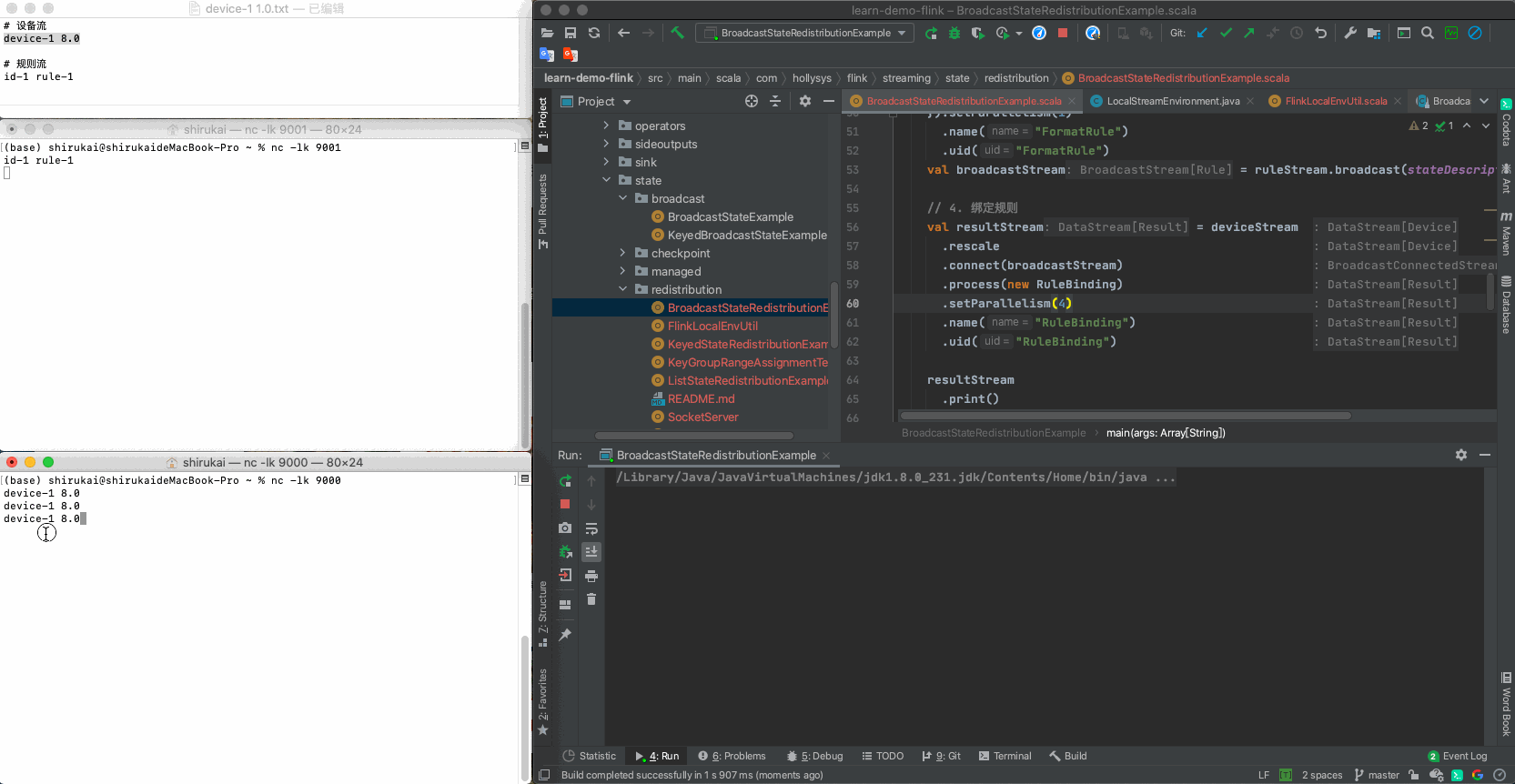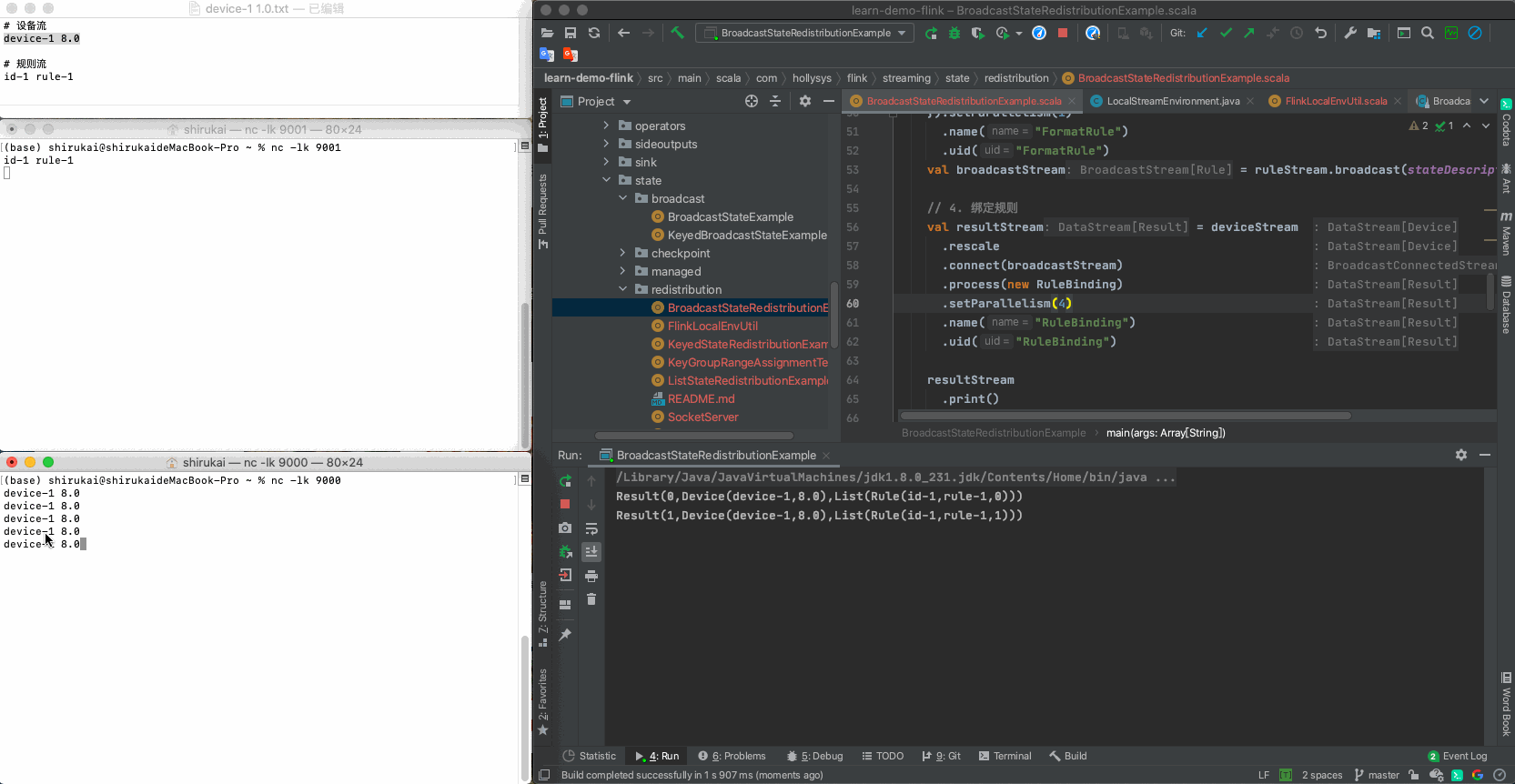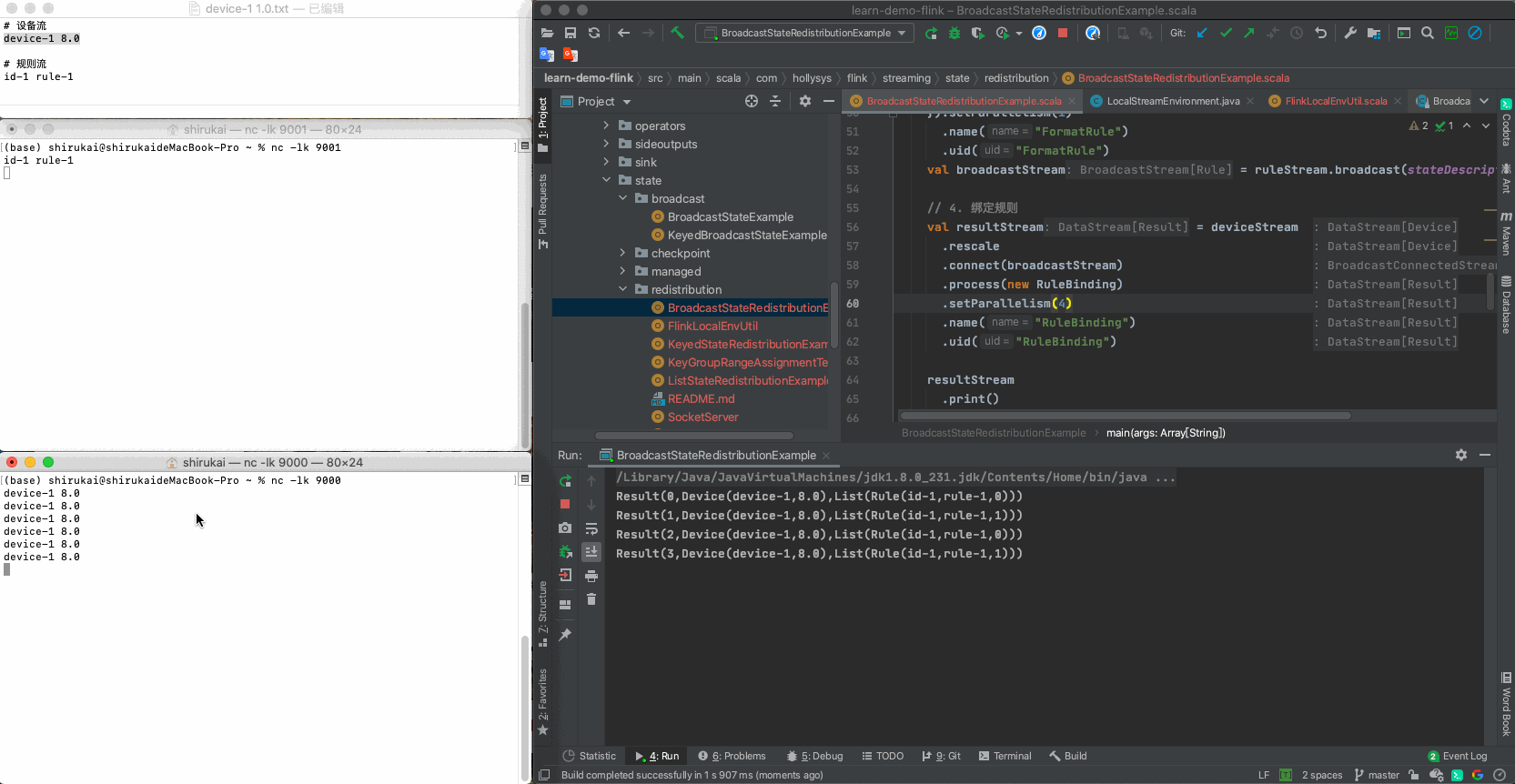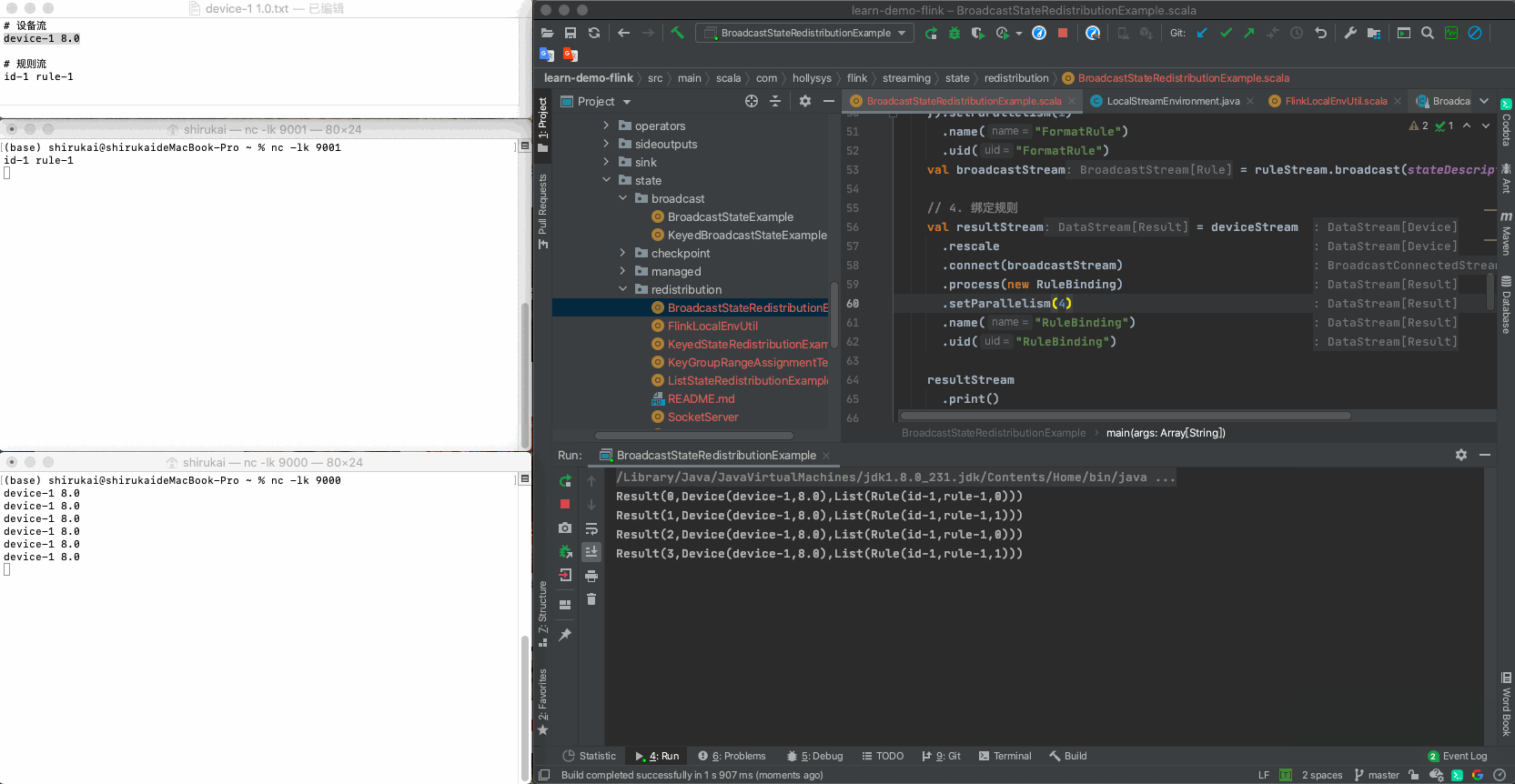
设置process算子的并行度为2,输入下列数据,输出结果与预期相同
a 修改并行度
val resultStream = deviceStream .rescale .connect(broadcastStream) .process(new RuleBinding) .setParallelism(2) .name("RuleBinding") .uid("RuleBinding")b 数据
首先在规则socket中输入数据
id-1 rule-1然后在设备socket中输入如下数据
输入 并行度为2预期输出 device-1 8.0 Result(0,Device(device-1,8.0),List(Rule(id-1,rule-1,0))) device-1 8.0 Result(1,Device(device-1,8.0),List(Rule(id-1,rule-1,1))) c 拓扑图
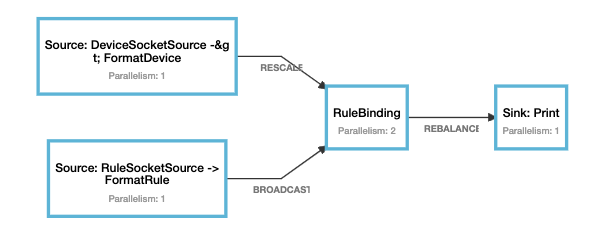
d 运行示例

设置process算子的并行度为3,输入下列数据,输出结果与预期相同
a 修改并行度
val resultStream = deviceStream .rescale .connect(broadcastStream) .process(new RuleBinding) .setParallelism(4) .name("RuleBinding") .uid("RuleBinding")b 数据
输入 并行度为3预期输出 device-1 8.0 Result(0,Device(device-1,8.0),List(Rule(id-1,rule-1,0))) device-1 8.0 Result(1,Device(device-1,8.0),List(Rule(id-1,rule-1,1))) device-1 8.0 Result(2,Device(device-1,8.0),List(Rule(id-1,rule-1,0))) device-1 8.0 Result(3,Device(device-1,8.0),List(Rule(id-1,rule-1,1))) c 拓扑图
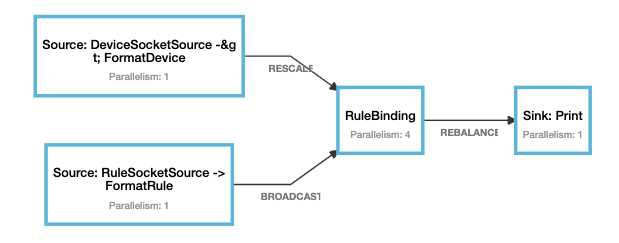
d 运行示例