版本说明:Spark 2.4
1 前言
在使用StructuredStreaming的时候,我们可能会遇到在不重启Spark应用的情况下动态的更新参数,如:动态更新某个过滤条件、动态更新分区数量、动态更新join的静态数据等。在工作中,遇到了一个应用场景,是实时数据与静态DataFrame去Join,然后做一些处理,但是这个静态DataFrame偶尔会发生变化,要求在不重启Spark应用的前提下去动态更新。目前总结了两种解决方案,一种是基于重写数据源的动态更新,另一种是重启Query的动态更新,下面将分别介绍下两种方案的实现。
2 基于重写数据源的动态更新
2.1 应用场景
此方案仅适用于实时数据与离线数据(数据量不大)join,但离线数据会发生更新的情况。
2.2 实现思路
此方案的实现思路是在Spark读取实时数据的同时,检查离线数据是否更新,如果发生更新,将更新数据写入实时数据的RDD,然后生成DataFrame。如果没发生更新从缓存中取离线数据写入实时数据的RDD,然后生成DataFrame。
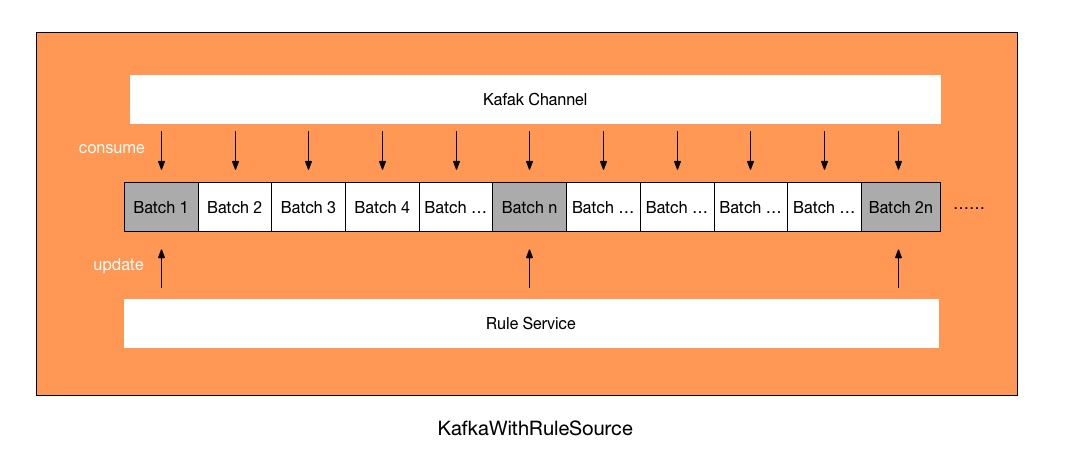
2.3 Demo演示
这里以Kafka实时数据、REST请求离线数据为例进行动态更新演示。
2.3.1 数据描述
Kafka数据格式
[
{
"namespace": "000003",
"internalSeriesId": "hiacloud0003000094L[]",
"regions": 10,
"v": "F#100.90",
"s": 0,
"t": 1550193281708,
"gatewayId": "hiacloud",
"pointId": "000003F"
}
]
REST离线数据格式
{
"code": 0,
"msg": "操作成功",
"data": [
{
"instanceId": "1",
"instanceParams": "[{\"label\":\"上限值\",\"name\":\"upperbound\",\"value\":\"100.823\"},{\"label\":\"下限值\",\"name\":\"lowerbound\",\"value\":\"50.534\"}]",
"pointId": [
"hiacloud/000000F",
"hiacloud/000002F",
"hiacloud/000001F"
]
}
]
}
最终生成DataFrame格式
+---------+------+---+-----------------------+---------+-------+----------+----------+
|namespace|v |s |t |gatewayId|pointId|lowerbound|upperbound|
+---------+------+---+-----------------------+---------+-------+----------+----------+
|000000 |108.79|0 |2019-02-15 09:34:19.985|hiacloud |000000F|50.534 |100.823 |
|000001 |108.79|0 |2019-02-15 09:34:19.985|hiacloud |000001F|50.534 |100.823 |
|000002 |108.79|0 |2019-02-15 09:34:19.985|hiacloud |000002F|50.534 |100.823 |
|000003 |108.78|0 |2019-02-15 09:34:18.856|hiacloud |000003F| | |
|000003 |108.79|0 |2019-02-15 09:34:19.985|hiacloud |000003F| | |
+---------+------+---+-----------------------+---------+-------+----------+----------+
2.3.2 自定义KafkaSource
为了实现上述效果,我们需要自定义KafkaSource,关于如何重写数据源可以参考《StructuredStreaming内置数据源及自定义数据源》,这里我们大体分三步来实现:
第一步:创建Kafka RDD处理类
第二步:重写Source
第三步:重写Provider
2.3.2.1 创建KafkaRDD处理类:KafkaRDDHandler
该类主要是用来处理Spark读取Kafka数据之后生成的RDD,把我们读到静态数据加载到这个RDD中,重新返回新的RDD,因为涉及到数据的加载,所以这个地方还要根据我们传入的参数动态生成schema,也就是Kafka数据与静态数据合并之后的schema。
schema的生成:
原本spark读取kafka数据生成的schema是如下格式的:
// 源码位置:org.apache.spark.sql.kafka010.KafkaOffsetReader
def kafkaSchema: StructType = StructType(Seq(
StructField("key", BinaryType),
StructField("value", BinaryType),
StructField("topic", StringType),
StructField("partition", IntegerType),
StructField("offset", LongType),
StructField("timestamp", TimestampType),
StructField("timestampType", IntegerType)
))
既然我们要将参数数据写进DataFrame,相应的就需要修改schema,这里我们动态重写value列,将schema拆成两部分,一个是kafka基本信息部分(除了value列,所有的列:key、topic、partition、offset、timestamp、timestampType),另一个是value列,这里value列就不是BinaryType类型了,而是一个嵌套类型。嵌套类型的schema是根据kafka里的json数据以及rest请求到的json数据动态生成的。
val kafkaSchema: List[StructField] = List[StructField](
StructField("key", BinaryType),
StructField("topic", StringType),
StructField("partition", IntegerType),
StructField("offset", LongType),
StructField("timestamp", TimestampType),
StructField("timestampType", IntegerType)
)
val valueSchema: List[StructField] = List[StructField](
StructField("namespace", StringType),
StructField("v", DoubleType),
StructField("s", IntegerType),
StructField("t", TimestampType),
StructField("gatewayId", StringType),
StructField("pointId", StringType)
)
val DC_CLEANING_RULE_PREFIX = "dc.cleaning.rule."
val DC_CLEANING_RULE_COLUMN = "column."
val SCHEMA_VALUE_NAME = "value"
def getDCParameters(parameters: Map[String, String]): Map[String, String] = parameters
.filter(_._1.startsWith(DC_CLEANING_RULE_PREFIX))
.map(parameter => (parameter._1.stripPrefix(DC_CLEANING_RULE_PREFIX), parameter._2))
def getColumnParameters(dcParameters: Map[String, String]): Map[String, String] = dcParameters
.filter(_._1.contains(DC_CLEANING_RULE_COLUMN))
.map(parameter => (parameter._1.stripPrefix(DC_CLEANING_RULE_COLUMN), parameter._2))
def schema(parameters: Map[String, String]): StructType = {
val dcParams = getDCParameters(parameters)
generateSchema(getColumnParameters(dcParams))
}
def generateSchema(columnParameters: Map[String, String]): StructType = {
val newValueSchema = valueSchema ::: columnParameters.map(p => StructField(p._1, StringType)).toList
StructType(kafkaSchema :+ StructField(SCHEMA_VALUE_NAME, StructType(newValueSchema)))
}
如上代码所示最终schema是由kafkaSchema和valueSchema嵌套生成的,测试如下:
val params = Map[String,String]("dc.cleaning.rule.column.test"->"test")
schema(params).printTreeString()
/*
root
|-- key: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
|-- value: struct (nullable = true)
| |-- namespace: string (nullable = true)
| |-- v: double (nullable = true)
| |-- s: integer (nullable = true)
| |-- t: timestamp (nullable = true)
| |-- gatewayId: string (nullable = true)
| |-- pointId: string (nullable = true)
| |-- test: string (nullable = true)
*/
REST获取数据
通过http请求获取数据,并将数据展开为k,v格式,如下所示:
/**
* 请求规则
*
* @param api 请求地址
* @param retry 重试次数
* @return Map[pointId,instanceParams]
*/
def requestRules(api: String, retry: Int = 10): Map[String, String] = {
var retries = 0
var rules = Map[String, String]()
import scala.collection.JavaConverters._
while (retries < retry) {
// Request data
val response = Request.Get(api).execute().returnResponse()
if (response.getStatusLine.getStatusCode == 200) {
try {
val res = JSON.parseObject(response.getEntity.getContent, classOf[JSONObject]).asInstanceOf[JSONObject]
/**
* 解析json数据,并展开成Map格式,key为pointId,value为instanceParams
* 如:
* [{
* "instanceId": "1",
* "instanceParams": "[{\"label\":\"上限值\",\"name\":\"upperbound\",\"value\":\"100.823\"},
* {\"label\":\"下限值\",\"name\":\"lowerbound\",\"value\":\"50.534\"}]",
* "pointId": [
* "hiacloud/000000F",
* "hiacloud/000002F",
* "hiacloud/000001F"
* ]
* }]
* 转成如下格式:
* ("hiacloud/000000F"->"[{\"label\":\"上限值\",\"name\":\"upperbound\",\"value\":\"100.823\"},
* {\"label\":\"下限值\",\"name\":\"lowerbound\",\"value\":\"50.534\"}]")
* ……
*/
rules = res.getJSONArray("data").asScala.flatMap(x => {
val j = x.asInstanceOf[JSONObject]
val instanceParams = j.getString("instanceParams")
val pointIds = j.getJSONArray("pointId")
pointIds.asScala.toArray.map(x => x.toString -> instanceParams)
}).toMap
} catch {
case e: Exception => retries += 1
}
retries = retry
}
else retries += 1
}
rules
}
测试如下:
val api = "http://192.168.66.194:8088/rulemgr/ruleInstanceWithBindByCode?code=shxxpb"
println(requestRules(api))
/*
Map(
hiacloud/000002F -> [{"label":"上限值","name":"upperbound","value":"100.823"},{"label":"下限值","name":"lowerbound","value":"50.534"}],
hiacloud/000001F -> [{"label":"上限值","name":"upperbound","value":"100.823"},{"label":"下限值","name":"lowerbound","value":"50.534"}],
*/
处理kafka数据,与REST数据合并
def handleMessage(values: Array[Byte]): InternalRow = {
val g = new Gson()
// 处理kafka数据,转为json格式
val message = g.fromJson(Bytes.toString(values), classOf[Array[Message]])(0)
var row = InternalRow()
try {
// 生成基本数据
val rowList: List[Any] = List[Any](
UTF8String.fromString(message.namespace),
message.v.substring(2).toDouble,
message.s,
DateTimeUtils.fromJavaTimestamp(new java.sql.Timestamp(message.t)),
UTF8String.fromString(message.gatewayId),
UTF8String.fromString(message.pointId)
)
val ruleKey = message.gatewayId + "/" + message.pointId
var newRowList: List[Any] = List[Any]()
// 解析REST数据
if (rules.contains(ruleKey)) {
val rule = rules(ruleKey)
newRowList = columnParameters.map(x => UTF8String.fromString(JSONPath.read(rule, x._2).asInstanceOf[String])).toList
} else {
newRowList = columnParameters.map(x => UTF8String.EMPTY_UTF8).toList
}
// 合并数据
row = InternalRow.fromSeq(rowList ::: newRowList)
} catch {
case e: Exception => println("")
}
row
}
数据写入RDD
def handle(rdd: KafkaSourceRDD): RDD[InternalRow] = {
reloadRules()
rdd.map(cr => {
val ms = handleMessage(cr.value())
InternalRow(
cr.key,
UTF8String.fromString(cr.topic),
cr.partition,
cr.offset,
DateTimeUtils.fromJavaTimestamp(new java.sql.Timestamp(cr.timestamp)),
cr.timestampType.id,
ms
)
})
}
完整代码
package org.apache.spark.sql.kafka010
import com.alibaba.fastjson.{JSON, JSONObject, JSONPath}
import com.google.gson.Gson
import org.apache.hadoop.hbase.util.Bytes
import org.apache.http.client.fluent.Request
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.util.DateTimeUtils
import org.apache.spark.sql.types._
import org.apache.spark.unsafe.types.UTF8String
/**
* @author : shirukai
* @date : 2019-01-22 11:03
* KafkaSourceRDD 处理器
*/
private[kafka010] class KafkaSourceRDDHandler(parameters: Map[String, String], batch: Long = 100) extends Serializable {
import KafkaSourceRDDHandler._
val dcParameters: Map[String, String] = getDCParameters(parameters)
val columnParameters: Map[String, String] = getColumnParameters(dcParameters)
var offset = 0
val batchSize: Long = dcParameters.getOrElse(DC_CLEANING_RULE_REQUEST_BATCH, batch).toString.toLong
val api: String = dcParameters.getOrElse(DC_CLEANING_RULE_SERVICE_API, DC_CLEANING_RULE_SERVICE_API_DEFAULT)
lazy val schema: StructType = generateSchema(columnParameters)
var rules: Map[String, String] = Map[String, String]()
def handle(rdd: KafkaSourceRDD): RDD[InternalRow] = {
reloadRules()
rdd.map(cr => {
val ms = handleMessage(cr.value())
InternalRow(
cr.key,
UTF8String.fromString(cr.topic),
cr.partition,
cr.offset,
DateTimeUtils.fromJavaTimestamp(new java.sql.Timestamp(cr.timestamp)),
cr.timestampType.id,
ms
)
})
}
def reloadRules(): Unit = {
if (offset == batchSize || offset == 0) {
offset = 0
rules = requestRules(api)
}
offset += 1
}
def handleMessage(values: Array[Byte]): InternalRow = {
val g = new Gson()
// 处理kafka数据,转为json格式
val message = g.fromJson(Bytes.toString(values), classOf[Array[Message]])(0)
var row = InternalRow()
try {
// 生成基本数据
val rowList: List[Any] = List[Any](
UTF8String.fromString(message.namespace),
message.v.substring(2).toDouble,
message.s,
DateTimeUtils.fromJavaTimestamp(new java.sql.Timestamp(message.t)),
UTF8String.fromString(message.gatewayId),
UTF8String.fromString(message.pointId)
)
val ruleKey = message.gatewayId + "/" + message.pointId
var newRowList: List[Any] = List[Any]()
// 解析REST数据
if (rules.contains(ruleKey)) {
val rule = rules(ruleKey)
newRowList = columnParameters.map(x => UTF8String.fromString(JSONPath.read(rule, x._2).asInstanceOf[String])).toList
} else {
newRowList = columnParameters.map(x => UTF8String.EMPTY_UTF8).toList
}
// 合并数据
row = InternalRow.fromSeq(rowList ::: newRowList)
} catch {
case e: Exception => println("")
}
row
}
}
private[kafka010] object KafkaSourceRDDHandler extends Serializable {
val kafkaSchema: List[StructField] = List[StructField](
StructField("key", BinaryType),
StructField("topic", StringType),
StructField("partition", IntegerType),
StructField("offset", LongType),
StructField("timestamp", TimestampType),
StructField("timestampType", IntegerType)
)
val valueSchema: List[StructField] = List[StructField](
StructField("namespace", StringType),
StructField("v", DoubleType),
StructField("s", IntegerType),
StructField("t", TimestampType),
StructField("gatewayId", StringType),
StructField("pointId", StringType)
)
val DC_CLEANING_RULE_PREFIX = "dc.cleaning.rule."
val DC_CLEANING_RULE_REQUEST_BATCH = "dc.cleaning.rule.request.batch"
val DC_CLEANING_RULE_COLUMN = "column."
val DC_CLEANING_RULE_SERVICE_API = "service.api"
val DC_CLEANING_RULE_SERVICE_API_DEFAULT = "http://192.168.66.194:8088/rulemgr/ruleInstanceWithBindByCode?code=shxxpb"
val SCHEMA_VALUE_NAME = "value"
def getDCParameters(parameters: Map[String, String]): Map[String, String] = parameters
.filter(_._1.startsWith(DC_CLEANING_RULE_PREFIX))
.map(parameter => (parameter._1.stripPrefix(DC_CLEANING_RULE_PREFIX), parameter._2))
def getColumnParameters(dcParameters: Map[String, String]): Map[String, String] = dcParameters
.filter(_._1.contains(DC_CLEANING_RULE_COLUMN))
.map(parameter => (parameter._1.stripPrefix(DC_CLEANING_RULE_COLUMN), parameter._2))
def schema(parameters: Map[String, String]): StructType = {
val dcParams = getDCParameters(parameters)
generateSchema(getColumnParameters(dcParams))
}
def generateSchema(columnParameters: Map[String, String]): StructType = {
val newValueSchema = valueSchema ::: columnParameters.map(p => StructField(p._1, DataTypes.StringType)).toList
StructType(kafkaSchema :+ StructField(SCHEMA_VALUE_NAME, StructType(newValueSchema)))
}
/**
* 请求规则
*
* @param api 请求地址
* @param retry 重试次数
* @return Map[pointId,instanceParams]
*/
def requestRules(api: String, retry: Int = 10): Map[String, String] = {
var retries = 0
var rules = Map[String, String]()
import scala.collection.JavaConverters._
while (retries < retry) {
// Request data
val response = Request.Get(api).execute().returnResponse()
if (response.getStatusLine.getStatusCode == 200) {
try {
val res = JSON.parseObject(response.getEntity.getContent, classOf[JSONObject]).asInstanceOf[JSONObject]
/**
* 解析json数据,并展开成Map格式,key为pointId,value为instanceParams
* 如:
* [{
* "instanceId": "1",
* "instanceParams": "[{\"label\":\"上限值\",\"name\":\"upperbound\",\"value\":\"100.823\"},
* {\"label\":\"下限值\",\"name\":\"lowerbound\",\"value\":\"50.534\"}]",
* "pointId": [
* "hiacloud/000000F",
* "hiacloud/000002F",
* "hiacloud/000001F"
* ]
* }]
* 转成如下格式:
* ("hiacloud/000000F"->"[{\"label\":\"上限值\",\"name\":\"upperbound\",\"value\":\"100.823\"},
* {\"label\":\"下限值\",\"name\":\"lowerbound\",\"value\":\"50.534\"}]")
* ……
*/
rules = res.getJSONArray("data").asScala.flatMap(x => {
val j = x.asInstanceOf[JSONObject]
val instanceParams = j.getString("instanceParams")
val pointIds = j.getJSONArray("pointId")
pointIds.asScala.toArray.map(x => x.toString -> instanceParams)
}).toMap
} catch {
case e: Exception => retries += 1
}
retries = retry
}
else retries += 1
}
rules
}
case class Message(namespace: String, v: String, s: Int, t: Long, gatewayId: String, pointId: String)
def main(args: Array[String]): Unit = {
val params = Map[String,String]("dc.cleaning.rule.column.test"->"test")
schema(params).printTreeString()
/*
root
|-- key: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
|-- value: struct (nullable = true)
| |-- namespace: string (nullable = true)
| |-- v: double (nullable = true)
| |-- s: integer (nullable = true)
| |-- t: timestamp (nullable = true)
| |-- gatewayId: string (nullable = true)
| |-- pointId: string (nullable = true)
| |-- test: string (nullable = true)
*/
val api = "http://192.168.66.194:8088/rulemgr/ruleInstanceWithBindByCode?code=shxxpb"
println(requestRules(api))
/*
Map(
hiacloud/000002F -> [{"label":"上限值","name":"upperbound","value":"100.823"},{"label":"下限值","name":"lowerbound","value":"50.534"}],
hiacloud/000001F -> [{"label":"上限值","name":"upperbound","value":"100.823"},{"label":"下限值","name":"lowerbound","value":"50.534"}],
*/
}
}
2.3.2.2 重写Source类:KafkaWithRuleSource
上一步,我们的重点工作已经完成,下面要将我们写的KafkaSourceRDDHandler应用到KafkaSource中,所以我们要重写Source类,可以直接将KafkaSource的代码直接拷贝过来,修改部分代码即可。KafkaSource位置:org.apache.spark.sql.kafka010.KafkaSource。主要修改内容如下所示:
实例化KafkaSourceRDDHandler
private val ksrh = new KafkaSourceRDDHandler(sourceOptions)
重写Schema
override def schema: StructType = ksrh.schema
处理KafkaRDD
注释原来的创建RDD的代码,使用我们上一步写的KafkaSourceRDDHandle来对RDD进行处理
// Create an RDD that reads from Kafka and get the (key, value) pair as byte arrays.
// val rdd = new KafkaSourceRDD(
// sc, executorKafkaParams, offsetRanges, pollTimeoutMs, failOnDataLoss,
// reuseKafkaConsumer = true).map { cr =>
// InternalRow(
// cr.key,
// cr.value,
// UTF8String.fromString(cr.topic),
// cr.partition,
// cr.offset,
// DateTimeUtils.fromJavaTimestamp(new java.sql.Timestamp(cr.timestamp)),
// cr.timestampType.id,
// UTF8String.fromBytes(cr.value())
// )
// }
val rdd = ksrh.handle(new KafkaSourceRDD(
sc, executorKafkaParams, offsetRanges, pollTimeoutMs, failOnDataLoss,
reuseKafkaConsumer = true
))
完整代码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.kafka010
import java.{util => ju}
import java.io._
import java.nio.charset.StandardCharsets
import org.apache.commons.io.IOUtils
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkContext
import org.apache.spark.internal.Logging
import org.apache.spark.scheduler.ExecutorCacheTaskLocation
import org.apache.spark.sql._
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.util.DateTimeUtils
import org.apache.spark.sql.execution.streaming._
import org.apache.spark.sql.kafka010.KafkaSource._
import org.apache.spark.sql.types.{StructField, _}
import org.apache.spark.unsafe.types.UTF8String
/**
* A [[Source]] that reads data from Kafka using the following design.
*
* - The [[KafkaSourceOffset]] is the custom [[Offset]] defined for this source that contains
* a map of TopicPartition -> offset. Note that this offset is 1 + (available offset). For
* example if the last record in a Kafka topic "t", partition 2 is offset 5, then
* KafkaSourceOffset will contain TopicPartition("t", 2) -> 6. This is done keep it consistent
* with the semantics of `KafkaConsumer.position()`.
*
* - The [[KafkaSource]] written to do the following.
*
* - As soon as the source is created, the pre-configured [[KafkaOffsetReader]]
* is used to query the initial offsets that this source should
* start reading from. This is used to create the first batch.
*
* - `getOffset()` uses the [[KafkaOffsetReader]] to query the latest
* available offsets, which are returned as a [[KafkaSourceOffset]].
*
* - `getBatch()` returns a DF that reads from the 'start offset' until the 'end offset' in
* for each partition. The end offset is excluded to be consistent with the semantics of
* [[KafkaSourceOffset]] and `KafkaConsumer.position()`.
*
* - The DF returned is based on [[KafkaSourceRDD]] which is constructed such that the
* data from Kafka topic + partition is consistently read by the same executors across
* batches, and cached KafkaConsumers in the executors can be reused efficiently. See the
* docs on [[KafkaSourceRDD]] for more details.
*
* Zero data lost is not guaranteed when topics are deleted. If zero data lost is critical, the user
* must make sure all messages in a topic have been processed when deleting a topic.
*
* There is a known issue caused by KAFKA-1894: the query using KafkaSource maybe cannot be stopped.
* To avoid this issue, you should make sure stopping the query before stopping the Kafka brokers
* and not use wrong broker addresses.
*/
private[kafka010] class KafkaWithRuleSource(
sqlContext: SQLContext,
kafkaReader: KafkaOffsetReader,
executorKafkaParams: ju.Map[String, Object],
sourceOptions: Map[String, String],
metadataPath: String,
startingOffsets: KafkaOffsetRangeLimit,
failOnDataLoss: Boolean)
extends Source with Logging {
private val ksrh = new KafkaSourceRDDHandler(sourceOptions)
private val sc = sqlContext.sparkContext
private val pollTimeoutMs = sourceOptions.getOrElse(
"kafkaConsumer.pollTimeoutMs",
sc.conf.getTimeAsMs("spark.network.timeout", "120s").toString
).toLong
private val maxOffsetsPerTrigger =
sourceOptions.get("maxOffsetsPerTrigger").map(_.toLong)
/**
* Lazily initialize `initialPartitionOffsets` to make sure that `KafkaConsumer.poll` is only
* called in StreamExecutionThread. Otherwise, interrupting a thread while running
* `KafkaConsumer.poll` may hang forever (KAFKA-1894).
*/
private lazy val initialPartitionOffsets = {
val metadataLog =
new HDFSMetadataLog[KafkaSourceOffset](sqlContext.sparkSession, metadataPath) {
override def serialize(metadata: KafkaSourceOffset, out: OutputStream): Unit = {
out.write(0) // A zero byte is written to support Spark 2.1.0 (SPARK-19517)
val writer = new BufferedWriter(new OutputStreamWriter(out, StandardCharsets.UTF_8))
writer.write("v" + VERSION + "\n")
writer.write(metadata.json)
writer.flush
}
override def deserialize(in: InputStream): KafkaSourceOffset = {
in.read() // A zero byte is read to support Spark 2.1.0 (SPARK-19517)
val content = IOUtils.toString(new InputStreamReader(in, StandardCharsets.UTF_8))
// HDFSMetadataLog guarantees that it never creates a partial file.
assert(content.length != 0)
if (content(0) == 'v') {
val indexOfNewLine = content.indexOf("\n")
if (indexOfNewLine > 0) {
val version = parseVersion(content.substring(0, indexOfNewLine), VERSION)
KafkaSourceOffset(SerializedOffset(content.substring(indexOfNewLine + 1)))
} else {
throw new IllegalStateException(
s"Log file was malformed: failed to detect the log file version line.")
}
} else {
// The log was generated by Spark 2.1.0
KafkaSourceOffset(SerializedOffset(content))
}
}
}
metadataLog.get(0).getOrElse {
val offsets = startingOffsets match {
case EarliestOffsetRangeLimit => KafkaSourceOffset(kafkaReader.fetchEarliestOffsets())
case LatestOffsetRangeLimit => KafkaSourceOffset(kafkaReader.fetchLatestOffsets())
case SpecificOffsetRangeLimit(p) => kafkaReader.fetchSpecificOffsets(p, reportDataLoss)
}
metadataLog.add(0, offsets)
logInfo(s"Initial offsets: $offsets")
offsets
}.partitionToOffsets
}
private var currentPartitionOffsets: Option[Map[TopicPartition, Long]] = None
override def schema: StructType = ksrh.schema
/** Returns the maximum available offset for this source.
* 获取偏移量
* */
override def getOffset: Option[Offset] = {
// Make sure initialPartitionOffsets is initialized
initialPartitionOffsets
// 获取最新的偏移量
val latest = kafkaReader.fetchLatestOffsets()
// 看看有没有指定每个Trigger最大的偏移量
val offsets = maxOffsetsPerTrigger match {
case None =>
// 如果没有指定,返回最新的偏移量
latest
case Some(limit) if currentPartitionOffsets.isEmpty =>
// 如果指定了,并判断当前分区的偏移量是否为空
// 如果为空,说明之前没有消费过,取初始化的offset的
// 初始化的offset是从元数据里取的(hdfs或这文件)
rateLimit(limit, initialPartitionOffsets, latest)
case Some(limit) =>
// 如果当前偏移量不为空,根据当前的偏移量还有最新的偏移量以及每个trigger的最大偏移量得到这一批次的偏移量
rateLimit(limit, currentPartitionOffsets.get, latest)
}
currentPartitionOffsets = Some(offsets)
logDebug(s"GetOffset: ${offsets.toSeq.map(_.toString).sorted}")
Some(KafkaSourceOffset(offsets))
}
/** Proportionally distribute limit number of offsets among topicpartitions */
private def rateLimit(
limit: Long,
from: Map[TopicPartition, Long],
until: Map[TopicPartition, Long]): Map[TopicPartition, Long] = {
val fromNew = kafkaReader.fetchEarliestOffsets(until.keySet.diff(from.keySet).toSeq)
val sizes = until.flatMap {
case (tp, end) =>
// If begin isn't defined, something's wrong, but let alert logic in getBatch handle it
from.get(tp).orElse(fromNew.get(tp)).flatMap { begin =>
val size = end - begin
logDebug(s"rateLimit $tp size is $size")
if (size > 0) Some(tp -> size) else None
}
}
val total = sizes.values.sum.toDouble
if (total < 1) {
until
} else {
until.map {
case (tp, end) =>
tp -> sizes.get(tp).map { size =>
val begin = from.get(tp).getOrElse(fromNew(tp))
val prorate = limit * (size / total)
logDebug(s"rateLimit $tp prorated amount is $prorate")
// Don't completely starve small topicpartitions
val off = begin + (if (prorate < 1) Math.ceil(prorate) else Math.floor(prorate)).toLong
logDebug(s"rateLimit $tp new offset is $off")
// Paranoia, make sure not to return an offset that's past end
Math.min(end, off)
}.getOrElse(end)
}
}
}
/**
* Returns the data that is between the offsets
* [`start.get.partitionToOffsets`, `end.partitionToOffsets`), i.e. end.partitionToOffsets is
* exclusive.
*/
override def getBatch(start: Option[Offset], end: Offset): DataFrame = {
// Make sure initialPartitionOffsets is initialized
initialPartitionOffsets
logInfo(s"GetBatch called with start = $start, end = $end")
val untilPartitionOffsets = KafkaSourceOffset.getPartitionOffsets(end)
// On recovery, getBatch will get called before getOffset
if (currentPartitionOffsets.isEmpty) {
currentPartitionOffsets = Some(untilPartitionOffsets)
}
if (start.isDefined && start.get == end) {
return sqlContext.internalCreateDataFrame(
sqlContext.sparkContext.emptyRDD, schema, isStreaming = true)
}
val fromPartitionOffsets = start match {
case Some(prevBatchEndOffset) =>
KafkaSourceOffset.getPartitionOffsets(prevBatchEndOffset)
case None =>
initialPartitionOffsets
}
// Find the new partitions, and get their earliest offsets
val newPartitions = untilPartitionOffsets.keySet.diff(fromPartitionOffsets.keySet)
val newPartitionOffsets = kafkaReader.fetchEarliestOffsets(newPartitions.toSeq)
if (newPartitionOffsets.keySet != newPartitions) {
// We cannot get from offsets for some partitions. It means they got deleted.
val deletedPartitions = newPartitions.diff(newPartitionOffsets.keySet)
reportDataLoss(
s"Cannot find earliest offsets of ${deletedPartitions}. Some data may have been missed")
}
logInfo(s"Partitions added: $newPartitionOffsets")
newPartitionOffsets.filter(_._2 != 0).foreach { case (p, o) =>
reportDataLoss(
s"Added partition $p starts from $o instead of 0. Some data may have been missed")
}
val deletedPartitions = fromPartitionOffsets.keySet.diff(untilPartitionOffsets.keySet)
if (deletedPartitions.nonEmpty) {
reportDataLoss(s"$deletedPartitions are gone. Some data may have been missed")
}
// Use the until partitions to calculate offset ranges to ignore partitions that have
// been deleted
val topicPartitions = untilPartitionOffsets.keySet.filter { tp =>
// Ignore partitions that we don't know the from offsets.
newPartitionOffsets.contains(tp) || fromPartitionOffsets.contains(tp)
}.toSeq
logDebug("TopicPartitions: " + topicPartitions.mkString(", "))
val sortedExecutors = getSortedExecutorList(sc)
val numExecutors = sortedExecutors.length
logDebug("Sorted executors: " + sortedExecutors.mkString(", "))
// Calculate offset ranges
val offsetRanges = topicPartitions.map { tp =>
val fromOffset = fromPartitionOffsets.get(tp).getOrElse {
newPartitionOffsets.getOrElse(tp, {
// This should not happen since newPartitionOffsets contains all partitions not in
// fromPartitionOffsets
throw new IllegalStateException(s"$tp doesn't have a from offset")
})
}
val untilOffset = untilPartitionOffsets(tp)
val preferredLoc = if (numExecutors > 0) {
// This allows cached KafkaConsumers in the executors to be re-used to read the same
// partition in every batch.
Some(sortedExecutors(Math.floorMod(tp.hashCode, numExecutors)))
} else None
KafkaSourceRDDOffsetRange(tp, fromOffset, untilOffset, preferredLoc)
}.filter { range =>
if (range.untilOffset < range.fromOffset) {
reportDataLoss(s"Partition ${range.topicPartition}'s offset was changed from " +
s"${range.fromOffset} to ${range.untilOffset}, some data may have been missed")
false
} else {
true
}
}.toArray
// Create an RDD that reads from Kafka and get the (key, value) pair as byte arrays.
// val rdd = new KafkaSourceRDD(
// sc, executorKafkaParams, offsetRanges, pollTimeoutMs, failOnDataLoss,
// reuseKafkaConsumer = true).map { cr =>
// InternalRow(
// cr.key,
// cr.value,
// UTF8String.fromString(cr.topic),
// cr.partition,
// cr.offset,
// DateTimeUtils.fromJavaTimestamp(new java.sql.Timestamp(cr.timestamp)),
// cr.timestampType.id,
// UTF8String.fromBytes(cr.value())
// )
// }
val rdd = ksrh.handle(new KafkaSourceRDD(
sc, executorKafkaParams, offsetRanges, pollTimeoutMs, failOnDataLoss,
reuseKafkaConsumer = true
))
logInfo("GetBatch generating RDD of offset range: " +
offsetRanges.sortBy(_.topicPartition.toString).mkString(", "))
sqlContext.internalCreateDataFrame(rdd, schema, isStreaming = true)
}
/** Stop this source and free any resources it has allocated. */
override def stop(): Unit = synchronized {
kafkaReader.close()
}
override def toString(): String = s"KafkaSource[$kafkaReader]"
/**
* If `failOnDataLoss` is true, this method will throw an `IllegalStateException`.
* Otherwise, just log a warning.
*/
private def reportDataLoss(message: String): Unit = {
if (failOnDataLoss) {
throw new IllegalStateException(message + s". $INSTRUCTION_FOR_FAIL_ON_DATA_LOSS_TRUE")
} else {
logWarning(message + s". $INSTRUCTION_FOR_FAIL_ON_DATA_LOSS_FALSE")
}
}
}
/** Companion object for the [[KafkaSource]]. */
private[kafka010] object KafkaWithRuleSource {
val INSTRUCTION_FOR_FAIL_ON_DATA_LOSS_FALSE =
"""
|Some data may have been lost because they are not available in Kafka any more; either the
| data was aged out by Kafka or the topic may have been deleted before all the data in the
| topic was processed. If you want your streaming query to fail on such cases, set the source
| option "failOnDataLoss" to "true".
""".stripMargin
val INSTRUCTION_FOR_FAIL_ON_DATA_LOSS_TRUE =
"""
|Some data may have been lost because they are not available in Kafka any more; either the
| data was aged out by Kafka or the topic may have been deleted before all the data in the
| topic was processed. If you don't want your streaming query to fail on such cases, set the
| source option "failOnDataLoss" to "false".
""".stripMargin
private[kafka010] val VERSION = 1
def getSortedExecutorList(sc: SparkContext): Array[String] = {
val bm = sc.env.blockManager
bm.master.getPeers(bm.blockManagerId).toArray
.map(x => ExecutorCacheTaskLocation(x.host, x.executorId))
.sortWith(compare)
.map(_.toString)
}
private def compare(a: ExecutorCacheTaskLocation, b: ExecutorCacheTaskLocation): Boolean = {
if (a.host == b.host) {
a.executorId > b.executorId
} else {
a.host > b.host
}
}
}
2.3.2.3 重写Provider类:KafkaWithRuleProvider
Provider类是自定义Source的入口,修改内容不大,可以直接拷贝KafkaSourceProvider,位置:org.apache.spark.sql.kafka010.KafkaSourceProvider,修改内容如下所示:
重写sourceSchema
override def sourceSchema(
sqlContext: SQLContext,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): (String, StructType) = {
validateStreamOptions(parameters)
require(schema.isEmpty, "Kafka source has a fixed schema and cannot be set with a custom one")
(shortName(), KafkaSourceRDDHandler.schema(parameters))
}
重写createSource
override def createSource(
sqlContext: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source = {
validateStreamOptions(parameters)
// Each running query should use its own group id. Otherwise, the query may be only assigned
// partial data since Kafka will assign partitions to multiple consumers having the same group
// id. Hence, we should generate a unique id for each query.
val uniqueGroupId = s"spark-kafka-source-${UUID.randomUUID}-${metadataPath.hashCode}"
val caseInsensitiveParams = parameters.map { case (k, v) => (k.toLowerCase(Locale.ROOT), v) }
val specifiedKafkaParams =
parameters
.keySet
.filter(_.toLowerCase(Locale.ROOT).startsWith("kafka."))
.map { k => k.drop(6).toString -> parameters(k) }
.toMap
val startingStreamOffsets = KafkaSourceProvider.getKafkaOffsetRangeLimit(caseInsensitiveParams,
STARTING_OFFSETS_OPTION_KEY, LatestOffsetRangeLimit)
val kafkaOffsetReader = new KafkaOffsetReader(
strategy(caseInsensitiveParams),
kafkaParamsForDriver(specifiedKafkaParams),
parameters,
driverGroupIdPrefix = s"$uniqueGroupId-driver")
new KafkaWithRuleSource(
sqlContext,
kafkaOffsetReader,
kafkaParamsForExecutors(specifiedKafkaParams, uniqueGroupId),
parameters,
metadataPath,
startingStreamOffsets,
failOnDataLoss(caseInsensitiveParams))
}
2.3.2.4 测试自定义Source
package com.hollysys.spark.structured.datasource
import java.util.UUID
import org.apache.spark.sql.SparkSession
/**
* @author : shirukai
* @date : 2019-01-22 10:17
* 参数:192.168.66.194:9092 subscribe dc-data
*/
object KafkaSourceTest {
def main(args: Array[String]): Unit = {
if (args.length < 3) {
System.err.println("Usage: StructuredKafkaWordCount <bootstrap-servers> " +
"<subscribe-type> <topics> [<checkpoint-location>]")
System.exit(1)
}
val Array(bootstrapServers, subscribeType, topics, _*) = args
val checkpointLocation =
if (args.length > 3) args(3) else "/tmp/temporary-" + UUID.randomUUID.toString
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
import spark.implicits._
// Create DataSet representing the stream of input lines from kafka
val source = spark
.readStream
.format("org.apache.spark.sql.kafka010.KafkaWithRuleSourceProvider")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("dc.cleaning.rule.column.upperbound", "$.0.value")
.option("dc.cleaning.rule.column.lowerbound", "$.1.value")
.option("dc.cleaning.rule.service.api", "http://192.168.66.194:8088/rulemgr/ruleInstanceWithBindByCode?code=shxxpb")
.option("dc.cleaning.rule.request.batch", "10")
.option(subscribeType, topics)
.load()
// Start running the query that prints the running counts to the console
val query = source.select("value.*").writeStream
.outputMode("update")
.format("console")
.option("checkpointLocation", checkpointLocation)
.option("truncate", value = false).start()
query.awaitTermination()
/*
Batch: 0
-------------------------------------------
+---------+------+---+-----------------------+---------+-------+----------+----------+
|namespace|v |s |t |gatewayId|pointId|lowerbound|upperbound|
+---------+------+---+-----------------------+---------+-------+----------+----------+
|000002 |101.11|0 |2019-02-16 10:14:29.242|hiacloud |000002F|50.534 |100.823 |
|000003 |101.11|0 |2019-02-16 10:14:29.242|hiacloud |000003F| | |
|000000 |101.11|0 |2019-02-16 10:14:29.242|hiacloud |000000F|50.534 |100.823 |
|000001 |101.11|0 |2019-02-16 10:14:29.242|hiacloud |000001F|50.534 |100.823 |
+---------+------+---+-----------------------+---------+-------+----------+----------+
*/
}
}
3 基于重启Query的动态更新
3.1 应用场景
场景一:实时流数据与离线数据join,离线数据偶尔更新
场景二:某些参数偶尔需要变化,如修改写出路径、修改分区数量等等
3.2 实现思路
通过重启Query实现参数的动态更新。Query start之后,通过阻塞Driver端主线程,让Executor端Spark任务一直执行,一段时间后停止Query,更新参数,然后重新start。
3.3 Demo演示
package com.hollysys.spark.structured.usecase
import org.apache.spark.sql.SparkSession
/**
* @author : shirukai
* @date : 2019-02-16 10:43
* 通过重启Query动态更新参数
*/
object RestQueryUpdateParams {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
val source = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.66.194:9092")
.option("subscribe", "dc-data")
//.option("startingOffsets", "earliest")
.option("failOnDataLoss", "true")
.load()
import spark.implicits._
val restartTime = 1000 * 60
while (true) {
// TODO 更新参数
val query = source.writeStream
.outputMode("update")
.format("console")
//.option("checkpointLocation", checkpointLocation)
.option("truncate", value = false)
.start()
// 主线程阻塞,等待重启时间
Thread.sleep(restartTime)
// Query 停止,不再产生新批次
query.stop()
// 等待当前批次执行完
query.awaitTermination()
}
}
}
4 总结
上面实现了两种方式去动态更新参数,从开发的角度来看,第二种开发起来更简单,可控性以及灵活性更强。但是频繁重启query会对性能上有些许影响。第一种实现起来麻烦,但是后期开发使用更简单,无需关心更新逻辑,可移植性比较强,但是只能更新DataFrame,也就是说只适用于实时流数据与静态数据进行join的场景。
