版本说明:Spark2.4
前言
最近基于Spark Structured Streaming开发一套实时数据判别清洗系统,在开发过程接触了一些StructuredStreaming的新特性以及新用法。本文主要记录一下在开发过程中使用到的技术点,以及遇到的问题总结。
1 放弃Spark Streaming 选用Structured Streaming
关于当时项目技术选型最终选择StructuredStreaming的原因,主要是因为团队具有Spark开发经验且Structured 比Spark Streaming具有基于事件时间处理机制。这里简单对Spark Streaming 和Structured Streaming 做一个优劣对比,详细的内容可以参考《是时候放弃Spark Streaming,转向Structured Streaming了》
1.1 Spark Streaming的不足
- 使用Processing Time 而不是 Event Time
刚才提到,我们技术选型的时候,就是因为Spark Streaming没有事件时间处理机制,所以被放弃。简单解释一下这两个时间的概念:Processing Time 是数据到达Spark被处理的时间,Event Time 是数据自身的时间,一般表示数据产生于数据源的时间。
- Complex,low-level api
DStream (Spark Streaming 的数据模型)提供的 API 类似 RDD 的 API 的,非常的 low level。当我们编写 Spark Streaming 程序的时候,本质上就是要去构造 RDD 的 DAG 执行图,然后通过 Spark Engine 运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导致执行效率上的天壤之别。这样导致开发者的体验非常不好,也是任何一个基础框架不想看到的(基础框架的口号一般都是:你们专注于自己的业务逻辑就好,其他的交给我)。这也是很多基础系统强调 Declarative 的一个原因。
- reason about end-to-end application
DStream 只能保证自己的一致性语义是 exactly-once的,而Spark Streaming的inpu 和 output的一致性语义需要用户自己来保证。
- 批流代码不统一
尽管批流本是两套系统,但是这两套系统统一起来确实很有必要,我们有时候确实需要将我们的流处理逻辑运行到批数据上面。关于这一点,最早在 2014 年 Google 提出 Dataflow 计算服务的时候就批判了 streaming/batch 这种叫法,而是提出了 unbounded/bounded data 的说法。DStream 尽管是对 RDD 的封装,但是我们要将 DStream 代码完全转换成 RDD 还是有一点工作量的,更何况现在 Spark 的批处理都用 DataSet/DataFrame API 了。
1.2 Structured Streaming 优势
- 简洁的模型
Structured Streaming 的模型很简单,易于理解,用户可以直接把一个流想象成一个无限增长的表格
- 一致的API
和Spark SQL 共用大部分API,对Spark SQL熟悉的用户很容易上手。批处理和流处理程序可以共用代码,提高开发效率。
- 卓越的性能
Structured Streaming 在与 Spark SQL 共用 API 的同时,也直接使用了 Spark SQL 的 Catalyst 优化器和 Tungsten,数据处理性能十分出色。此外,Structured Streaming 还可以直接从未来 Spark SQL 的各种性能优化中受益。
- 多编程语言支持
Structured Streaming 直接支持目前 Spark SQL 支持的语言,包括 Scala,Java,Python,R 和 SQL。用户可以选择自己喜欢的语言进行开发
2 Structured 数据源
关于Structured数据源的问题,我在《Structured Streaming 内置数据源及实现自定义数据源》这边文章里有详细介绍。
3 Kafka JSON格式数据解析
Kafka是最为常见的数据源,kafka里我们通常会以JSON格式存储数据。Spark Structured 在处理kafka数据的时候,通常需要将kafka数据转成DataFrame,之前在《Spark Streaming解析Kafka JSON格式数据》这篇文章中介绍了几种Streaming处理Kafka JSON格式的方法,并在文末思考中,提到了Structured Streaming解析的方法。这里重新介绍几种方法。
3.1 通过定义schema 和 from_json函数解析
Kafka数据里的value如下所示为json字符串:
{"deviceId":"4d6021db-7483-4911-8025-87494776ba87","deviceName":"风机温度","deviceValue":76.3,"deviceTime":1553140083}
Structured 使用select($”value”.cast(“String”))解析如下所示:

为了使用from_json解析,我们首先要根据json结构定义好schema,如下:
val schema = StructType(Seq(
StructField("deviceId", StringType),
StructField("deviceName", StringType),
StructField("deviceValue", DoubleType),
StructField("deviceTime", LongType)
))
使用from_json函数进行解析,需要通过import org.apache.spark.sql.functions._引入函数。
.select(from_json($"value".cast("String"), schema).as("json")).select("json.*")
结果如下所示:

完整代码:
package com.hollysys.spark.structured.usecase
import com.google.gson.Gson
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
/**
* Created by shirukai on 2019-03-21 11:36
* Structured 解析Kafka数据
*/
object HandleKafkaJSONExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
val source = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "structured-json-data")
.option("maxOffsetsPerTrigger", 1000)
.option("startingOffsets", "earliest")
.option("failOnDataLoss", "true")
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val schema = StructType(Seq(
StructField("deviceId", StringType),
StructField("deviceName", StringType),
StructField("deviceValue", DoubleType),
StructField("deviceTime", LongType)
))
val query = source
.select(from_json($"value".cast("String"), schema).as("json")).select("json.*")
.writeStream
.outputMode("update")
.format("console")
//.option("checkpointLocation", checkpointLocation)
.option("truncate", value = false)
.start()
query.awaitTermination()
}
}
3.2 通过定义case class 解析
此方法是先定义好case class,然后通过map函数,将json字符串使用gson转成case class 返回。
首先根据json结构定义case class:
case class Device(deviceId: String, deviceName: String, deviceValue: Double, deviceTime: Long)
定义json字符串转case class 函数,这里使用gson
def handleJson(json: String): Device = {
val gson = new Gson()
gson.fromJson(json, classOf[Device])
}
使用map转换
.select($"value".cast("String")).as[String].map(handleJson)
结果如下所示:
完整代码:
package com.hollysys.spark.structured.usecase
import com.google.gson.Gson
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
/**
* Created by shirukai on 2019-03-21 11:36
* Structured 解析Kafka数据
*/
object HandleKafkaJSONExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
val source = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "structured-json-data")
.option("maxOffsetsPerTrigger", 1000)
.option("startingOffsets", "earliest")
.option("failOnDataLoss", "true")
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val query = source
.select($"value".cast("String")).as[String].map(handleJson)
.writeStream
.outputMode("update")
.format("console")
//.option("checkpointLocation", checkpointLocation)
.option("truncate", value = false)
.start()
query.awaitTermination()
}
def handleJson(json: String): Device = {
val gson = new Gson()
gson.fromJson(json, classOf[Device])
}
}
case class Device(deviceId: String, deviceName: String, deviceValue: Double, deviceTime: Long)
3.3 处理JSONArray格式数据
上面提到的两种方法,是处理JSONObject的情况,即”{}”。如果数据为JSONArray格式,如[{},{}]该如何处理呢?
假如我们Kafka名为structured-json-array-data的topic里的单条数据如下:
[
{
"deviceId": "4d6021db-7483-4911-8025-87494776ba87",
"deviceName": "风机温度",
"deviceValue": 76.3,
"deviceTime": 1553140083
},
{
"deviceId": "89cf0815-9a1e-4dd5-a2d9-ff16c2308ddf",
"deviceName": "风机转速",
"deviceValue": 600,
"deviceTime": 1553140021
}
]
3.3.1 from_json+explode函数处理JSONArray格式数据
首先同样需要定义好schema,这里就不重复了,与上面定义schema相同。只不过这里我们使用from_json时需要在schema外嵌套一层结构ArrayType(schema),这时拿到的是array嵌套结构的json,然后我们在使用explode函数将其展开。代码如下:
.select(from_json($"value".cast("String"), ArrayType(schema))
.as("jsonArray"))
.select(explode($"jsonArray"))
.select("col.*")

3.3.2 flatmap + case class 处理JSONArray格式数据
上面我们提到使用map + case class 能够处理JSONObject 格式的数据,同样的道理,这里我们可以使用flatmap + case class 处理 JSONArray 格式的数据。具体思路是,重写上面handleJson 的方法,将json字符串转为 Array[clase class]格式,然后传入flatmap函数。
编写handleJsonArray方法:
def handleJsonArray(jsonArray: String): Array[Device] = {
val gson = new Gson()
gson.fromJson(jsonArray, classOf[Array[Device]])
}
使用flatmap函数展开
.select($"value".cast("String")).as[String].flatMap(handleJsonArray)
4 输出模式
Structured Streaming 提供了三种输出模式:complete、update、append
- complete:将整个更新的结果表将写入外部存储器
- update:只有自上次触发后在结果表中更新的行才会写入外部存储(结果表中更新的行=新增行+更新历史行)
- append:自上次触发后,只有结果表中附加的新行才会写入外部存储器。这仅适用于预计结果表中的现有行不会更改的查询,因此,这种方式能保证每行数据仅仅输出一次。例如,带有Select,where,map,flatmap,filter,join等的query操作支持append模式。
不同类型的Streaming query 支持不同的输出模式:如下表所示:

4.1 Complete 模式
描述:
complete模式下,会将整个更新的结果表写出到外部存储,即会将整张结果表写出,重点注意”更新”这个词,这就意味着,使用Complete模式是需要有聚合操作的,因为在结果表中保存非聚合的数据是没有意义的,所以,当在没有聚合的query中使用complete输出模式,就会报如下错误:

可应用Query:
具有聚合操作的Query
Example:
以wordcount为例
/**
* 测试输出模式为complete
* 整个更新的结果表将写入外部存储器
* -------------------------------------------
* 输入:dog cat
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |1 |
* |cat |1 |
* +-----+-----+
* -------------------------------------------
* 输入:dog fish
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |2 |
* |cat |1 |
* |fish |1 |
* +-----+-----+
* -------------------------------------------
* 输入:cat lion
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |lion |1 |
* |dog |2 |
* |cat |2 |
* |fish |1 |
* +-----+-----+
* -------------------------------------------
*/
代码:
/**
* Created by shirukai on 2019-03-21 15:27
* Structured Streaming 三种输出模式的例子
* 以wordcount为例
* socket 命令:nc -lk 9090
*/
object OutputModeExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
val line = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9090)
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val words = line.as[String].flatMap(_.split(" "))
/**
* 测试输出模式为complete
* 整个更新的结果表将写入外部存储器
* -------------------------------------------
* 输入:dog cat
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |1 |
* |cat |1 |
* +-----+-----+
* -------------------------------------------
* 输入:dog fish
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |2 |
* |cat |1 |
* |fish |1 |
* +-----+-----+
* -------------------------------------------
* 输入:cat lion
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |lion |1 |
* |dog |2 |
* |cat |2 |
* |fish |1 |
* +-----+-----+
* -------------------------------------------
*/
val completeQuery = words.groupBy("value").count().writeStream
.outputMode(OutputMode.Complete())
.format("console")
.option("truncate", value = false)
.start()
completeQuery.awaitTermination()
}
}
4.2 Update模式
描述:
update模式下,会将自上次触发后在结果表中更新的行写入外部存储(结果表中更新的行=新增行+更新历史行)
可应用Query:
所有的query
Example:
/**
* 测试输出模式为:update
* 只有自上次触发后在结果表中更新的行才会写入外部存储(结果表中更新的行=新增行+更新历史行)
* -------------------------------------------
* 输入:dog cat
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |1 |
* |cat |1 |
* +-----+-----+
* -------------------------------------------
* 输入:dog fish
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |2 |
* |fish |1 |
* +-----+-----+
* -------------------------------------------
* 输入:cat lion
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |lion |1 |
* |cat |2 |
* +-----+-----+
* -------------------------------------------
*/
代码:
package com.hollysys.spark.structured.usecase
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
/**
* Created by shirukai on 2019-03-21 15:27
* Structured Streaming 三种输出模式的例子
* 以wordcount为例
* socket 命令:nc -lk 9090
*/
object OutputModeExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
val line = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9090)
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val words = line.as[String].flatMap(_.split(" "))
/**
* 测试输出模式为:update
* 只有自上次触发后在结果表中更新的行才会写入外部存储(结果表中更新的行=新增行+更新历史行)
* -------------------------------------------
* 输入:dog cat
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |1 |
* |cat |1 |
* +-----+-----+
* -------------------------------------------
* 输入:dog fish
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |dog |2 |
* |fish |1 |
* +-----+-----+
* -------------------------------------------
* 输入:cat lion
* 结果:
* +-----+-----+
* |value|count|
* +-----+-----+
* |lion |1 |
* |cat |2 |
* +-----+-----+
* -------------------------------------------
*/
val updateQuery = words.groupBy("value").count().writeStream
.outputMode(OutputMoade.Update())
.format("console")
.option("truncate", value = false)
.start()
updateQuery.awaitTermination()
}
4.3 Append 模式
描述:
此模式下,会将上次触发后,结果表中附加的新行写入外部存储器。这仅适用于预计结果表中的现有行不会更改的查询,因此,这种方式能保证每行数据仅仅输出一次。例如,带有Select,where,map,flatmap,filter,join等的query操作支持append模式。支持聚合操作下使用Append模式,但是要求聚合操作必须设置Watermark,否则会报如下错误:

可应用Query:
带Watermark的聚合操作
flatMapGroupWithState函数之后使用聚合操作
非聚合操作
Example:
package com.hollysys.spark.structured.usecase
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
/**
* Created by shirukai on 2019-03-21 15:27
* Structured Streaming 三种输出模式的例子
* 以wordcount为例
* socket 命令:nc -lk 9090
*/
object OutputModeExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
val line = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9090)
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val words = line.as[String].flatMap(_.split(" "))
/**
* 测试输出模式为:append
* 自上次触发后,只有结果表中附加的新行才会写入外部存储器。这仅适用于预计结果表中的现有行不会更改的查询
* -------------------------------------------
* 输入:dog cat
* 结果:
* +-----+
* |value|
* +-----+
* |dog |
* |cat |
* +-----+
* -------------------------------------------
* 输入:dog fish
* 结果:
* +-----+
* |value|
* +-----+
* |dog |
* |fish |
* +-----+
* -------------------------------------------
* 输入:cat lion
* 结果:
* +-----+
* |value|
* +-----+
* |cat |
* |lion |
* +-----+
* -------------------------------------------
*/
val appendQuery = words.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.option("truncate", value = false)
.start()
appendQuery.awaitTermination()
}
5基于事件时间的窗口操作
使用Structured Streaming 基于时间的滑动窗口的聚合操作是很简单的,使用window()函数即可,很像分组聚合。在一个分组聚合操作中,聚合值被唯一保存在用户指定的列中。在基于窗口的聚合情况下,对于行的事件时间的每个窗口,维护聚合指。
5.1 窗口函数的简单使用:对十分钟的数据进行WordCount
在前面的输出模式的例子中,我们使用了wordcount进行演示。现在有这样的一个需求:要求我们以10分钟为窗口,且每5分钟滑动一次来进行10分钟内的词频统计。如下图所示,此图是官网的改进版,按照实际输出画图。由于使用的输出模式是Complete,会将完整的结果表输出。很容易理解,12:05时触发计算,计算12:02 和12:03来的两条数据,因为我们的窗口为滑动窗口,10分钟窗口大小,5分钟滑动一次,所以Spark会为每条数据划分两个窗口,结果如图所示。关于窗口的划分,后面会单独解释。
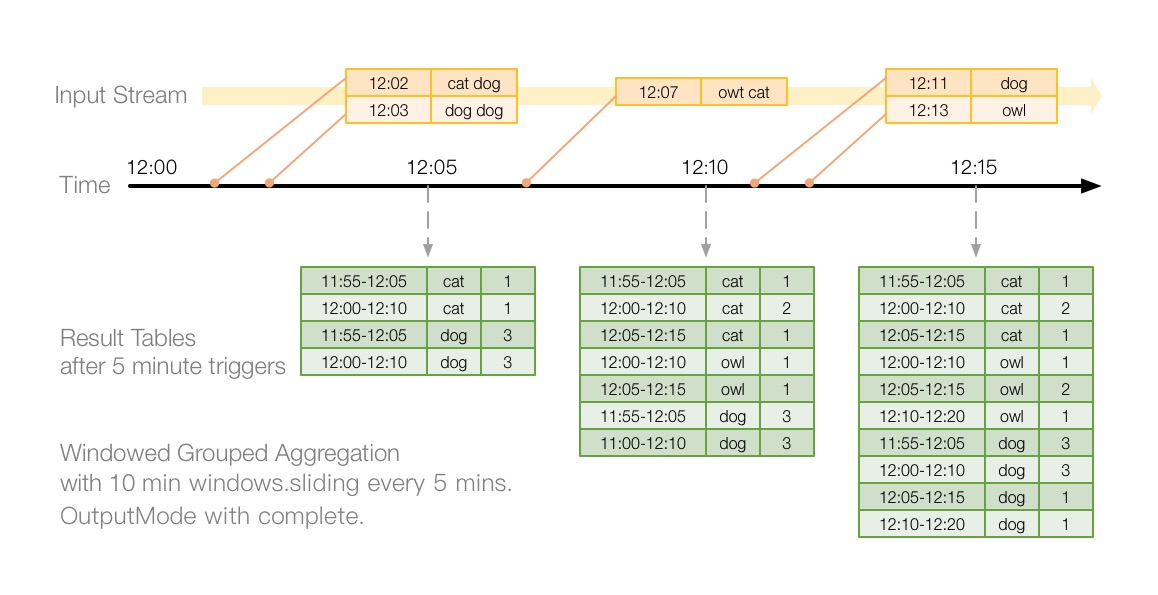
下面将使用具体的程序,进行演示。
package com.hollysys.spark.structured.usecase
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.TimestampType
/**
* Created by shirukai on 2019-03-22 14:17
* Structured Streaming 窗口函数操作例子
* 基于事件时间的wordcount
* socket:nc -lk 9090
*/
object WindowOptionExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
// Read stream form socket,The data format is: 1553235690:dog cat|1553235691:cat fish
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9090)
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
// Transform socket lines to DataFrame of schema { timestamp: Timestamp, word: String }
val count = lines.as[String].flatMap(line => {
val lineSplits = line.split("[|]")
lineSplits.flatMap(item => {
val itemSplits = item.split(":")
val t = itemSplits(0).toLong
itemSplits(1).split(" ").map(word => (t, word))
})
}).toDF("time", "word")
.select($"time".cast(TimestampType), $"word")
// Group the data by window and word and compute the count of each group
.groupBy(
window($"time", "10 minutes", "5 minutes"),
$"word"
).count()
val query = count.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.option("truncate", value = false)
.start()
query.awaitTermination()
}
}
上面的程序,是模拟数据处理,从socket里读取1553235690:dog cat|1553235691:cat owl格式的数据,然后经过转换,转成schema为{ timestamp: Timestamp, word: String }的DataFrame,然后使用window函数进行窗口划分,再使用groupBy进行聚合count,最后将结果输出到控制台,输出模式为Complete。
通过nc -lk 9090向socket发送数据
发送:1553227320:cat dog|1553227380:dog dog
结果:
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-03-22 11:55:00, 2019-03-22 12:05:00]|cat |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|cat |1 |
|[2019-03-22 11:55:00, 2019-03-22 12:05:00]|dog |3 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|dog |3 |
+------------------------------------------+----+-----+
发送:1553227620:owl cat
结果:
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-03-22 11:55:00, 2019-03-22 12:05:00]|cat |1 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|cat |1 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|owl |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|owl |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|cat |2 |
|[2019-03-22 11:55:00, 2019-03-22 12:05:00]|dog |3 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|dog |3 |
+------------------------------------------+----+-----+
发送:1553227860:dog|1553227980:owl
结果:
-------------------------------------------
Batch: 2
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-03-22 11:55:00, 2019-03-22 12:05:00]|cat |1 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|dog |1 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|cat |1 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|owl |2 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|owl |1 |
|[2019-03-22 12:10:00, 2019-03-22 12:20:00]|owl |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|cat |2 |
|[2019-03-22 12:10:00, 2019-03-22 12:20:00]|dog |1 |
|[2019-03-22 11:55:00, 2019-03-22 12:05:00]|dog |3 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|dog |3 |
+------------------------------------------+----+-----+
5.2 窗口划分:window()函数
上面基于窗口的词频统计例子中,我们接触到了window()函数,这是spark的内置函数,具体底层实现,没要找到的源码位置,如有人知晓,烦请指点。我们可以看到在org.apache.spark.sql.functions中的window函数解析成表达式之前的函数定义:
/**
* window
*
* @param timeColumn 事件时间所在的列
* @param windowDuration 窗口间隔 字符串表达式:"10 seconds" or "10 minutes"等
* @param slideDuration 滑动间隔 字符串表达式:"10 seconds" or "10 minutes"等
* @return Column
*/
def window(timeColumn: Column, windowDuration: String, slideDuration: String): Column = {
window(timeColumn, windowDuration, slideDuration, "0 second")
}
5.2.1 简单例子
这里通过一个简单的例子,来演示一下window()函数的作用。
我们对上面的WordCount的例子做一下改变,不去groupBy(window()),直接select来看一下window()的效果。
// Transform socket lines to DataFrame of schema { timestamp: Timestamp, word: String }
val count = lines.as[String].flatMap(line => {
val lineSplits = line.split("[|]")
lineSplits.flatMap(item => {
val itemSplits = item.split(":")
val t = itemSplits(0).toLong
itemSplits(1).split(" ").map(word => (t, word))
})
}).toDF("time", "word")
.select($"time".cast(TimestampType), $"word")
.select(
window($"time", "10 minutes", "5 minutes"),
$"word",
$"time"
)
如上,我们以10分钟为一个窗口,5分钟滑动一次,这时输入一个2019-03-23 13:58:24时间的数据,会产生几个窗口呢?
输入:1553320704:cat
结果:如下所示产生了两个窗口,13:50-14:00 和13:55-14:05
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----+-------------------+
|window |word|time |
+------------------------------------------+----+-------------------+
|[2019-03-23 13:50:00, 2019-03-23 14:00:00]|cat |2019-03-23 13:58:24|
|[2019-03-23 13:55:00, 2019-03-23 14:05:00]|cat |2019-03-23 13:58:24|
+------------------------------------------+----+-------------------+
如果我同样设置10分钟的窗口,3分钟滑动一次,同样输入2019-03-23 13:58:24时间的数据,这时会产生几个窗口呢?
输入:1553320704:cat
结果:如下所示产生了三个窗口
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+----+-------------------+
|window |word|time |
+------------------------------------------+----+-------------------+
|[2019-03-23 13:51:00, 2019-03-23 14:01:00]|cat |2019-03-23 13:58:24|
|[2019-03-23 13:54:00, 2019-03-23 14:04:00]|cat |2019-03-23 13:58:24|
|[2019-03-23 13:57:00, 2019-03-23 14:07:00]|cat |2019-03-23 13:58:24|
+------------------------------------------+----+-------------------+
如果我同样设置10分钟的窗口,2分钟滑动一次,同样输入2019-03-23 13:58:24时间的数据,这时会产生几个窗口呢?
输入:1553320704:cat
结果:如下所示产生了五个窗口
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+----+-------------------+
|window |word|time |
+------------------------------------------+----+-------------------+
|[2019-03-23 13:50:00, 2019-03-23 14:00:00]|cat |2019-03-23 13:58:24|
|[2019-03-23 13:52:00, 2019-03-23 14:02:00]|cat |2019-03-23 13:58:24|
|[2019-03-23 13:54:00, 2019-03-23 14:04:00]|cat |2019-03-23 13:58:24|
|[2019-03-23 13:56:00, 2019-03-23 14:06:00]|cat |2019-03-23 13:58:24|
|[2019-03-23 13:58:00, 2019-03-23 14:08:00]|cat |2019-03-23 13:58:24|
+------------------------------------------+----+-------------------+
5.2.3 窗口划分逻辑
上面例子中,我们可以使用简单的窗口函数,根据不同的窗口大小和滑动间隔划分出不同的窗口,那么具体Spark是如何划分窗口的呢?如下图所示,我们以窗口大小为10分钟,滑动间隔为5分为例,进行窗口划分。
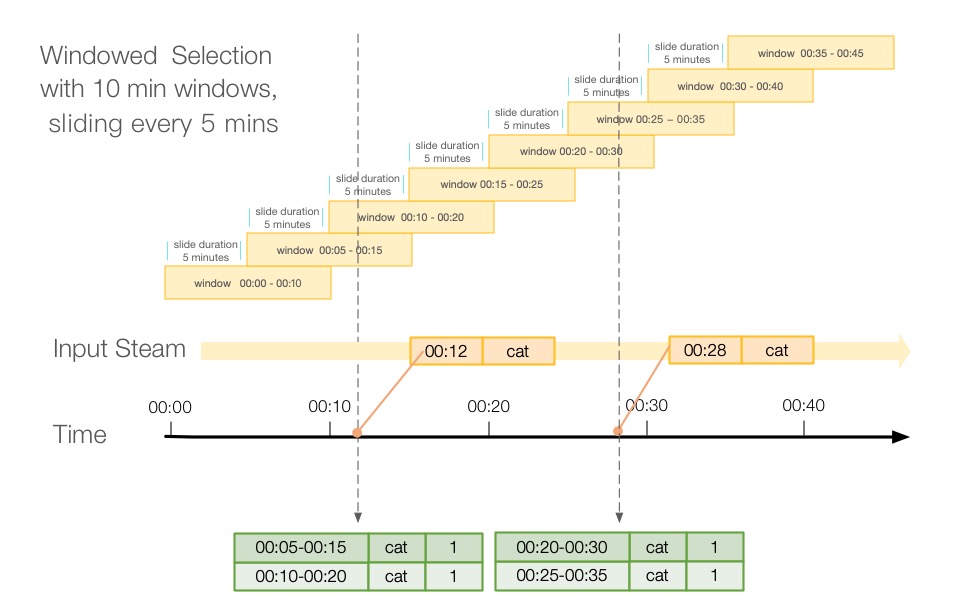
通过上面的图我们可以看出,当00:12这个时间点来了一条数据之后,它会落在00:05-00:15和00:10-00:20这两个窗口里,同样,当00:28来的数据会落到00:20-00:30和00:25-00:35这两个窗口。对于这个例子来说,每一条数据都会落到两个窗口里,那么,关于具体落到哪个窗口里是如何计算的呢?我们可以查看Spark window函数的实现,源码位置在org.apache.spark.sql.catalyst.analysis包下的SimpleAnalyzer,查看TimeWindowing的实现,注释里说的很清楚。
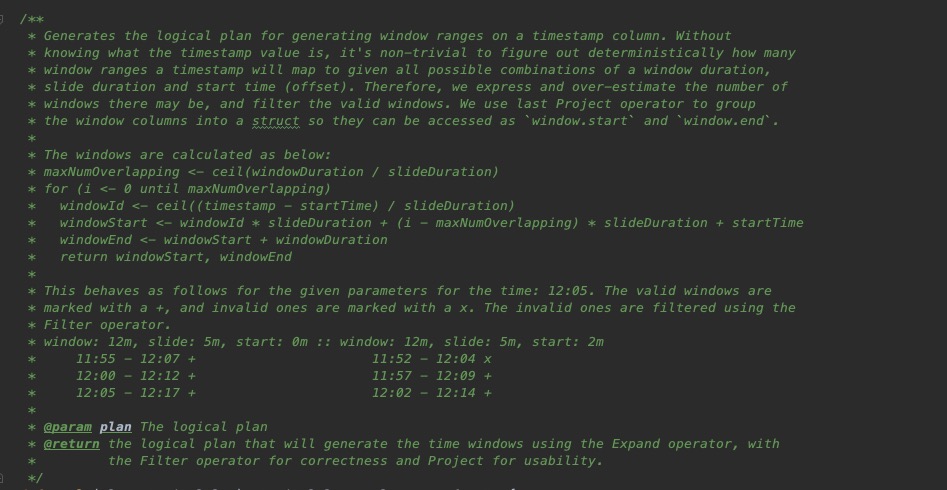
大体步骤如下
1 首先计算一个窗口跨度里最多有多少个重叠窗口
maxNumOverlapping = ceil(windowDuration / slideDuration)
使用窗口跨度除以滑动间隔向上取整,即可以得到最大重叠窗口个数,如windowDuration=10,slideDuration=5,则maxNumOverlapping=2;windowDuration=10,slideDuration=3,则maxNumOverlapping=4。
val overlappingWindows =
math.ceil(window.windowDuration * 1.0 / window.slideDuration).toInt
2 计算当前时间落入的距离窗口开始时间最近的窗口ID
windowId = ceil((timestamp - startTime) / slideDuration)
startTime这里指的是整个时间维度的开始时间,默认为0,即时间戳的0

使用当前时间减去开始时间startTime然后除以窗口跨度向上取整就能求出窗口ID来,这个ID表示,从startTime开始,一共划分了多少个窗口。
val division = (PreciseTimestampConversion(
window.timeColumn, TimestampType, LongType) - window.startTime) / window.slideDuration
val ceil = Ceil(division)
3 按最多的情况窗口划分
上面第一步中,我们计算出了一个窗口跨度里最多有多少个重叠窗口,这个有什么意义呢?其实它可以表示,一条数据,最多可以落到多少个窗口里,注意这里是最多,有些情况下,一条数据可能落不到计算的最多窗口里。比如说,当我窗口时间设置为10分钟,窗口跨度设置为3分钟的时候,这个时候计算出最多重叠个数为4,大多数情况下为3,如下图所示:
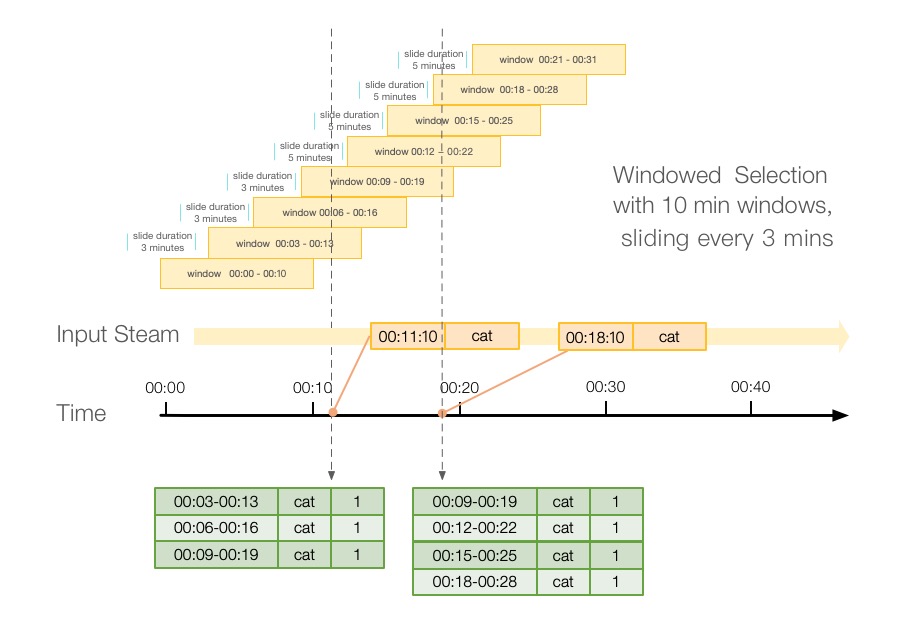
所以这里Spark先按照最多的情况划分窗口
val windows =
Seq.tabulate(overlappingWindows)(i => getWindow(i, overlappingWindows))
4 过滤不符合要求的窗口
通过上面的图,我们可以看出,如果我们按照最多重叠个数来划分窗口,数据会落到不正确的窗口中,如果我们 划分00:11:10这条数据,它会落到:00:00-00:10、00:03-00:13、00:06-00:16、00:09-00:19这四个窗口中,显然,00:00-00:10这个窗口是个错误的窗口,不需要出现,所以这里Spark又对窗口进行了一次过滤。
val filterExpr =
window.timeColumn >= windowAttr.getField(WINDOW_START) &&
window.timeColumn < windowAttr.getField(WINDOW_END)
通过上面四个步骤,spark很容易将我们的数据,划分到不同的窗口中,从而实现了窗口计算。
下面我按照源码思路,简单的实现了一个窗口划分的Demo,代码如下:
package com.hollysys.spark.structured.usecase
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.unsafe.types.CalendarInterval
/**
* Created by shirukai on 2019-03-23 11:29
* 官方源码window()函数实现
*
*
* The windows are calculated as below:
* maxNumOverlapping <- ceil(windowDuration / slideDuration)
* for (i <- 0 until maxNumOverlapping)
* windowId <- ceil((timestamp - startTime) / slideDuration)
* windowStart <- windowId * slideDuration + (i - maxNumOverlapping) * slideDuration + startTime
* windowEnd <- windowStart + windowDuration
* return windowStart, windowEnd
*/
object WindowSourceFunctionExample {
val TARGET_FORMAT: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
/**
* 计算窗口ID
*
* @param t 事件时间
* @param s 滑动间隔
* @return id
*/
def calculateWindowId(t: Long, s: Long): Int = Math.ceil(t.toDouble / s.toDouble).toInt
/**
* 计算窗口开始时间
*
* @param windowId 窗口ID
* @param s 滑动间隔
* @param maxNumOverlapping 最大重叠窗口个数
* @param numOverlapping 当前重叠数
* @return start
*/
def calculateWindowStart(windowId: Int, s: Long, maxNumOverlapping: Int, numOverlapping: Int): Long =
windowId * s + (numOverlapping - maxNumOverlapping) * s
/**
* 计算窗口结束时间
*
* @param start 开始时间
* @param w 窗口大小
* @return end
*/
def calculateWindowEnd(start: Long, w: Long): Long = start + w
/**
* 计算最多的窗口重叠个数
* 思路:当前事件时间到所在窗口的结束时间 / 滑动间隔 向上取整,即是窗口个数
*
* @param w 窗口间隔
* @param s 滑动间隔
* @return 窗口个数
*/
def calculateMaxNumOverlapping(w: Long, s: Long): Int = Math.ceil(w.toDouble / s.toDouble).toInt
/**
* 模拟计算某个时间的窗口
*
* @param eventTime 事件时间 毫秒级时间戳
* @param windowDuration 窗口间隔 字符串表达式:"10 seconds" or "10 minutes"
* @param slideDuration 滑动间隔 字符串表达式:"10 seconds" or "10 minutes"
* @return List
*/
def window(eventTime: Long, windowDuration: String, slideDuration: String): List[String] = {
// Format window`s interval by CalendarInterval, e.g. "10 seconds" => "10000"
val windowInterval = CalendarInterval.fromString(s"interval $windowDuration").milliseconds()
// Format slide`s interval by CalendarInterval, e.g. "10 seconds" => "10000"
val slideInterval = CalendarInterval.fromString(s"interval $slideDuration").milliseconds()
if (slideInterval > windowInterval) throw
new RuntimeException(s"The slide duration ($slideInterval) must be less than or equal to the windowDuration ($windowInterval).")
val maxNumOverlapping = calculateMaxNumOverlapping(windowInterval, slideInterval)
val windowId = calculateWindowId(eventTime, slideInterval)
List.tabulate(maxNumOverlapping)(x => {
val start = calculateWindowStart(windowId, slideInterval, maxNumOverlapping, x)
val end = calculateWindowEnd(start, windowInterval)
(start, end)
}).filter(x => x._1 < eventTime && x._2 > eventTime)
.map(x =>
s"[${TARGET_FORMAT.format(new Date(x._1))}, ${TARGET_FORMAT.format(new Date(x._2))}]"
)
}
def main(args: Array[String]): Unit = {
window(1553320704000L, "10 minutes", "2 minutes").foreach(println)
}
}
之前没看找到源码前,一开始没想明白Spark是如何实现的窗口划分。后来按照自己的逻辑实现了一版窗口划分,与源码实现有异曲同工之处,但是还是有不少出入,下面贴一下我的思路,我的思路大体有三步:
1 计算事件时间最近的窗口的开始时间
windowStartTime = timestamp - (timestamp % slideDuration)
默认以0为第一个窗口的开始时间,滑动时间为s
第二个窗口的开始时间:0+s
第三个窗口的开始时间:0+2s
第四个窗口的开始时间:0+3s,第n个窗口的开始时间:(n-1)s
设时间t落在第n个窗口,根据上面的公式,t所在的窗口开始时间为:startTime_n = (n-1)s
再设时间t距离所在窗口开始时间为x,那么窗口开始时间也可以表示为:startTime_n = t-x
由上面两个式子可以得出:
t-x = (n-1)s
n-1 = (t-x)/s
n-1为整数,由上面式子可以得出,x = t % s
所以:startTime_n = t - (t % s)
def calculateWindowStartTime(t: Long, s: Long): Long = t - (t % s)
2 精确计算产生的窗口个数
windowNumber =ceil ((windowDuration - (timestamp % slideDuration)) / slideDuration)
当前事件时间到所在窗口的结束时间 / 滑动间隔 向上取整,即是窗口个数
def calculateWindowNumber(t: Long, w: Long, s: Long): Int = ((w - (t % s) + (s - 1)) / s).toInt
3 划分窗口
计算出最后一个窗口的开始时间,根据窗口跨度可以计算出最后一个窗口,根据窗口个数和滑动间隔,向前可以计算出所有的窗口
List.tabulate(windowNumber)(x => {
val start = windowStartTime - x * slideInterval
val end = start + windowInterval
s"[${TARGET_FORMAT.format(new Date(start))}, ${TARGET_FORMAT.format(new Date(end))}]"
}).reverse
完整代码:
package com.hollysys.spark.structured.usecase
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.unsafe.types.CalendarInterval
/**
* Created by shirukai on 2019-03-23 11:29
* 模拟window()函数实现
*/
object WindowMockFunctionExample {
val TARGET_FORMAT: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
/**
* 计算最近窗口开始时间
* 思路:
* 默认以0为第一个窗口的开始时间,滑动时间为s
* 第二个窗口的开始时间:0+s
* 第三个窗口的开始时间:0+2s
* 第四个窗口的开始时间:0+3s
* ……
* 第n个窗口的开始时间:(n-1)s
*
* 设时间t落在第n个窗口,根据上面的公式,t所在的窗口开始时间为:startTime_n = (n-1)s
* 再设时间t距离所在窗口开始时间为x,那么窗口开始时间也可以表示为:startTime_n = t-x
* t-x = (n-1)s
* n-1 = (t-x)/s
* n-1为整数,由上面式子可以得出,x = t % s
* 所以:startTime_n = t - (t % s)
*
* @param t 事件时间
* @param s 滑动间隔
* @return 窗口开始时间
*/
def calculateWindowStartTime(t: Long, s: Long): Long = t - (t % s)
/**
* 计算窗口个数
* 思路:当前事件时间到所在窗口的结束时间 / 滑动间隔 向上取整,即是窗口个数
* @param w 窗口间隔
* @param s 滑动间隔
* @return 窗口个数
*/
def calculateWindowNumber(t: Long, w: Long, s: Long): Int = ((w - (t % s) + (s - 1)) / s).toInt
/**
* 模拟计算某个时间的窗口
*
* @param eventTime 事件时间 毫秒级时间戳
* @param windowDuration 窗口间隔 字符串表达式:"10 seconds" or "10 minutes"
* @param slideDuration 滑动间隔 字符串表达式:"10 seconds" or "10 minutes"
* @return List
*/
def window(eventTime: Long, windowDuration: String, slideDuration: String): List[String] = {
// Format window`s interval by CalendarInterval, e.g. "10 seconds" => "10000"
val windowInterval = CalendarInterval.fromString(s"interval $windowDuration").milliseconds()
// Format slide`s interval by CalendarInterval, e.g. "10 seconds" => "10000"
val slideInterval = CalendarInterval.fromString(s"interval $slideDuration").milliseconds()
if (slideInterval > windowInterval) throw
new RuntimeException(s"The slide duration ($slideInterval) must be less than or equal to the windowDuration ($windowInterval).")
val windowStartTime = calculateWindowStartTime(eventTime, slideInterval)
val windowNumber = calculateWindowNumber(eventTime,windowInterval, slideInterval)
List.tabulate(windowNumber)(x => {
val start = windowStartTime - x * slideInterval
val end = start + windowInterval
s"[${TARGET_FORMAT.format(new Date(start))}, ${TARGET_FORMAT.format(new Date(end))}]"
}).reverse
}
def main(args: Array[String]): Unit = {
window(1553320704000L, "10 minutes", "3 minutes").foreach(println)
}
}
6 处理延迟数据和水位设置
对于业务中的延迟数据,我们该如何处理呢?同样是wordCount的例子,假如在12:11分时,接收到了12:04分的数据,那么Spark是如何处理的呢?这里为了方便理解,将上面的wordcount例子输出模式改为Update.
val query = count.writeStream
.outputMode(OutputMode.Update())
.format("console")
.option("truncate", value = false)
.start()
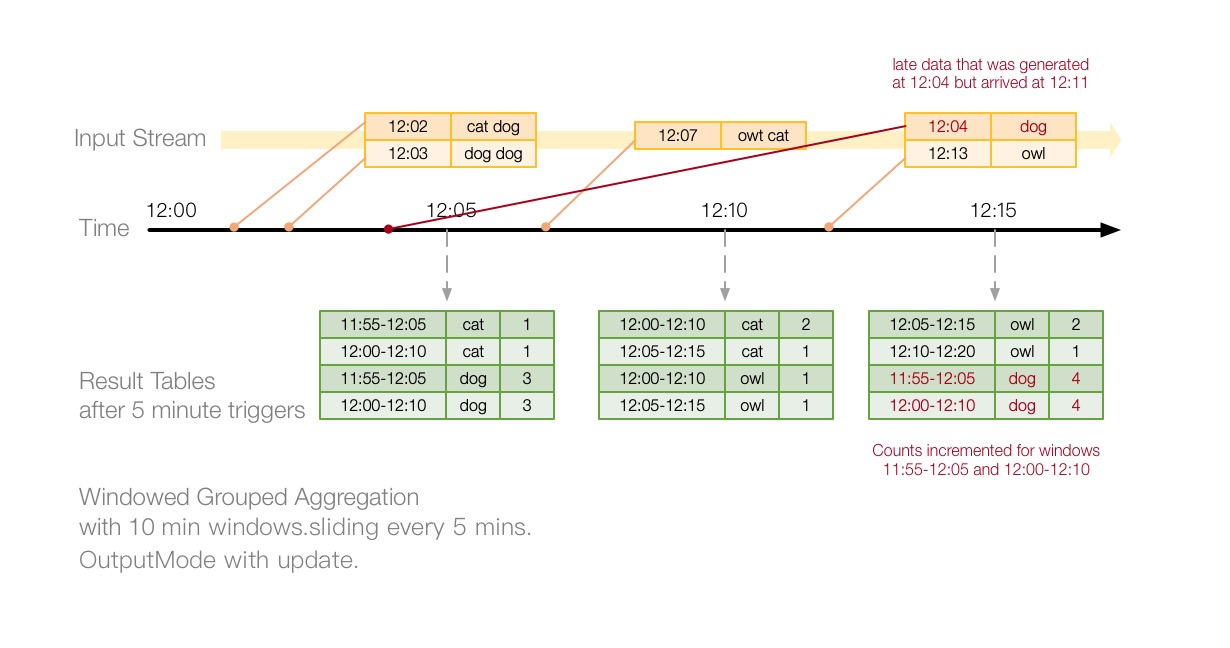
通过上面的图可以看出,Spark会我们保存历史状态,当遇到延迟数据后仍然会根据状态进行计算。但是,如果我们要持续执行这个Query,系统必须限制其积累的内存中间状态的数量。这意味着系统要知道何时可以从内存状态中删除旧聚合,因为应用程序不会再为该聚合接收到较晚的数据。为了实现这一点,在Spark2.1之后,引入了watermark,使得引擎可以自动跟踪数据中的当前事件时间,并尝试相应地清除旧状态。假如我们设置watermark的延迟阈值为10分钟,上一次Trigger中事件最大时间为12:15,那么本次Trigger中,12:05之前的数据将不会被计算。这里我们继续进行代码演示,上面我们修改了之前的wordcount例子的输出模式为update,因为使用complete模式,watermark是不生效的,也就是说complete会一直保存聚合状态。现在我们对程序设置watermark,并进行测试。
.withWatermark("time", "10 minutes")
// Group the data by window and word and compute the count of each group
.groupBy(
window($"time", "10 minutes", "5 minutes"),
$"word"
).count()
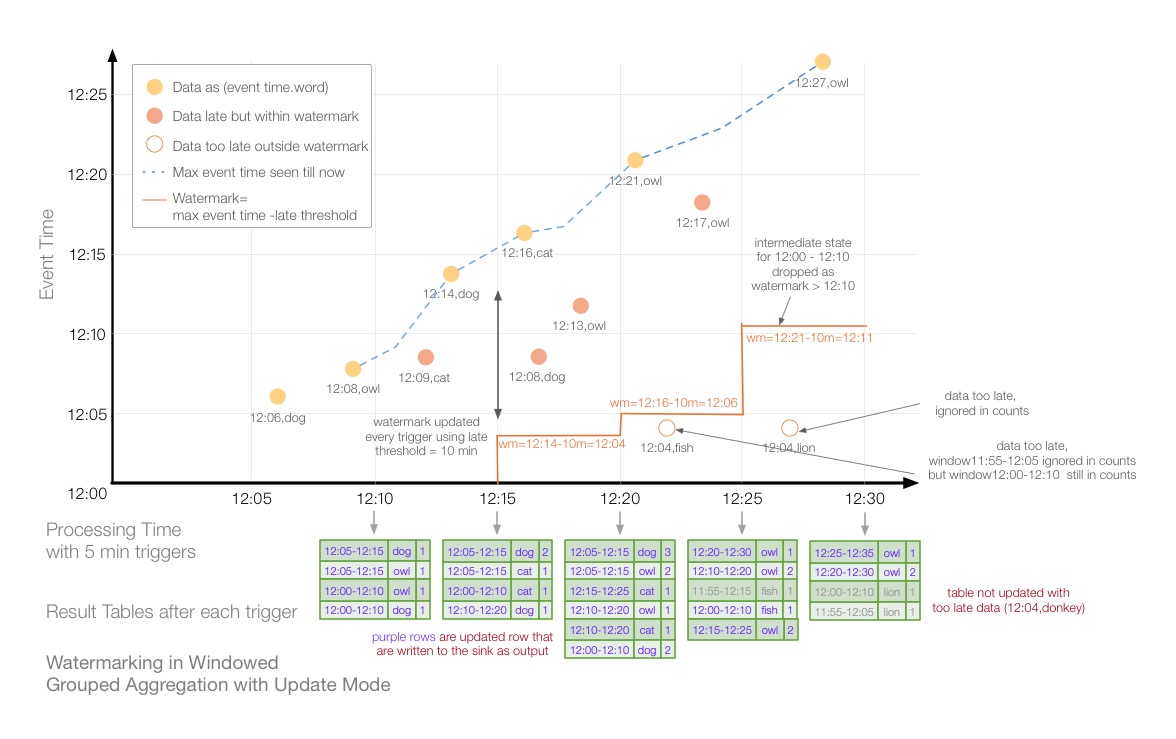
如上图所示为输出模式为Update,窗口时间为10分钟,滑动间隔为5分钟,watermark阈值设置为10分钟的计算过程。X轴表示trigger时间即触发计算的时间,Y轴表示事件时间,即数据产生的时间。蓝色虚线表示最大事件时间,红色时间为watermark时间。在红色线和蓝色虚线之间的数据会被计算,之外的数据所在的部分窗口或者全部窗口将会被丢弃。如12:25时,由于上一次trigger计算的watermark为12:06,表示11:55-12:05之前的窗口将会被丢弃,此时来了一条12:04的延迟数据,所以这条数据在11:55-12:05的窗口会被丢弃,但是在12:00-12:10的窗口仍然会参与计算。同理,12:30时,上一次trigger计算的watermark为12:11,表示12:00-12:10分之前的窗口将会被丢弃,此时来了也一条12:04的延迟数据,因为12:04的数据会落到11:55-12:05和12:00-12:10这两个窗口,都在watermark之前,所以这两个窗口都会被丢弃,该数据不参与计算。下面以Trigger顺序进行分析。
12:05
由于没有数据,此次计算为空。
12:10
此时接收到12:06 dog、12:08 owl 两条数据,最大事件时间为12:08,因为我们设置watermark的delayThreshold=10min分钟,所以计算下一个trigger的watermark=12:08-10min = 11:58,因为程序是从12:00开启的,所以这里Spark认为不会有延迟数据,就没有画出watermark为11:58分的线。
12:15
此时接收到12:14 dog和一条延迟的数据12:09 cat,最大事件时间为12:14,上一次计算的wm为11:58所以没有数据需要被丢弃。计算下一个trigger的watermark=12:14-10min = 12:04。
12:20
此时接收到12:16 cat、延迟数据12:08 dog 、延迟数据12:13 owl,上一次计算的wm为12:04,没有窗口被丢弃。此次最大事件时间为12:16,计算wm=12:16-10min=12:06。
12:25
此时接收到12:21 owl、延迟数据12:17 owl、延迟数据12:04 fish,上一次计算wm=12:06,所以11:55-12:05的窗口数据将会被丢弃。12:04的数据有一个窗口是落在了11:55-12:05,所以这个窗口中间状态将会被丢弃,但是12:04在12:00-12:10的窗口将继续参与计算。计算下一个trigger的wm =12:21-10min=12:11。
12:30
此时接收到12:27 owl、延迟数据12:04 lion,上一次计算的wm为12:11,所以在12:00-12:10之前的窗口中间状态将会被丢弃。12:04数据的窗口都在12:00-12:10之前,所以该条数据所有窗口都不会参与计算,计算下一个trigger的wm=12:27-10min=12:17。
……
代码示例:
package com.hollysys.spark.structured.usecase
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.TimestampType
/**
* Created by shirukai on 2019-03-22 14:17
* Structured Streaming 窗口函数操作例子
* 基于事件时间的wordcount,设置watermark
* socket:nc -lk 9090
*/
object WindowOptionWithWatermarkExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
// Read stream form socket,The data format is: 1553235690:dog cat|1553235691:cat fish
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9090)
.load()
import org.apache.spark.sql.functions._
import spark.implicits._
// Transform socket lines to DataFrame of schema { timestamp: Timestamp, word: String }
val count = lines.as[String].flatMap(line => {
val lineSplits = line.split("[|]")
lineSplits.flatMap(item => {
val itemSplits = item.split(":")
val t = itemSplits(0).toLong
itemSplits(1).split(" ").map(word => (t, word))
})
}).toDF("time", "word")
.select($"time".cast(TimestampType), $"word")
.withWatermark("time", "10 minutes")
// Group the data by window and word and compute the count of each group
.groupBy(
window($"time", "10 minutes", "5 minutes"),
$"word"
).count()
val query = count.writeStream
.outputMode(OutputMode.Update())
.format("console")
.option("truncate", value = false)
.start()
query.awaitTermination()
}
}
/*
输入:1553227560:dog|1553227680:owl
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|dog |1 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|owl |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|owl |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|dog |1 |
+------------------------------------------+----+-----+
输入:1553227740:cat|1553228040:dog
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|dog |2 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|cat |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|cat |1 |
|[2019-03-22 12:10:00, 2019-03-22 12:20:00]|dog |1 |
+------------------------------------------+----+-----+
输入:1553228160:cat|1553227680:dog|1553227980:owl
-------------------------------------------
Batch: 2
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|dog |3 |
|[2019-03-22 12:05:00, 2019-03-22 12:15:00]|owl |2 |
|[2019-03-22 12:15:00, 2019-03-22 12:25:00]|cat |1 |
|[2019-03-22 12:10:00, 2019-03-22 12:20:00]|owl |1 |
|[2019-03-22 12:10:00, 2019-03-22 12:20:00]|cat |1 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|dog |2 |
+------------------------------------------+----+-----+
输入:1553228460:owl|1553227440:fish|1553228220:owl
-------------------------------------------
Batch: 3
-------------------------------------------
+------------------------------------------+------+-----+
|window |word |count|
+------------------------------------------+------+-----+
|[2019-03-22 12:20:00, 2019-03-22 12:30:00]|owl |1 |
|[2019-03-22 12:10:00, 2019-03-22 12:20:00]|owl |2 |
|[2019-03-22 12:00:00, 2019-03-22 12:10:00]|fish |1 |
|[2019-03-22 12:15:00, 2019-03-22 12:25:00]|owl |2 |
+------------------------------------------+------+-----+
输入:1553227440:lion|1553228820:owl
-------------------------------------------
Batch: 4
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-03-22 12:25:00, 2019-03-22 12:35:00]|owl |1 |
|[2019-03-22 12:20:00, 2019-03-22 12:30:00]|owl |2 |
+------------------------------------------+----+-----+
*/
上面讲解了在Update模式下,设置watermark之后,我们的聚合操作对延迟数据的处理。下面,我们来看一下在Append模式下,设置watermark之后,聚合操作是如何作用的?
首先,将上面的代码稍作修改,将输出模式改为Append
val query = count.writeStream
.outputMode(OutputMode.Append())
.format("console")
.option("truncate", value = false)
.start()
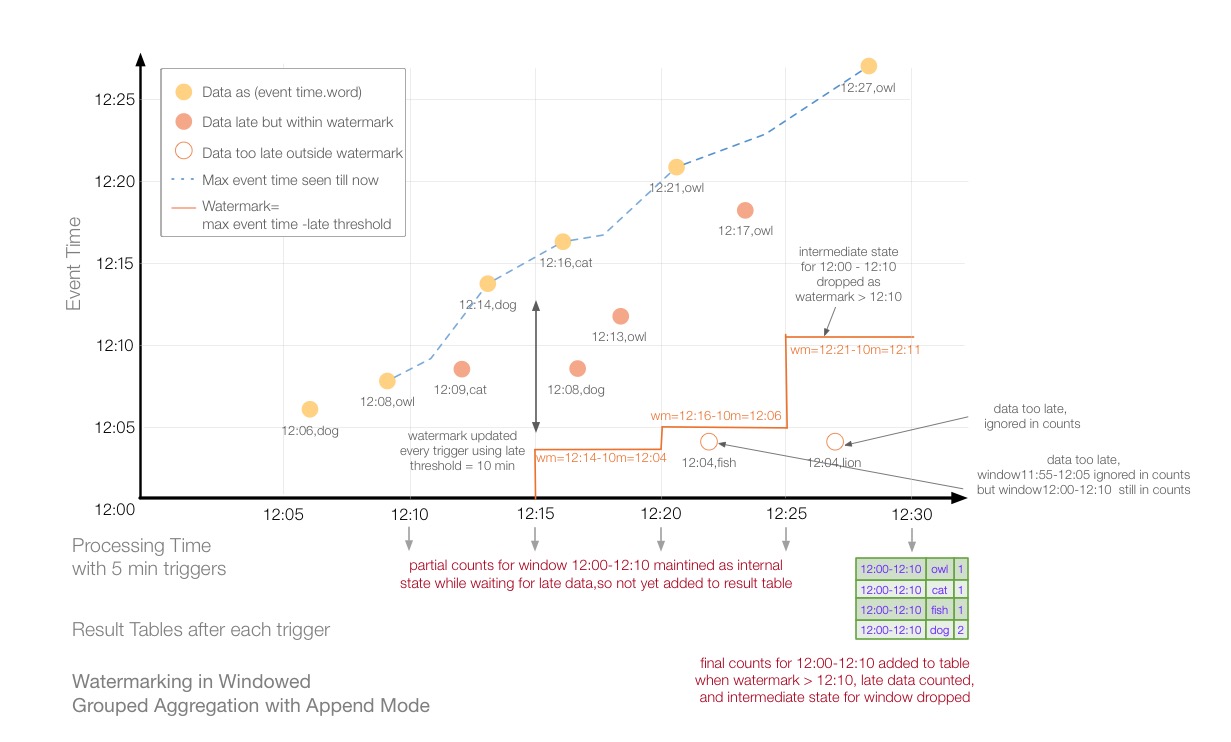
如上图所示为Append模式下,设置watermark的聚合操作。与update模式不同,append模式不会立即输出结果集,而是等到设置的watermark下,再没有数据更新的情况下再输出到结果集。12:00到12:25 这段时间,12:00-12:10这个窗口的数据一直可能被更新,所以没有结果集输出。12:30时的trigger,由于上一个trigger计算的wm=12:11,所以12:00-12:10窗口的数据将会拒之门外,12:04 lion不会参与计算,因此12:00-12:10的窗口,不会被更新,最后12:00-12:10的中间状态将会被输出到结果集,同时中间状态将会被丢弃。
Watermark清理聚合状态的条件需要重点注意,为了清理聚合状态(从Spark2.1.1开始,将来会更改),必须满足以下条件:
A) 输出模式必须是Append或者Update,Complete模式要求保留所有聚合数据,因此不能使用watermark来中断状态。
B) 聚合必须具有时间时间列活事件时间列上的窗口
C) 必须在聚合中使用的时间戳列相同的列上调用withWatermark。例如:df.withWatermark(“time”, “1 min”).groupBy(“time2”).count() 是在Append模式下是无效的,因为watermark定义的列和聚合的列不一致。
D) 必须在聚合之前调用withWatermark 才能使用watermark 细节。例如,在附加输出模式下,df.groupBy(“time”).count().withWatermark(“time”,”1 min”)无效。
7 动态更新参数
在使用StructuredStreaming的时候,我们可能会遇到在不重启Spark应用的情况下动态的更新参数,如:动态更新某个过滤条件、动态更新分区数量、动态更新join的静态数据等。在工作中,遇到了一个应用场景,是实时数据与静态DataFrame去Join,然后做一些处理,但是这个静态DataFrame偶尔会发生变化,要求在不重启Spark应用的前提下去动态更新。目前总结了两种解决方案,详细可以阅读我的《StructuredStreaming动态更新参数》这篇文章。
8 有状态计算函数
为保证多个Batch之间能够进行有状态的计算,SparkStreaming在1.6版本之前就引入了updateStateByKey的状态管理机制,在1.6之后又引入了mapWithState的状态管理机制。StructuredStreaming原本就是有状态的计算,这里我主要记录一下在StructuredStreaming里可以自定义状态操作的算子。详细内容可以阅读我的《StructuredStreaming有状态聚合》这篇文章。
